Visual Documentation Gallery¶
All 278 figures generated for the Music Attribution Scaffold documentation. Each figure provides a visual explanation of architecture decisions, implementation patterns, and design choices.
Figures generated with Nano Banana Pro (Google Gemini image generation). Figure plans in
docs/figures/repo-figures/figure-plans/.
Repository Overview¶
The repository overview figures provide the first orientation for newcomers -- covering the project hero, pipeline architecture, directory layout, technology stack, quickstart flow, developer tooling, quality gates, CI/CD, Docker infrastructure, testing, frontend/backend connection, and security considerations including MCP threat models and protocol landscape.
31 figures -- click to expand
 *What This Repo Does: from broken metadata to transparent attribution -- the hero overview contrasting fragmented music metadata with the unified attribution scaffold.* --- 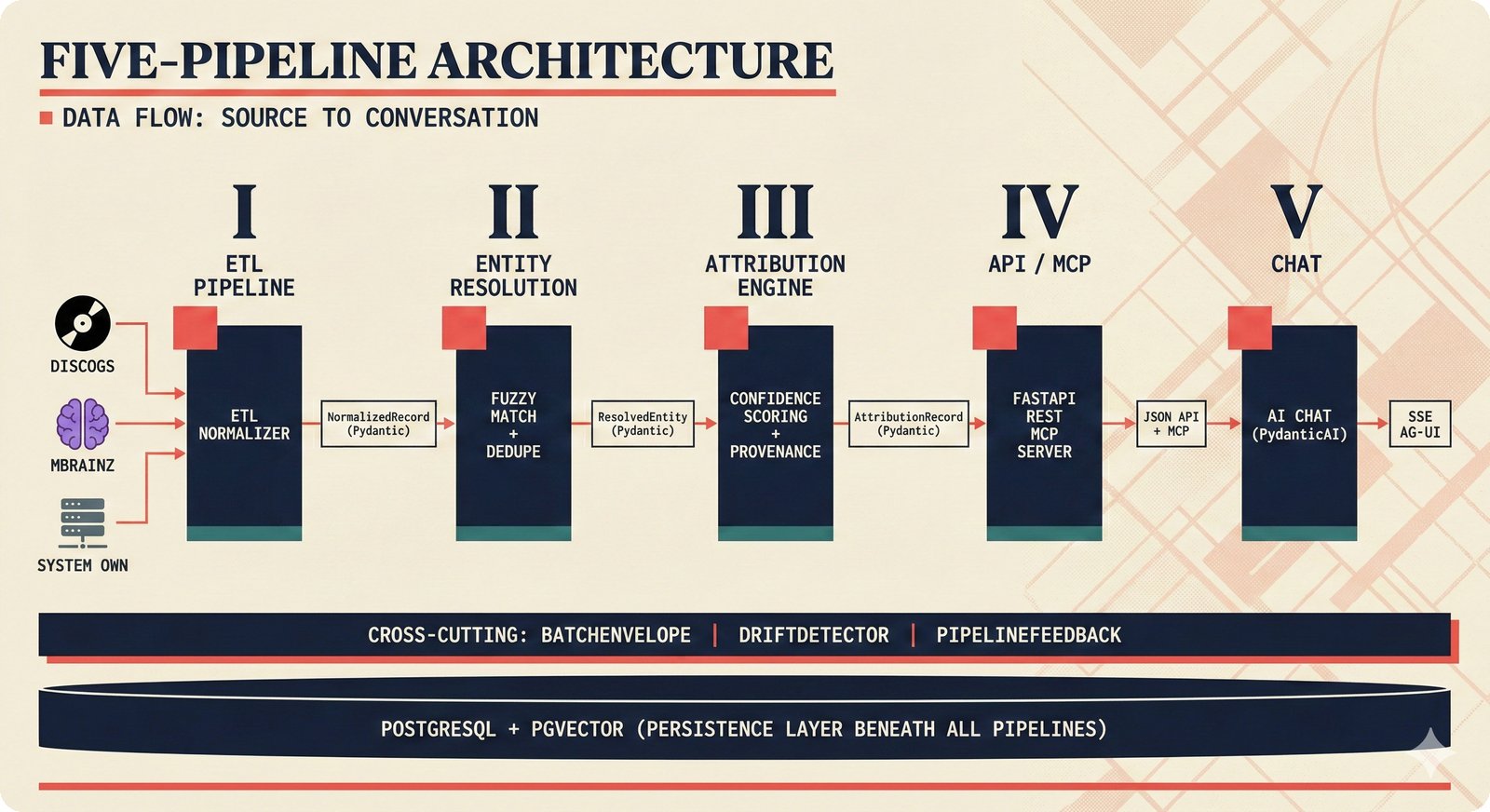 *Five-pipeline architecture: ETL, entity resolution, attribution engine, API/MCP server, and chat agent connected by Pydantic boundary objects.* --- 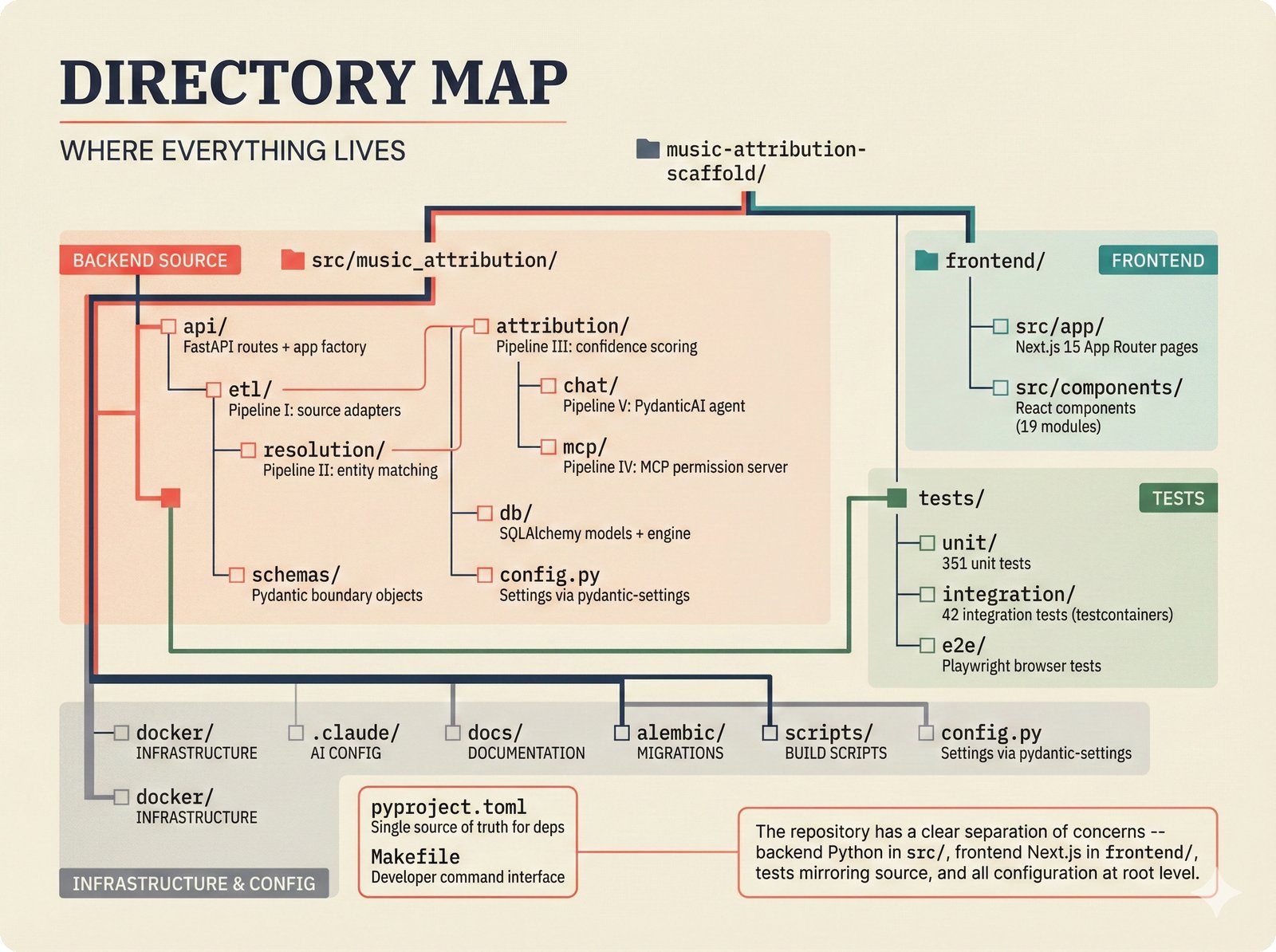 *Annotated directory tree showing the project structure with five pipeline modules, frontend, tests, and infrastructure.* --- 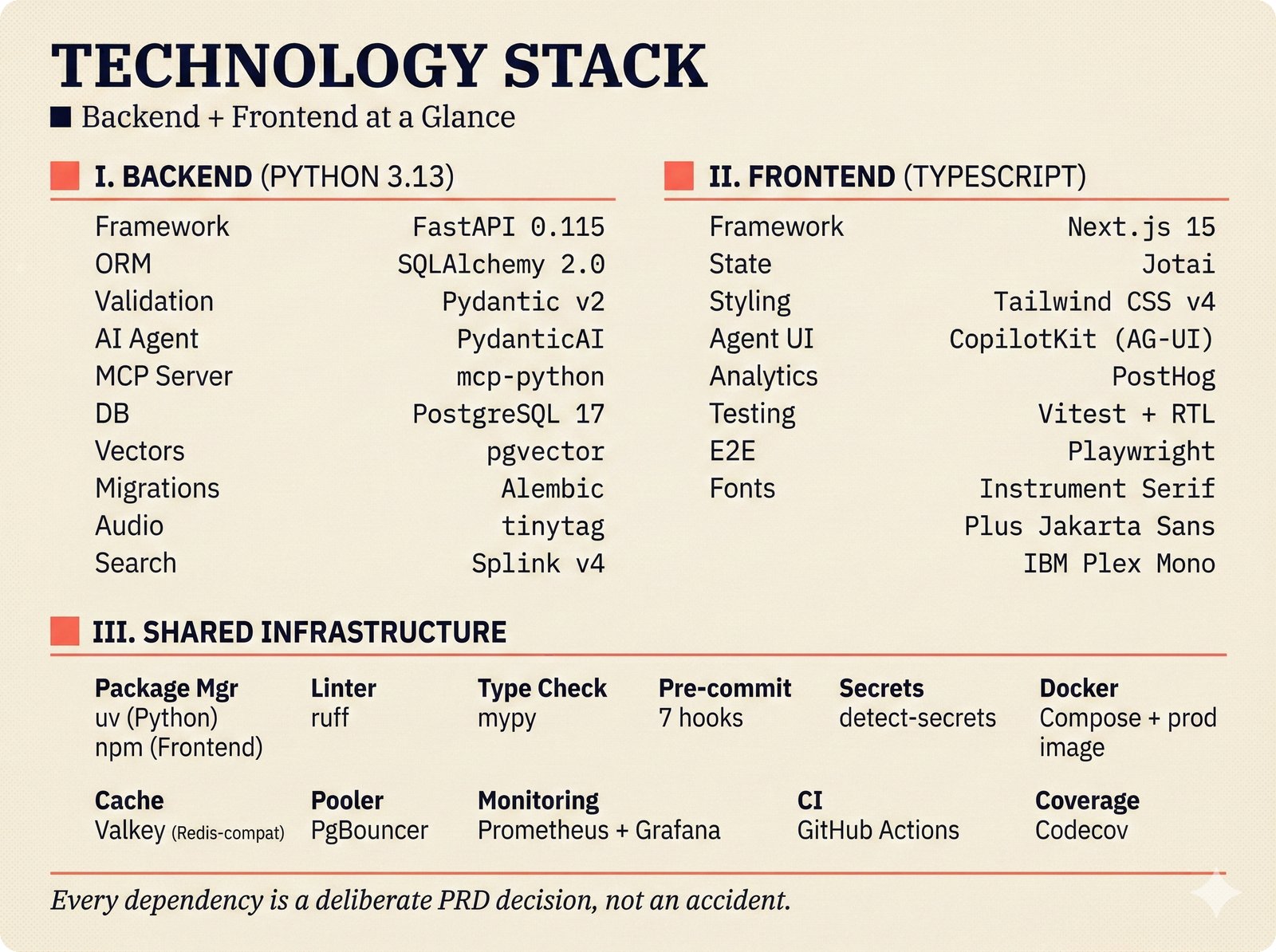 *Full technology stack: Python 3.13 backend, Next.js 15 frontend, PostgreSQL with pgvector, and every dependency a deliberate PRD decision.* ---  *Four-step quickstart: clone, install with uv, start Docker Compose, verify with 658 tests -- a five-minute path to running locally.* --- 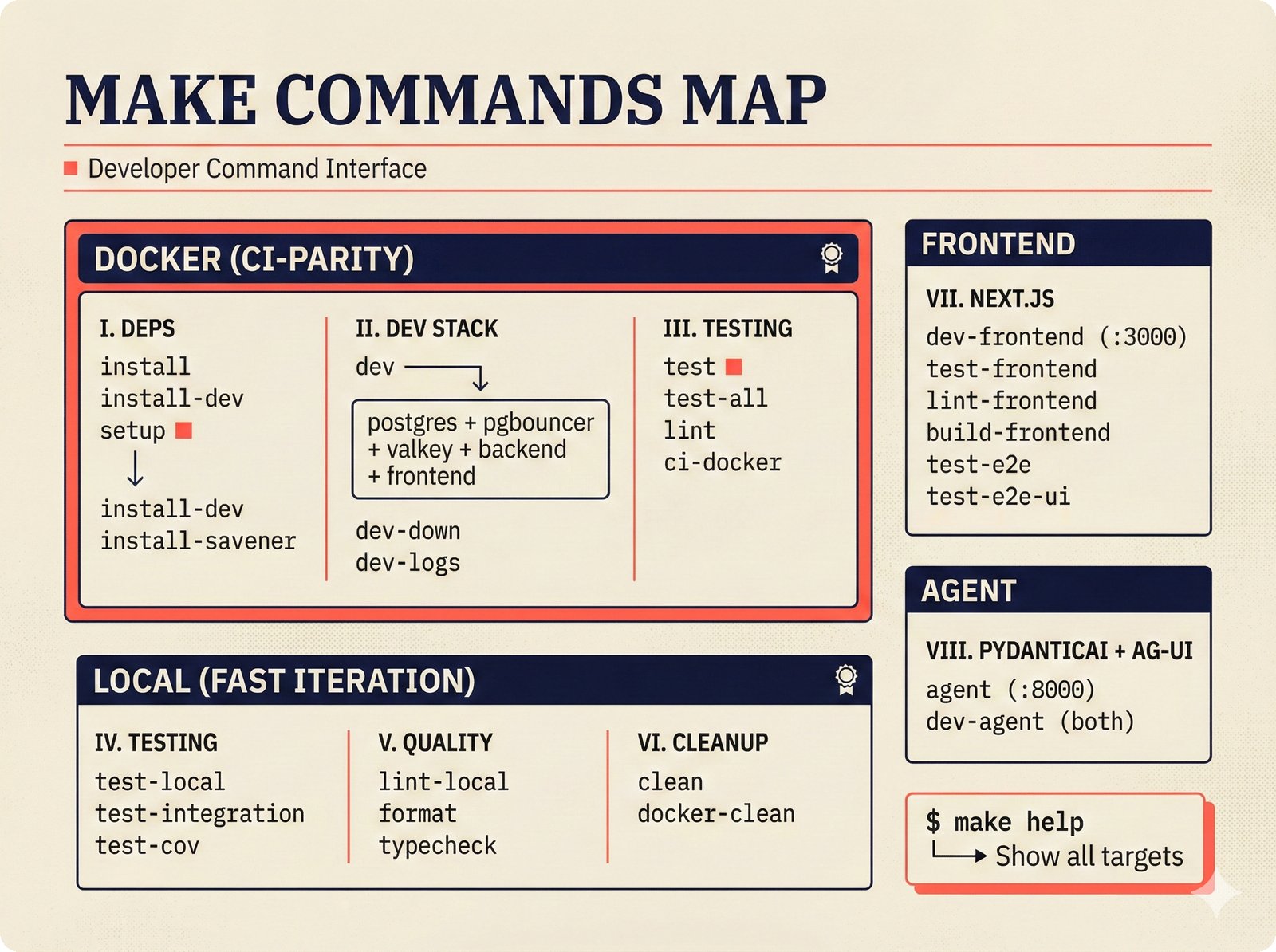 *Makefile command map: eight categories covering dependency management, testing, linting, frontend, and agent workflows.* --- 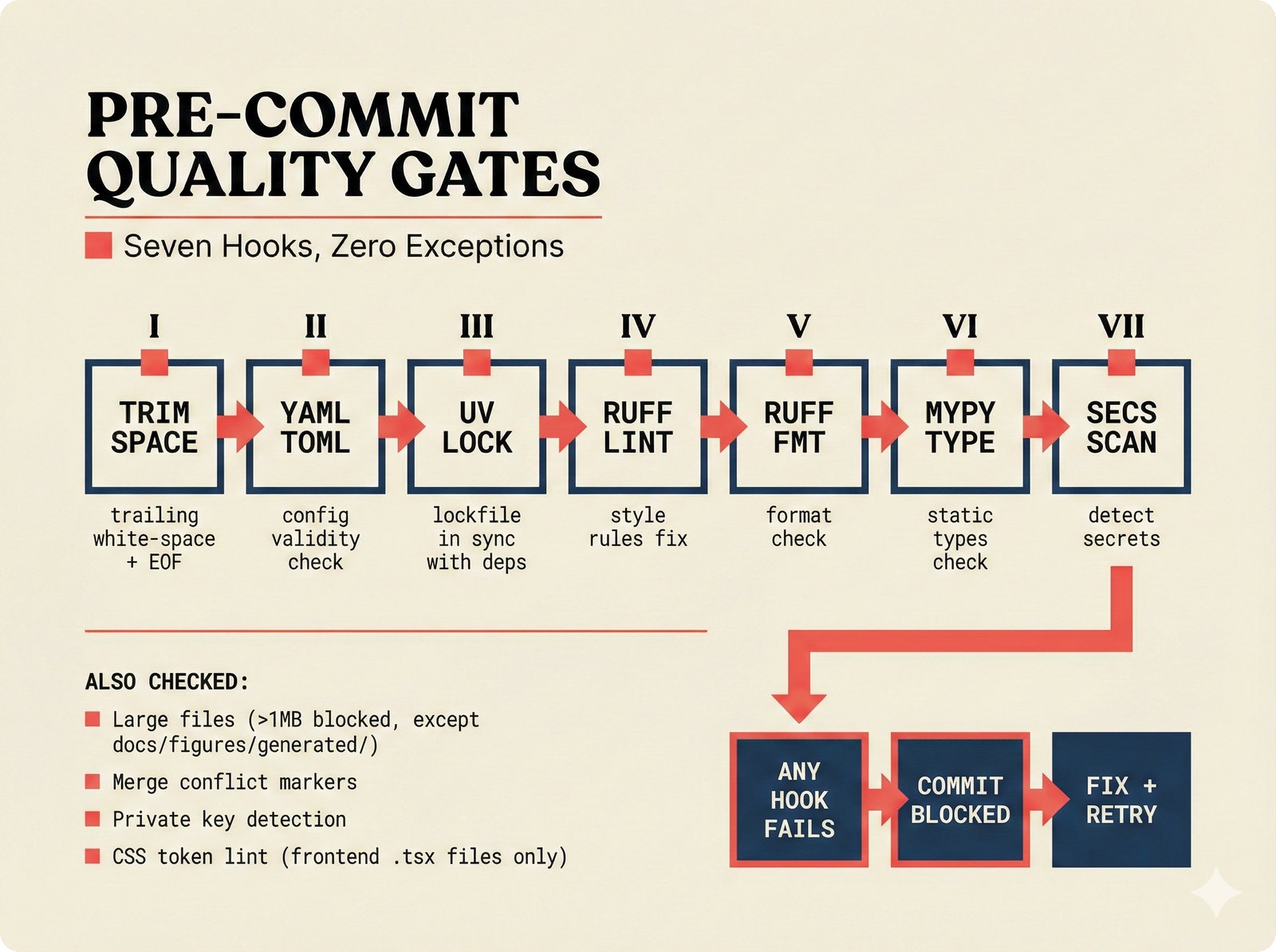 *Seven pre-commit quality gates: any hook failure blocks the commit, enforcing zero-exception code quality.* --- 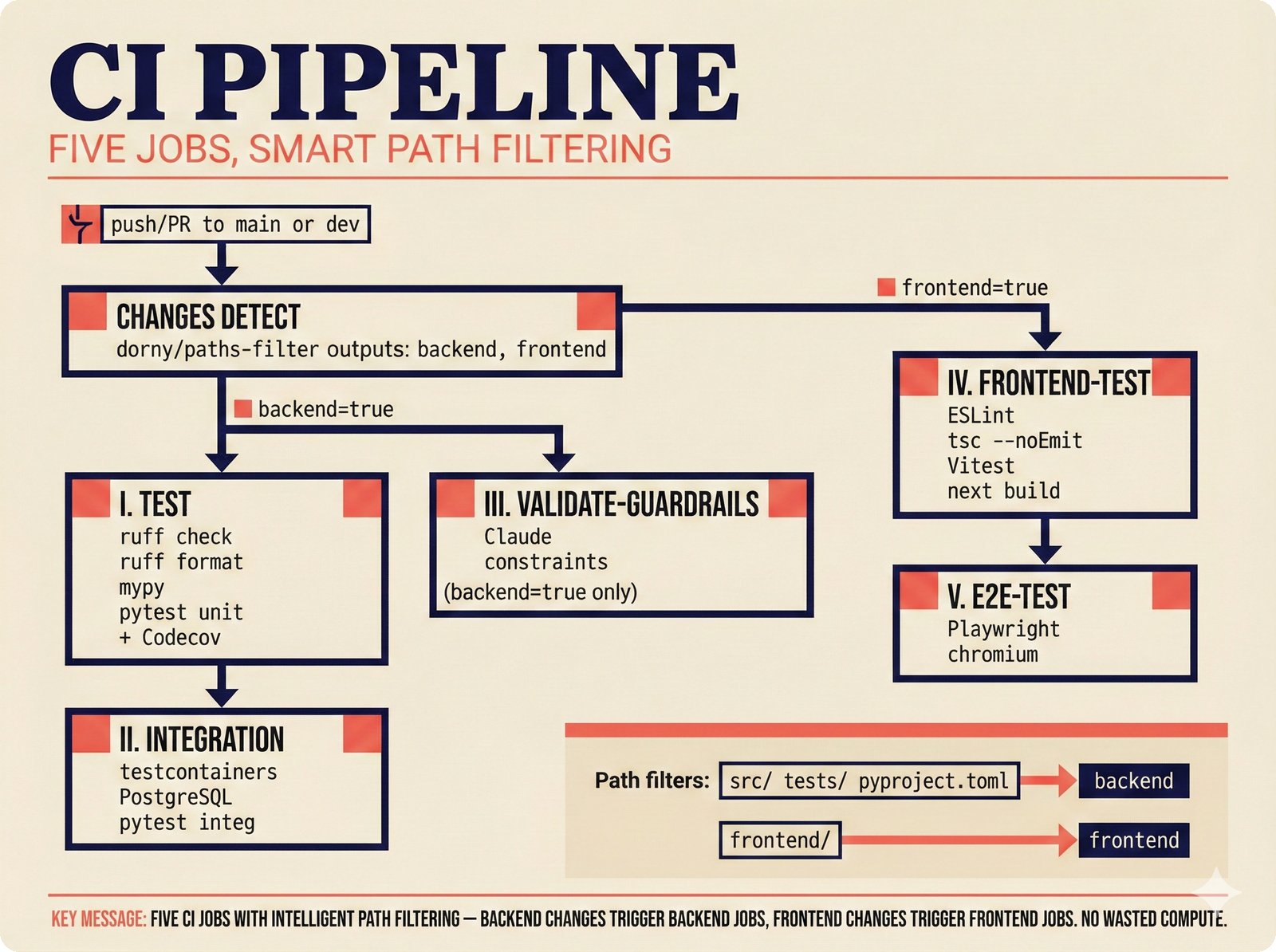 *GitHub Actions CI/CD pipeline with path-based filtering: backend lint, type check, pytest with Codecov, integration tests, frontend Vitest, and Playwright E2E.* --- 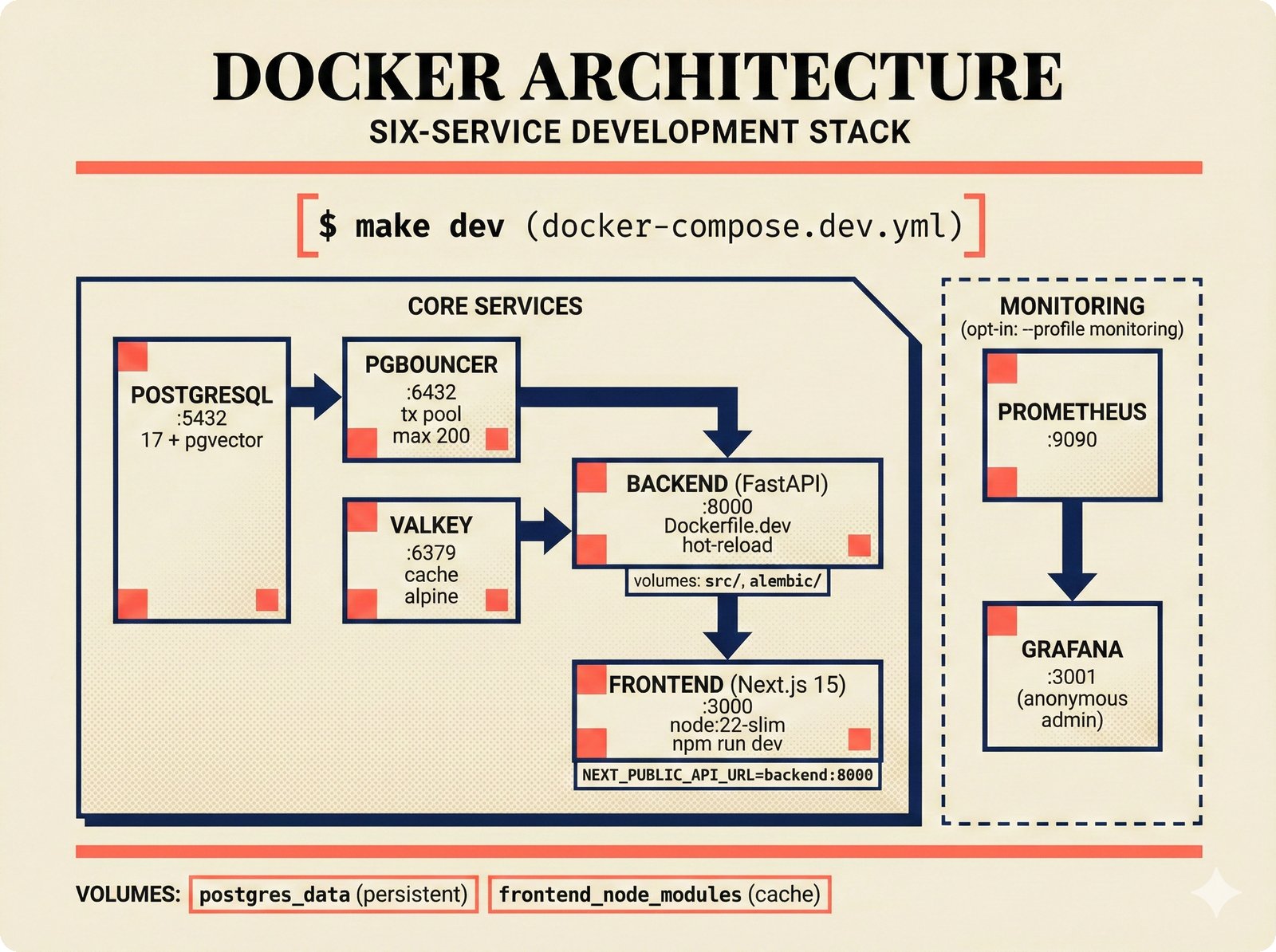 *Docker Compose six-service stack: PostgreSQL 17, PgBouncer, Valkey, FastAPI, Next.js, and optional Prometheus/Grafana monitoring.* --- 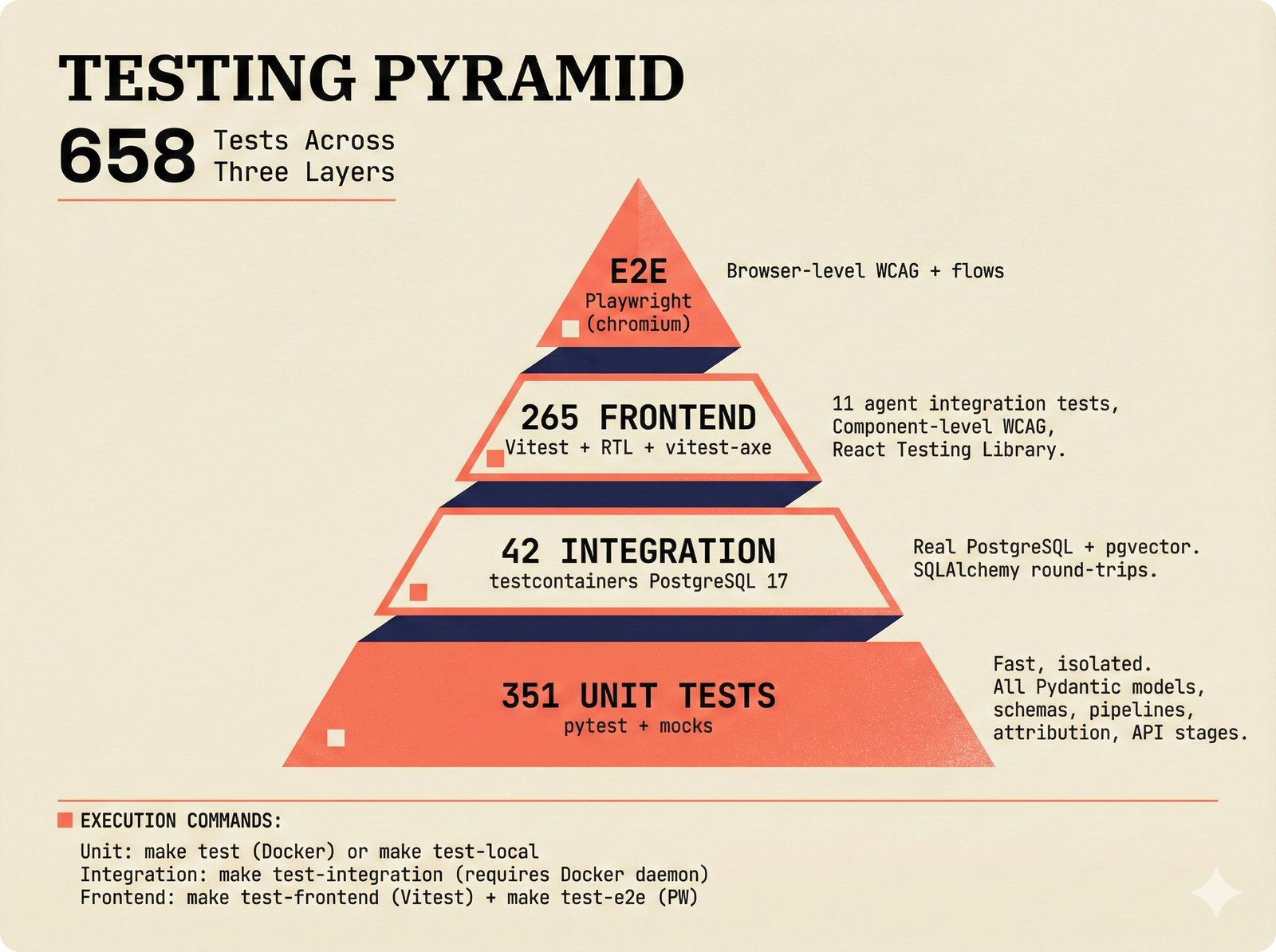 *Testing pyramid: 351 unit tests, 42 integration tests, 265 Vitest frontend tests, and Playwright E2E at the tip.* --- 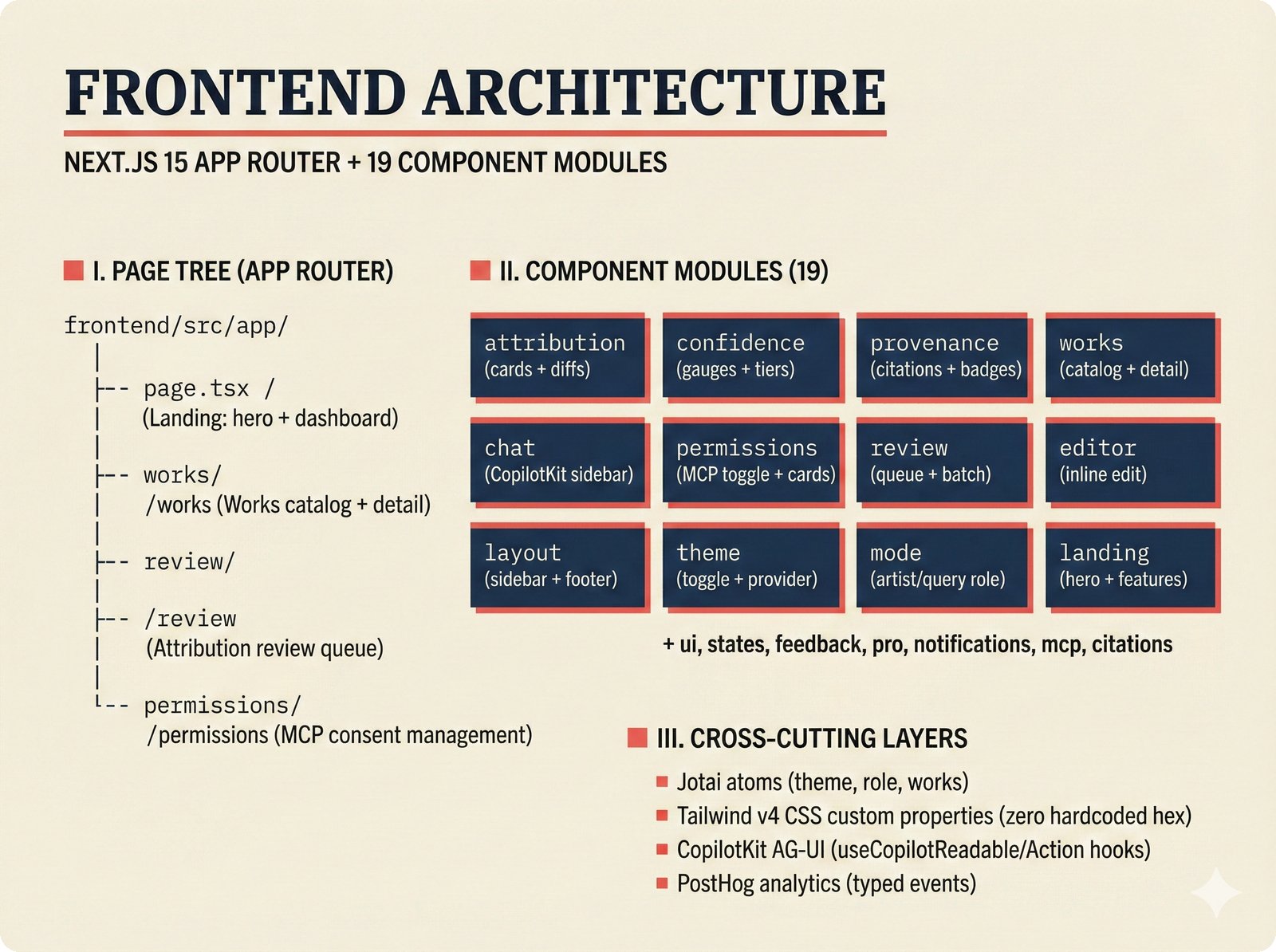 *Frontend architecture: Next.js 15 App Router with four routes, 19 component modules, Jotai state, and CopilotKit agent integration.* --- 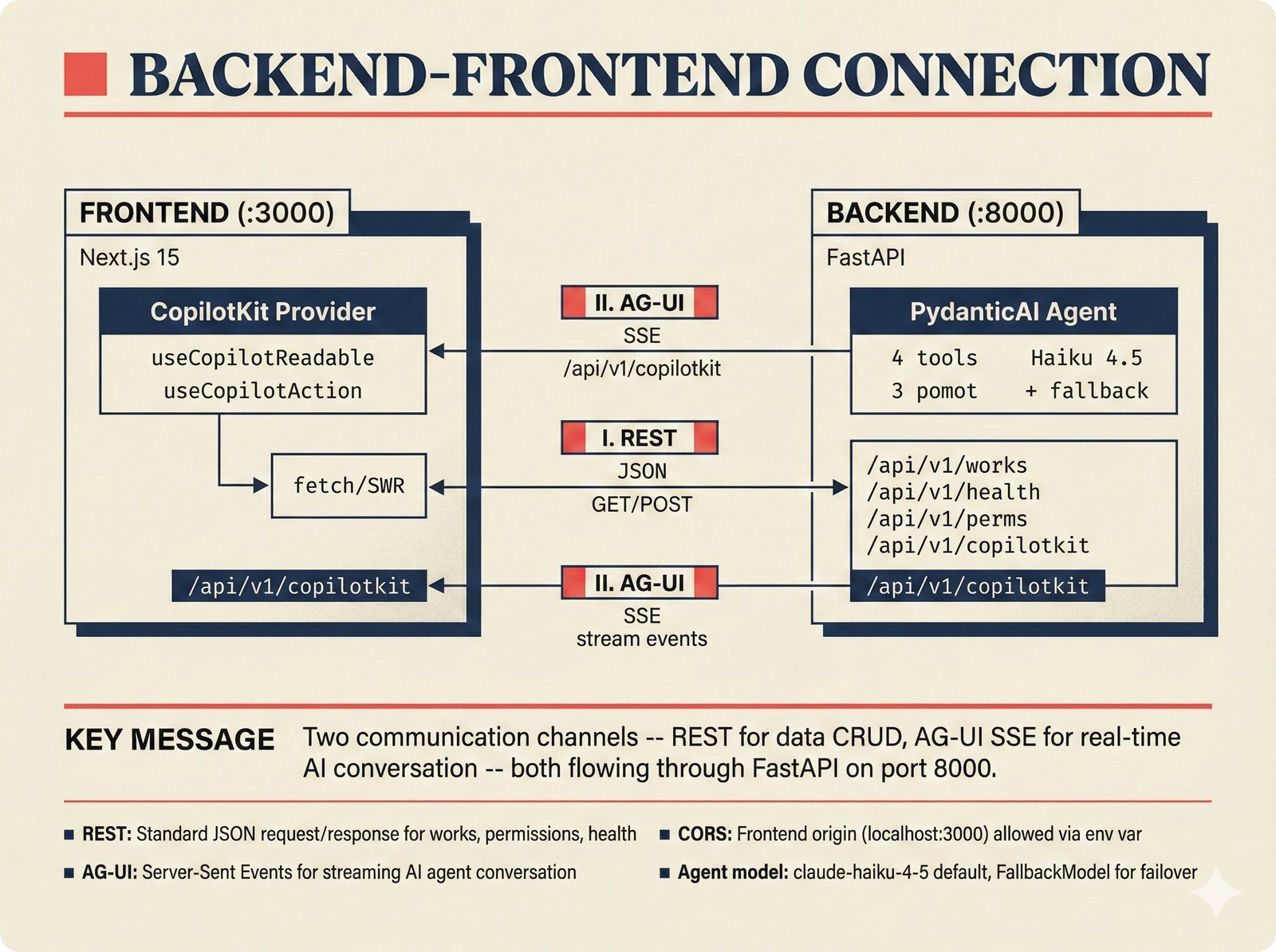 *Backend-frontend connection: REST JSON for CRUD operations and AG-UI SSE for real-time agent conversations.* --- 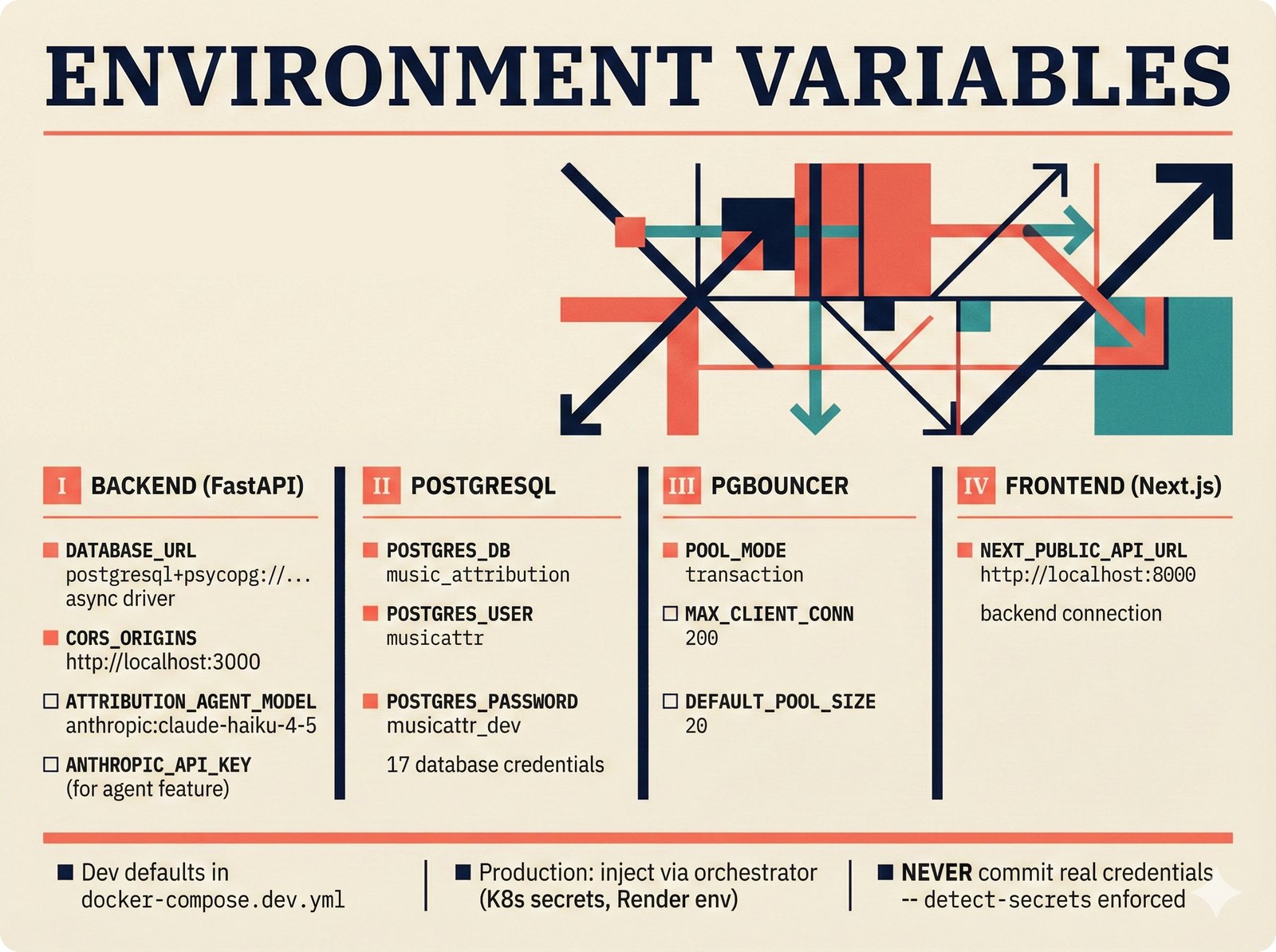 *Environment variables: FastAPI backend, PostgreSQL, PgBouncer, and Next.js frontend following 12-factor app principles.* ---  *Database schema: Works with ISRC/ISWC, Artists with ISNI, Attribution Records with per-field confidence, and MCP Permissions.* --- 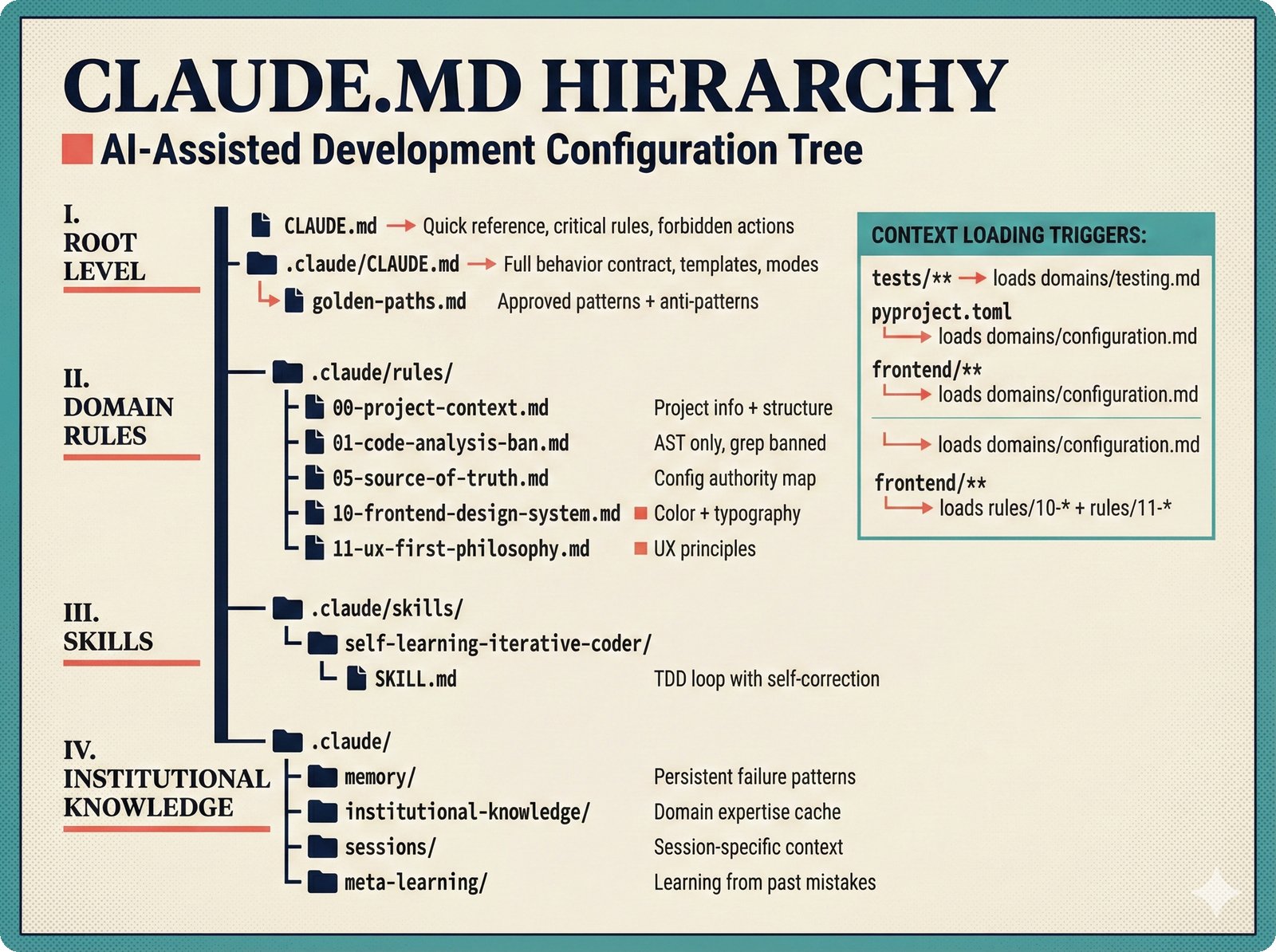 *CLAUDE.md hierarchy: root behavior contract, five domain rules, TDD skill workflows, and file-pattern context loading triggers.* --- 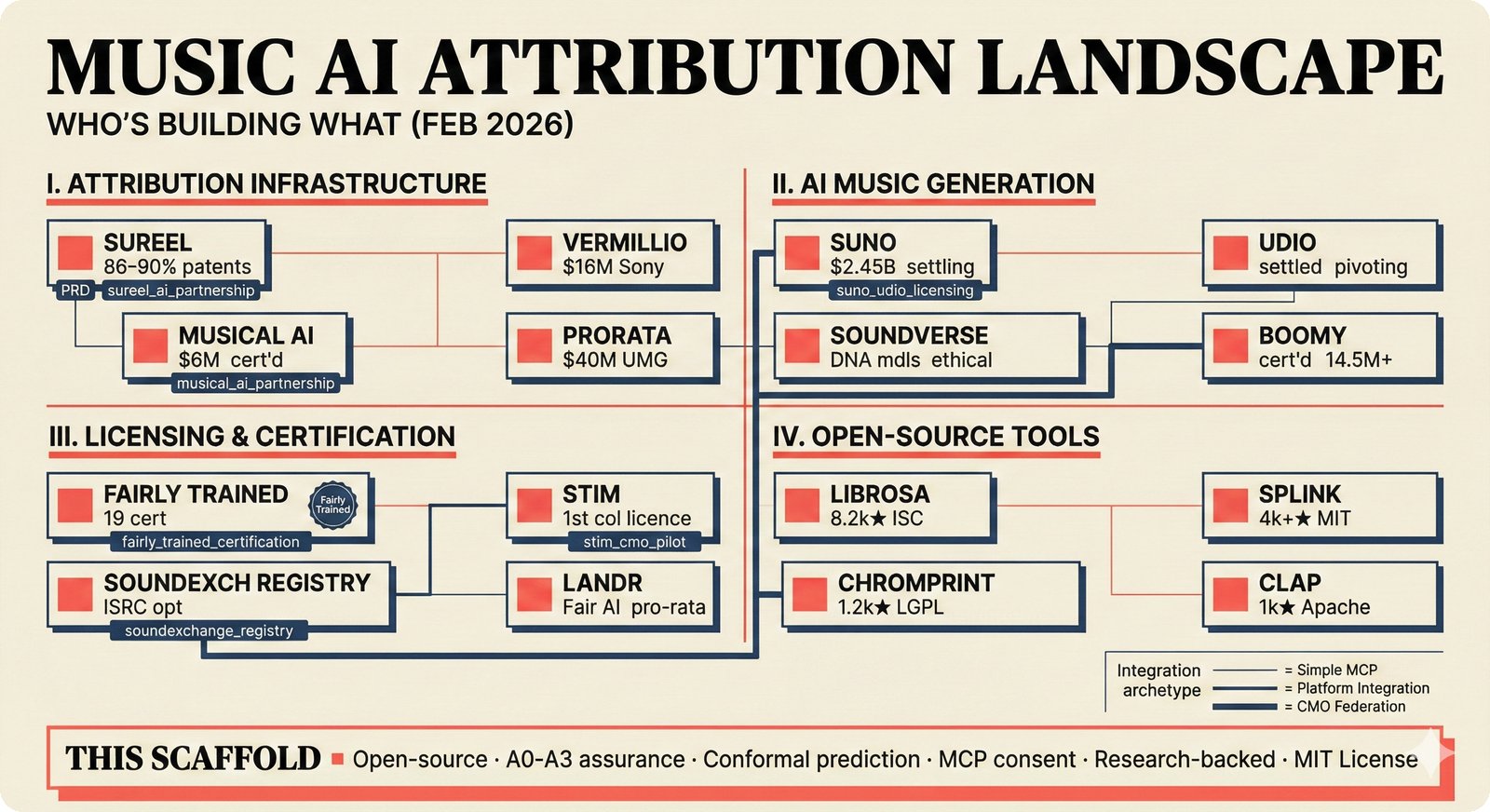 *Landscape overview: four-quadrant map with PRD v3.0.0 company nodes, integration archetypes, and ecosystem positioning.* --- 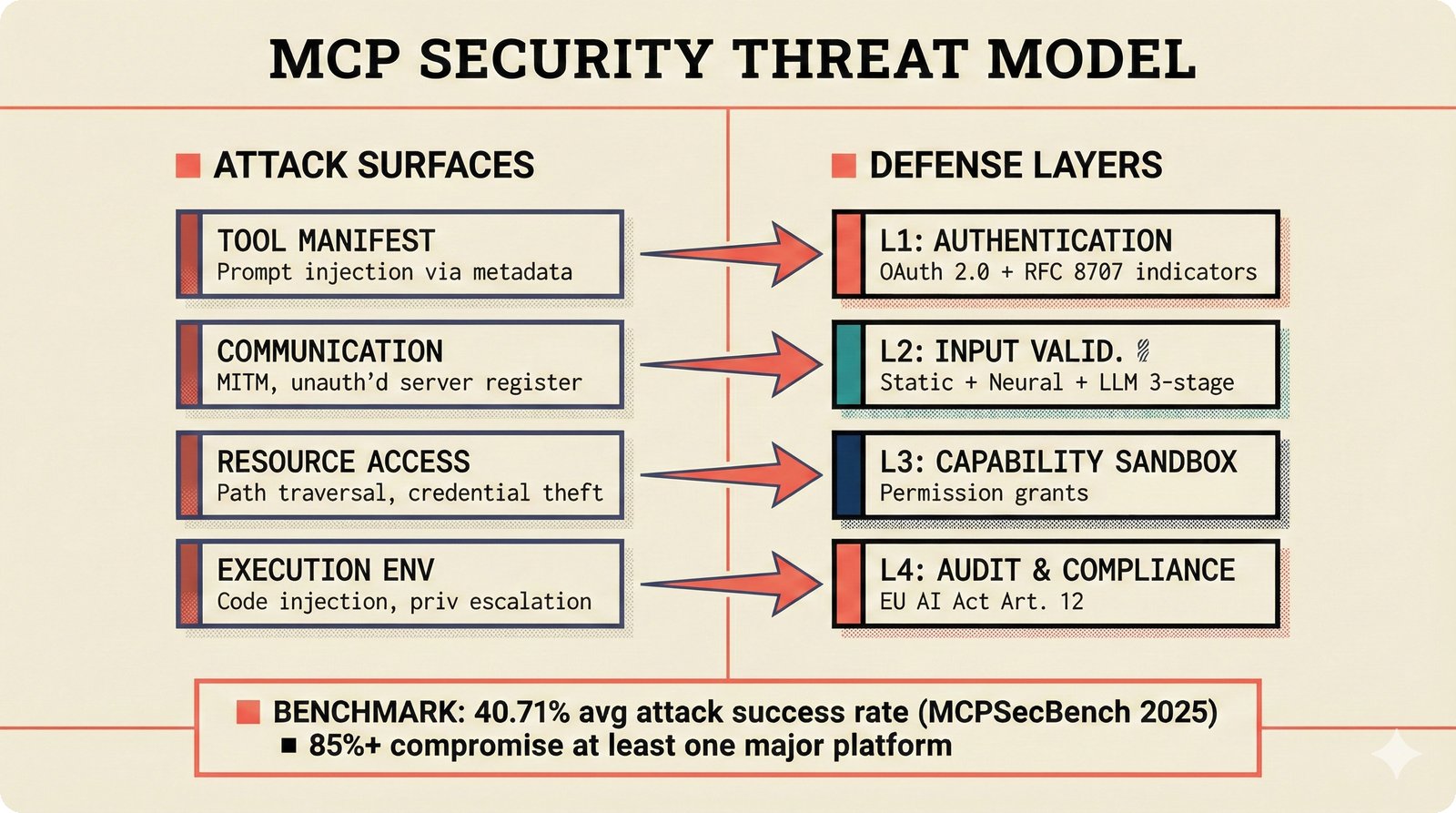 *MCP security threat model: tool manifest, communication, resource access, and execution attack surfaces against four defense layers.* --- 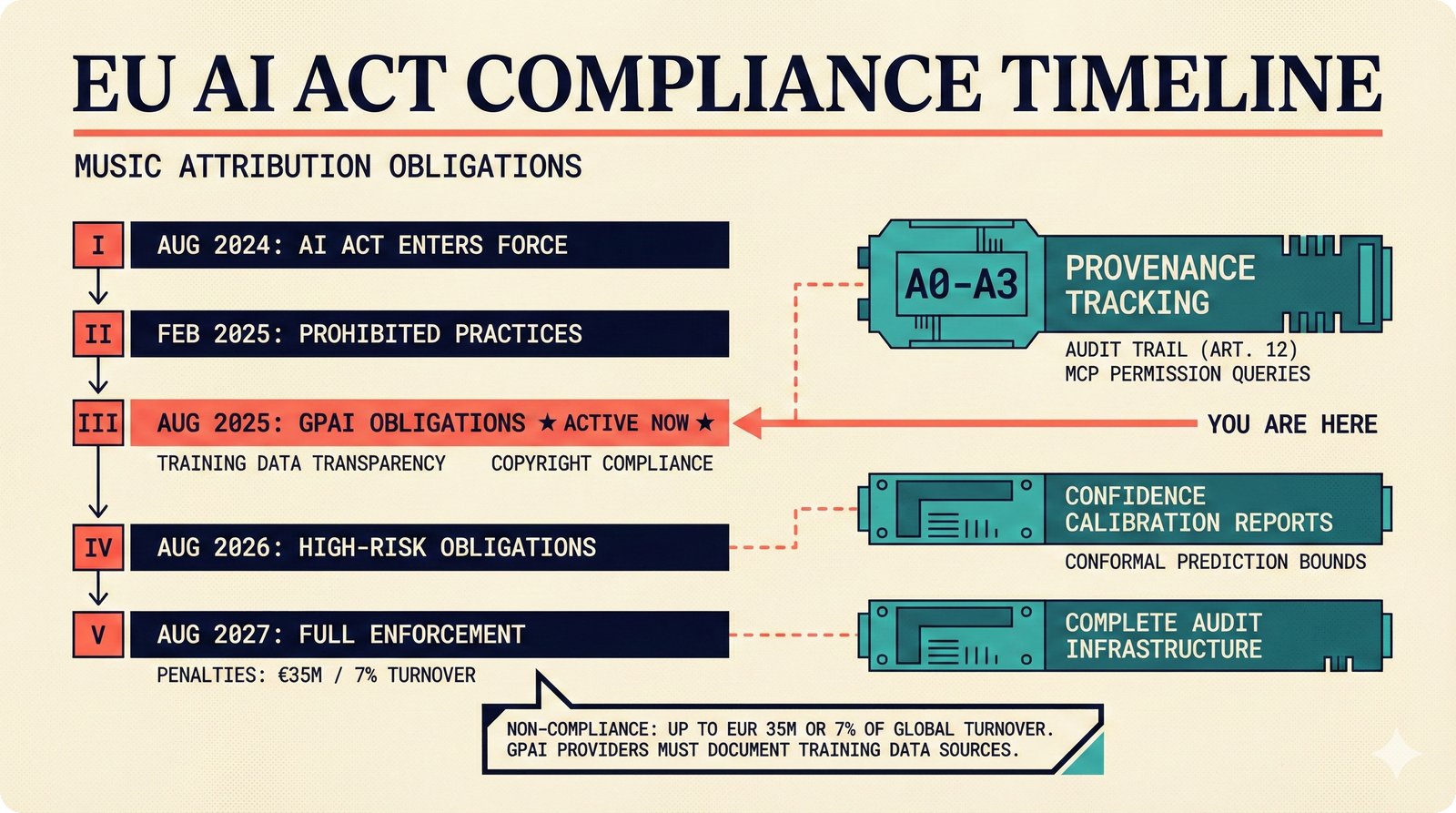 *EU AI Act timeline: entry into force through full enforcement, highlighting GPAI transparency obligations and A0-A3 compliance.* --- 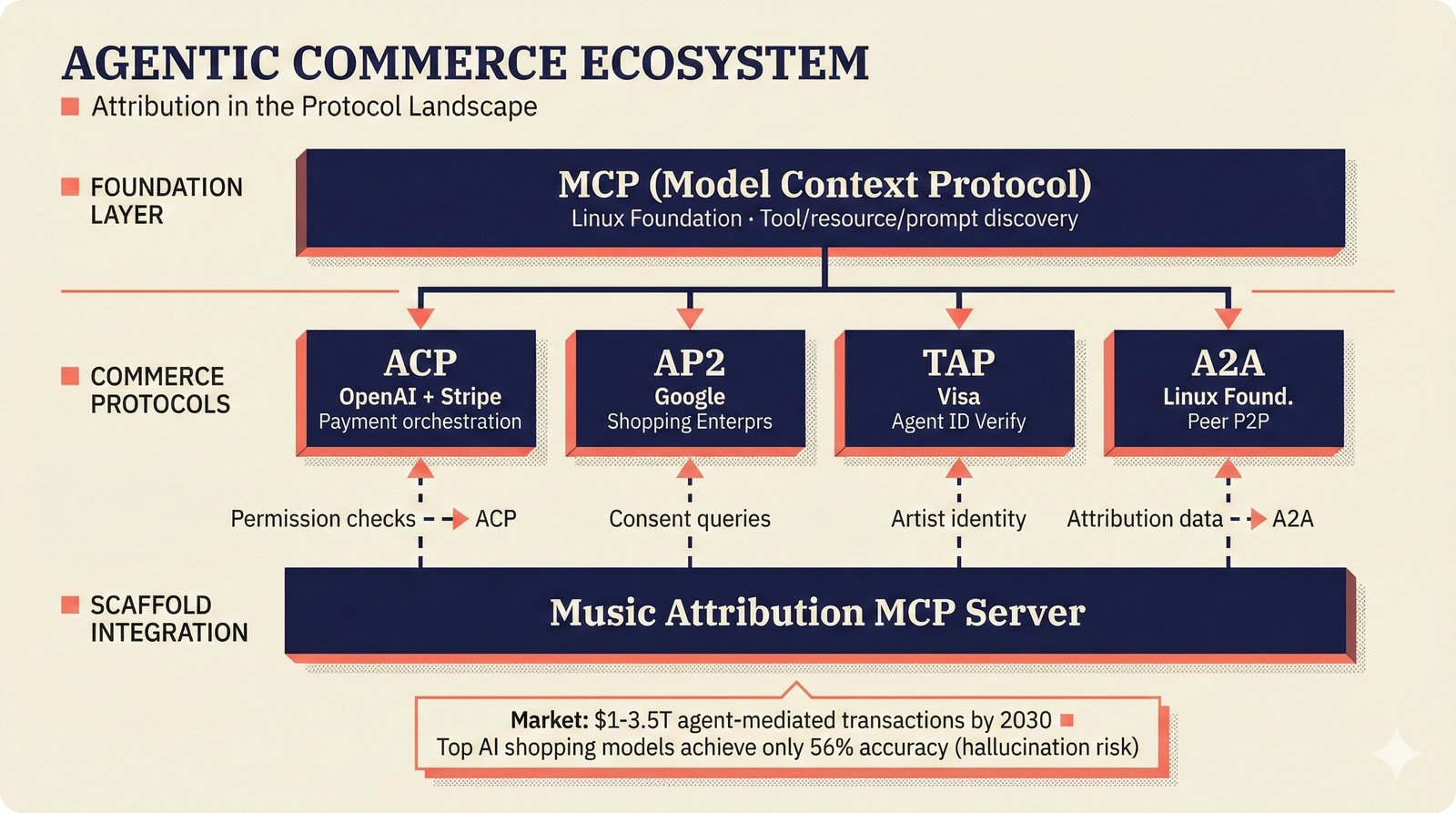 *Agentic commerce ecosystem: MCP foundation, ACP/AP2/TAP/A2A transaction layer, and the music attribution MCP server.* --- 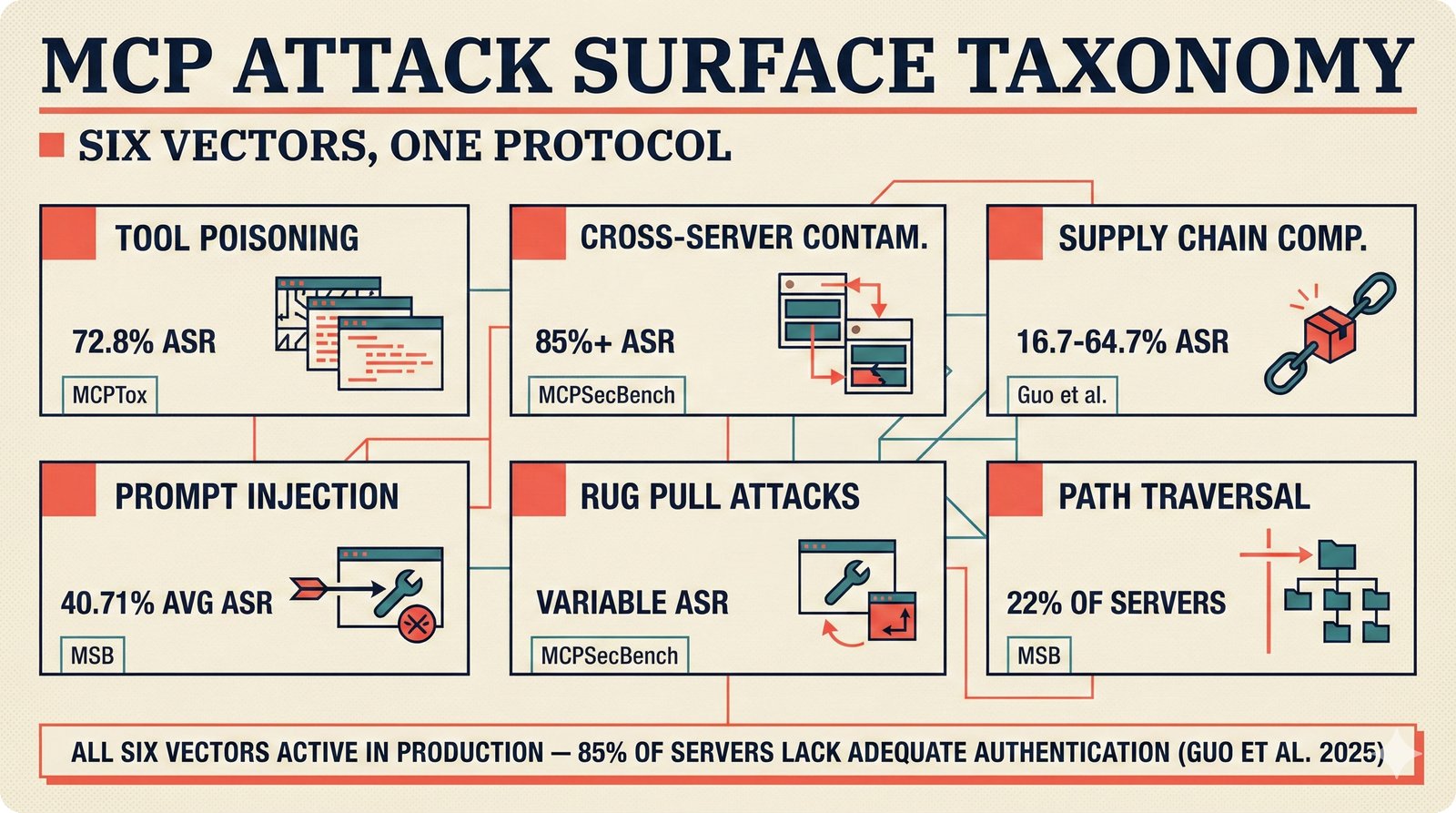 *MCP attack taxonomy: tool poisoning at 72.8%, cross-server contamination at 85%+, supply chain compromise, prompt injection, rug pulls, and path traversal.* --- 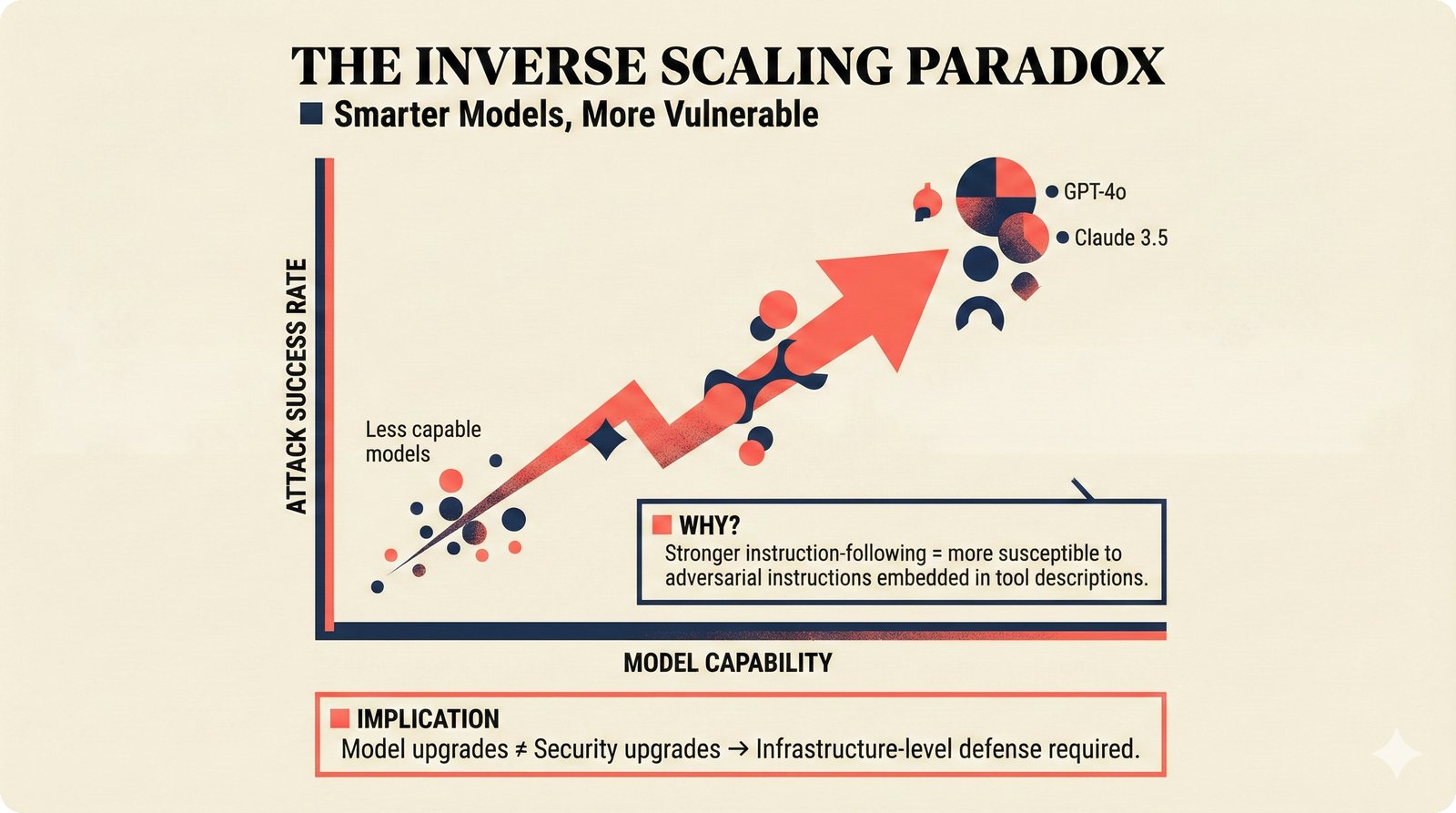 *Inverse scaling paradox: more capable AI models are more vulnerable to MCP attacks due to stronger instruction-following.* ---  *MCP-Guard three-stage defense: static scanner under 2ms, neural classifier, and LLM arbiter achieving 12x speedup.* --- 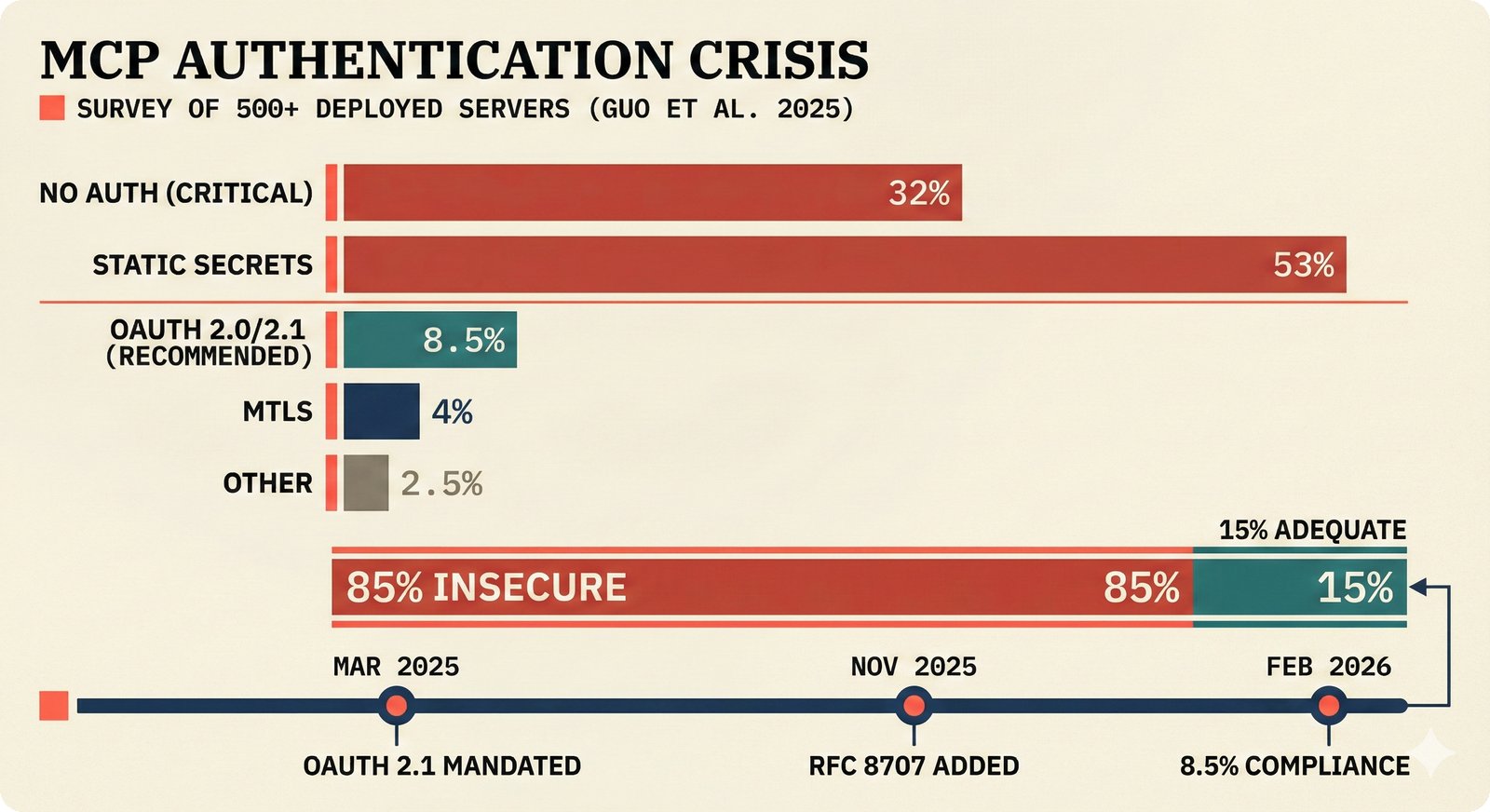 *MCP authentication crisis: 85% of 500+ deployed servers are insecure -- 32% with no authentication, 53% with static secrets.* ---  *Protocol landscape: XAA identity from Okta, A2A coordination from Google, MCP tools from Anthropic, plus ACP and TAP verticals.* --- 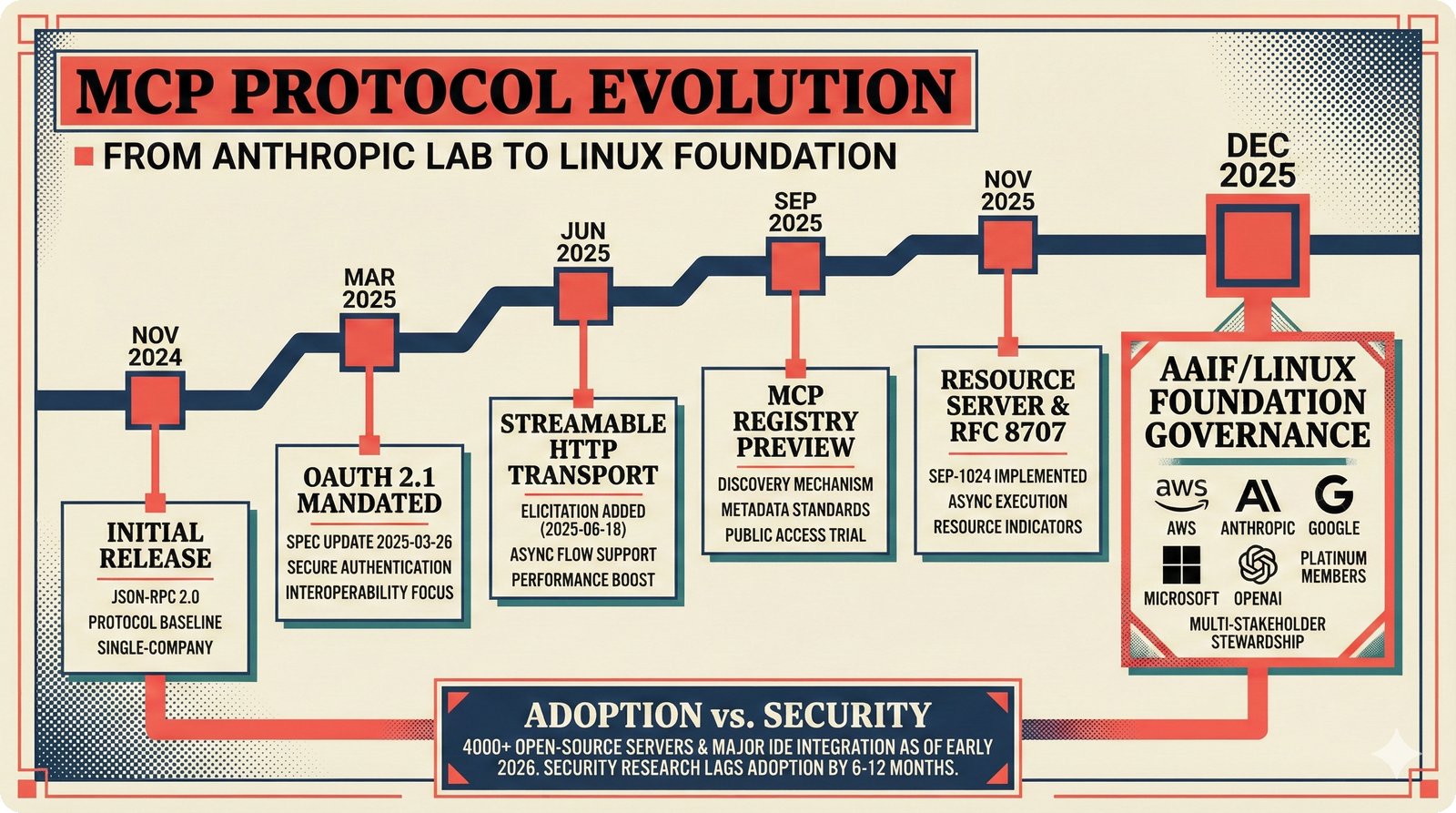 *MCP evolution timeline: initial release through OAuth 2.1 mandate, streamable HTTP, registry preview, to AAIF governance.* --- 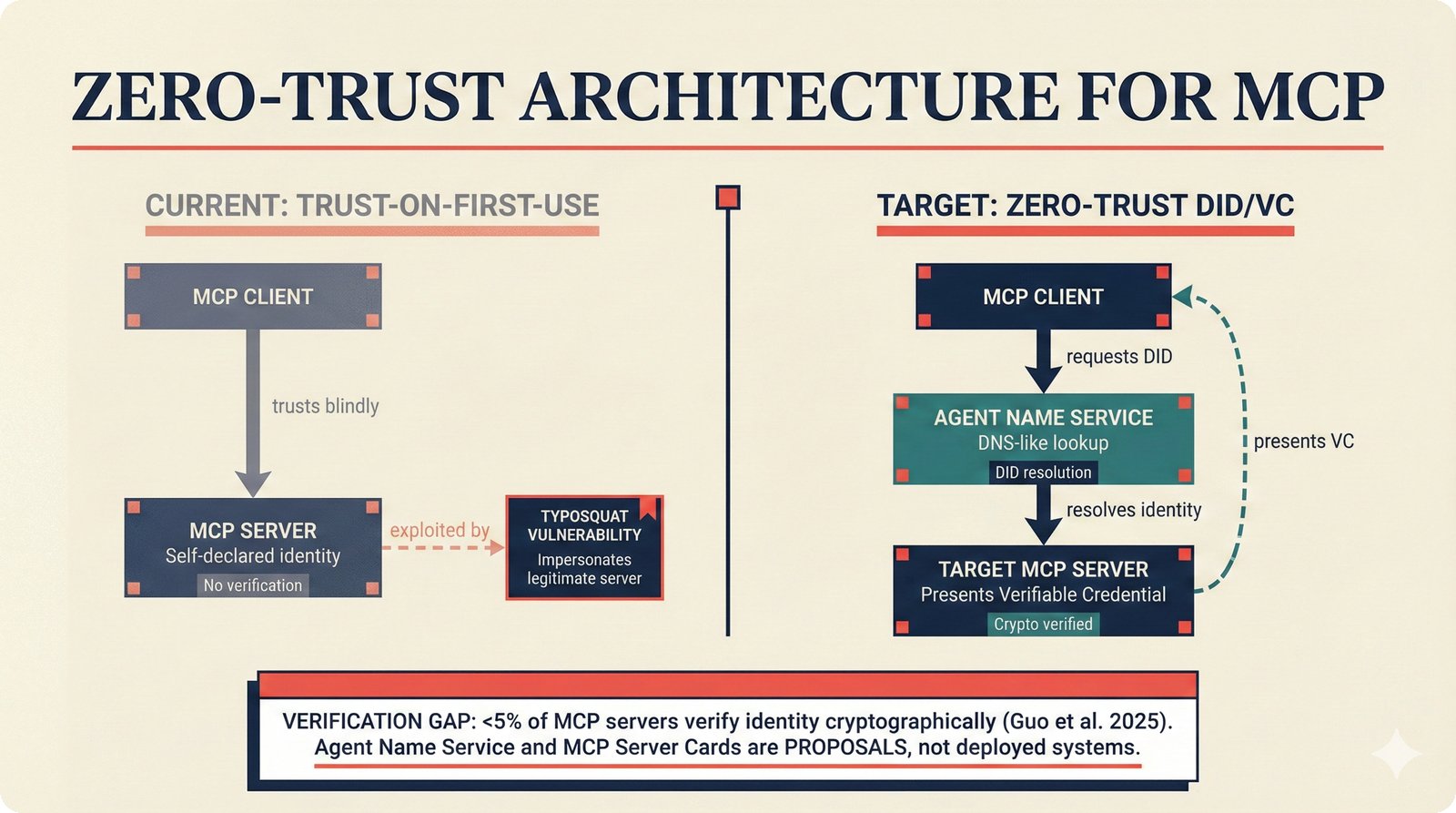 *Zero-trust MCP: current TOFU model versus target architecture with Decentralized Identifiers and Agent Name Service.* ---  *MCP CVE gallery: Figma SSRF (CVSS 7.5), mcp-remote RCE (558K+ downloads), and Git MCP command injection.* ---  *Sandbox isolation patterns: V8 isolates, Docker containers, and Deno sandbox -- Docker recommended for the scaffold.* ---  *OWASP Agentic AI Top 10: seven risks addressed by the scaffold defense architecture, three requiring additional investment.* --- 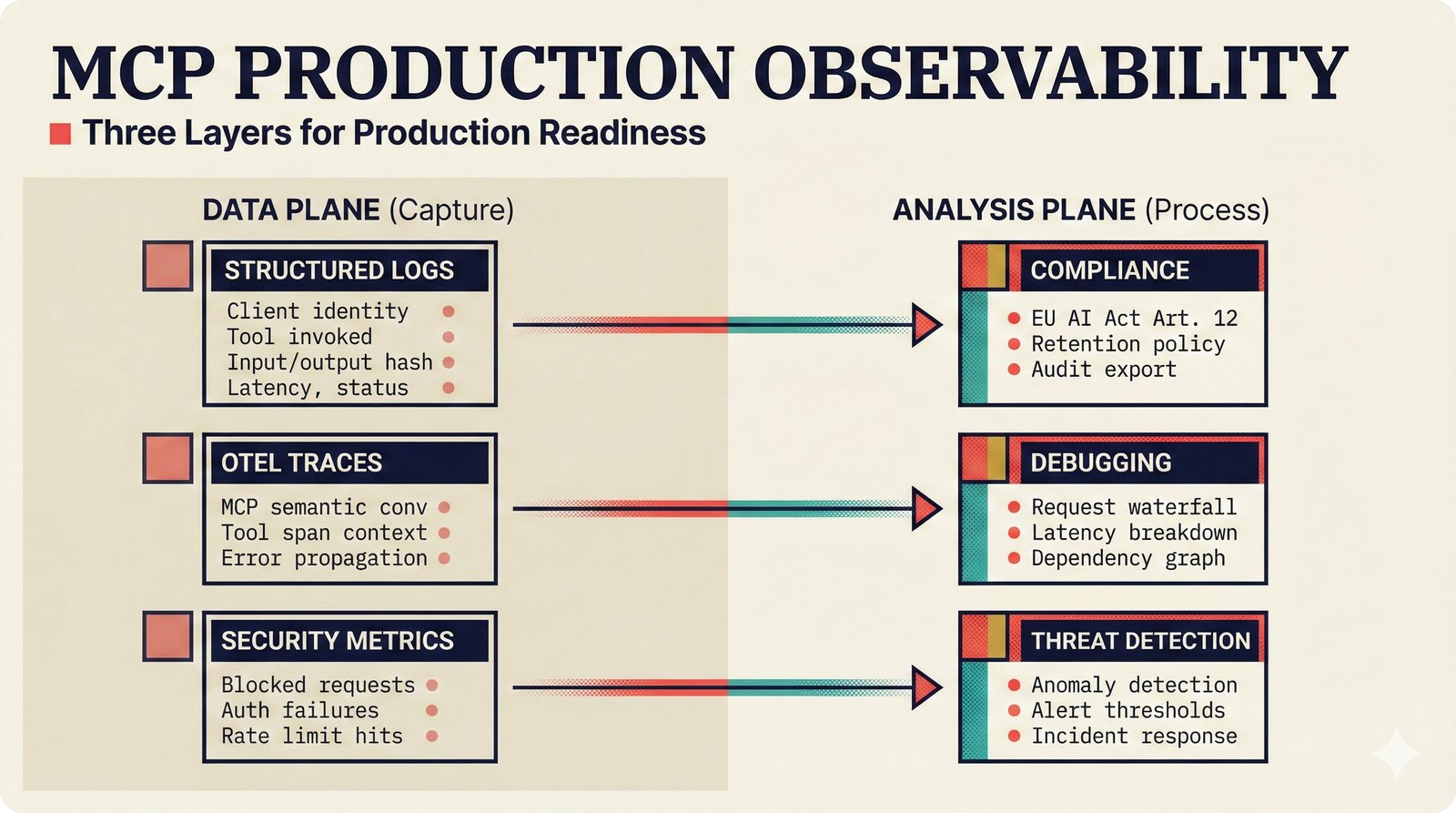 *MCP observability: structured logs, OpenTelemetry traces, and security metrics feeding EU AI Act compliance dashboards.* --- 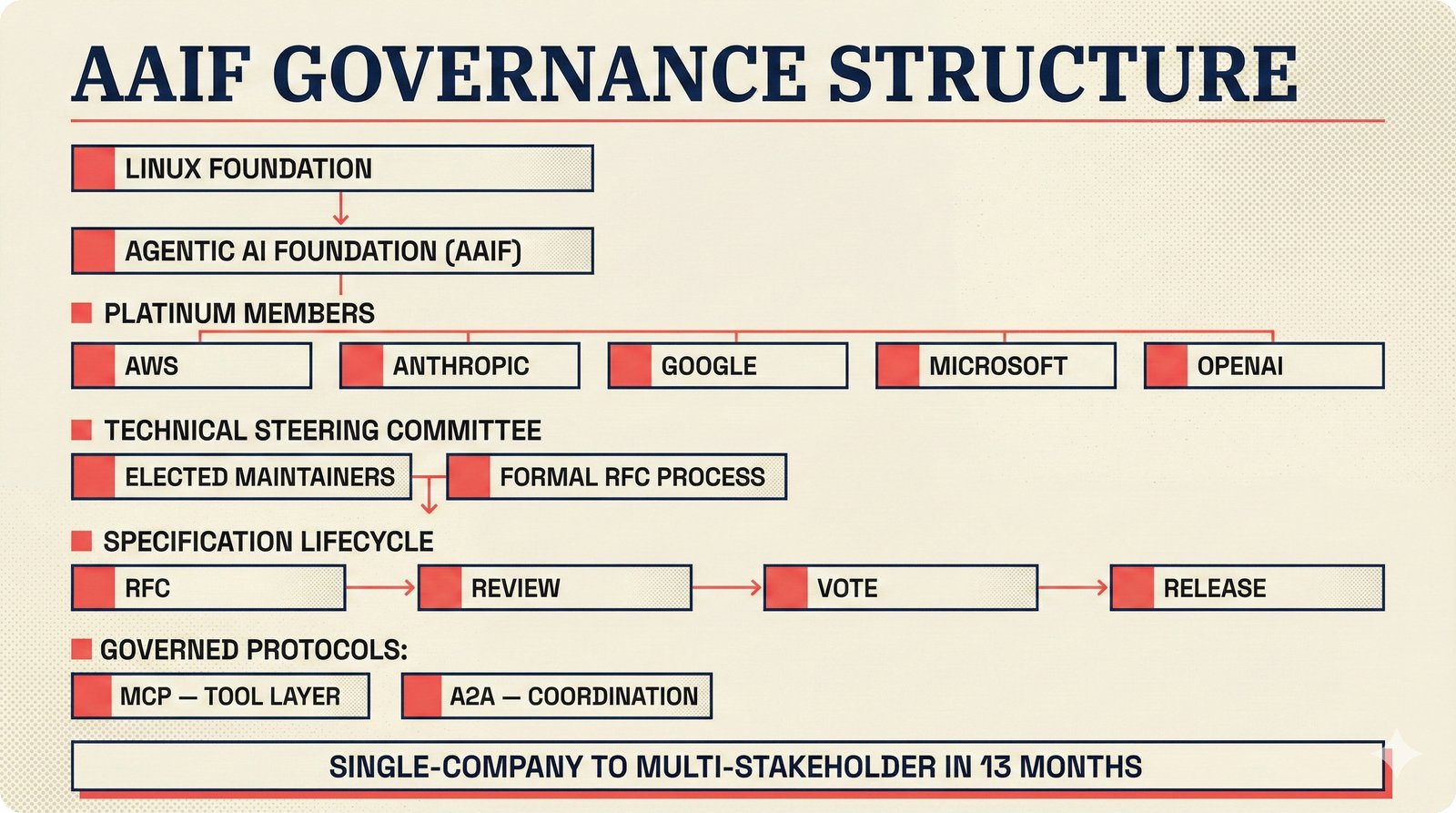 *AAIF governance: Linux Foundation umbrella with AWS, Anthropic, Google, Microsoft, OpenAI as platinum members governing MCP and A2A.*Backend Pipelines¶
The backend pipeline figures trace the complete data flow from raw source extraction through entity resolution to confidence-scored attribution records. Covers the ETL pipeline, boundary object schemas, quality gates, rate limiting, string similarity, embedding matching, Splink linkage, attribution engine, conformal calibration, review queue, FastAPI routing, database ERD, and dependency injection.
20 figures -- click to expand
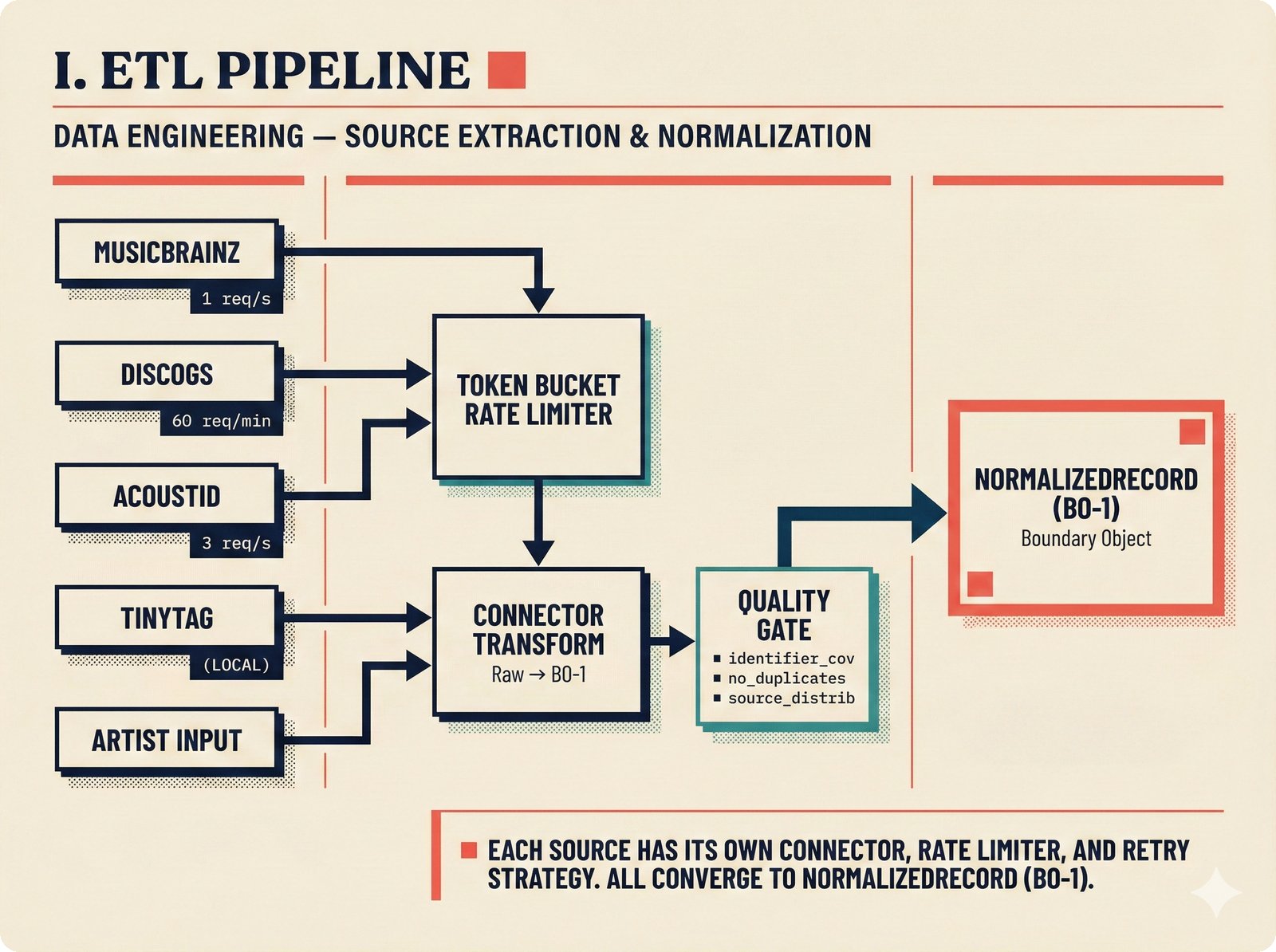 *ETL pipeline: five sources -- MusicBrainz, Discogs, AcoustID, tinytag, Artist Input -- converge through rate limiting and quality gates into NormalizedRecord.* ---  *NormalizedRecord schema: 12 fields, IdentifierBundle with ISRC/ISWC/ISNI/IPI/MBID/Discogs ID/AcoustID, and three validation rules.* --- 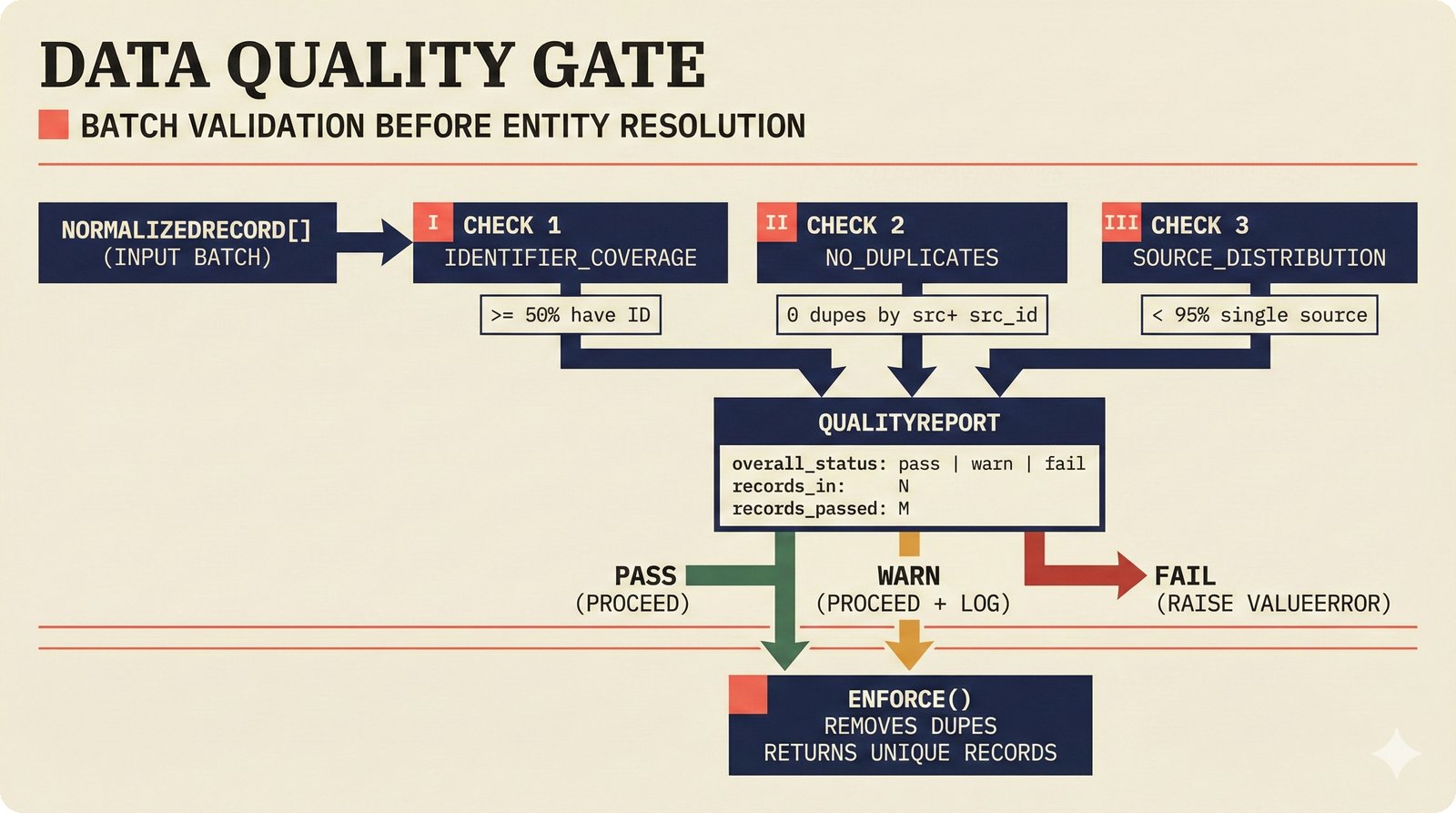 *Data quality gate: identifier coverage at 50% threshold, duplicate detection, and source distribution capping at 95%.* ---  *Source-specific extraction: MusicBrainz (0.90), Discogs (0.85), AcoustID (variable), tinytag (0.70), Artist Input (0.60).* --- 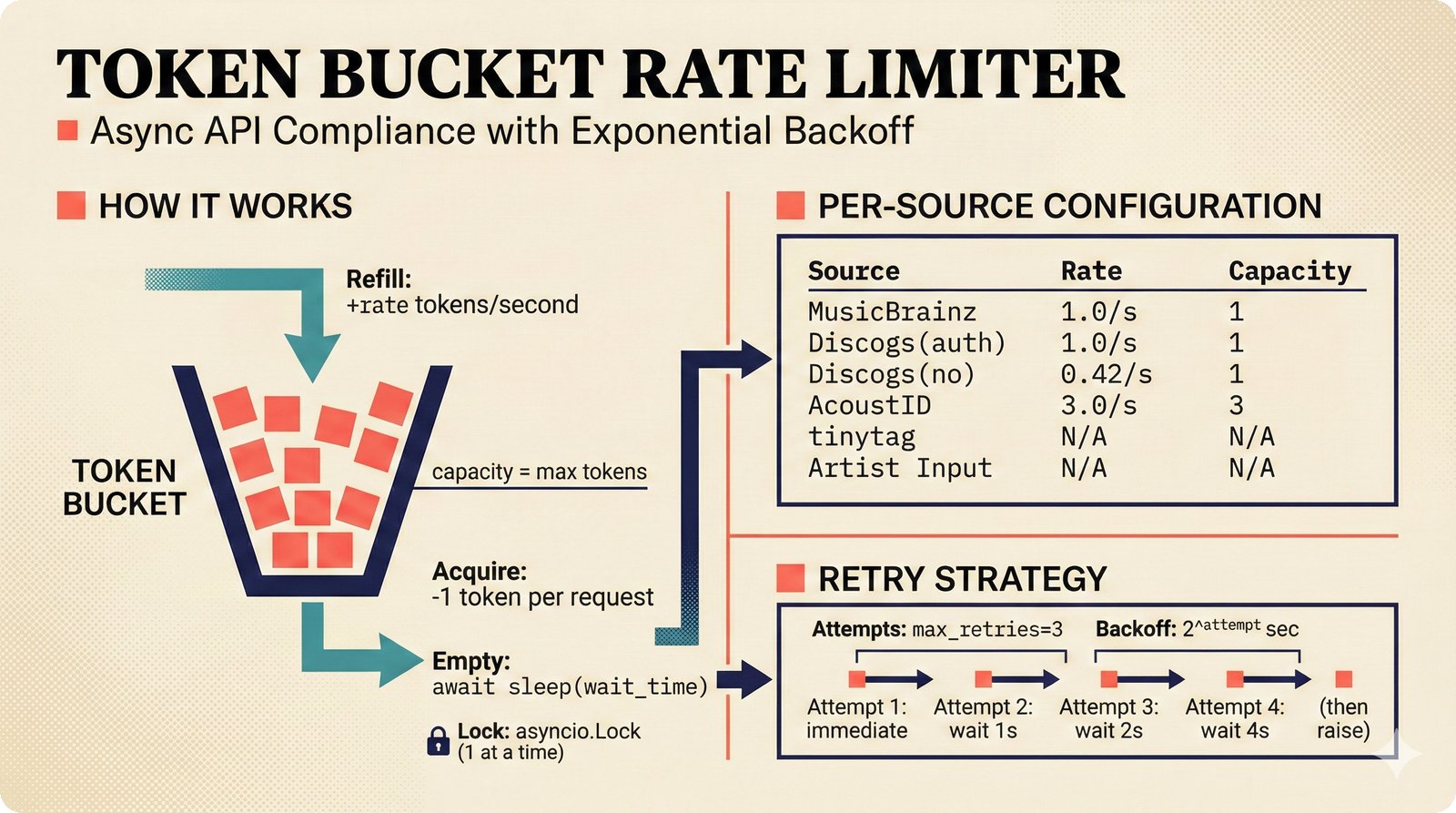 *Rate limiting strategy: per-source token bucket with MusicBrainz at 1 req/s, Discogs at 1 req/s, AcoustID at 3 req/s.* --- 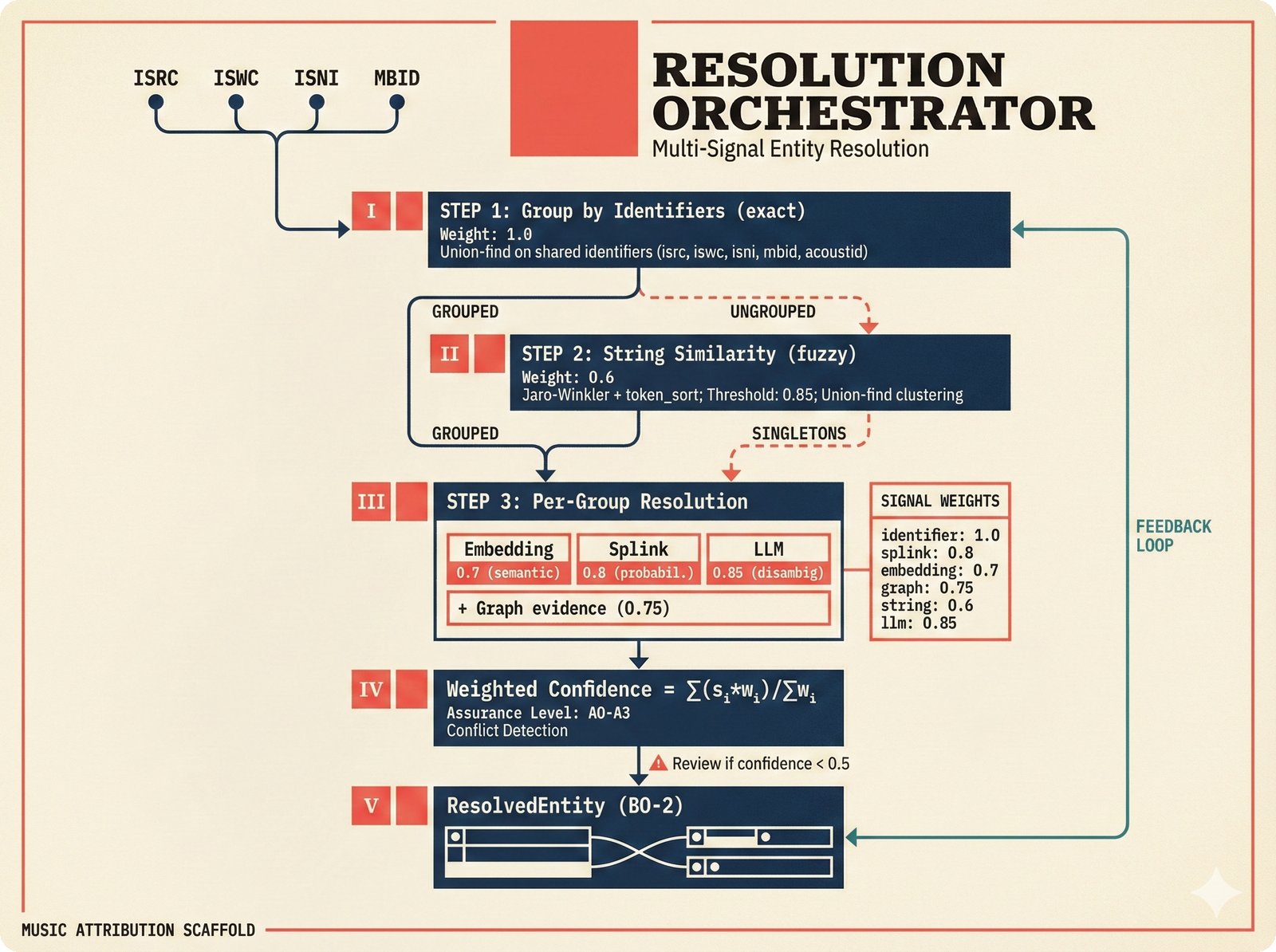 *Resolution orchestrator: exact identifiers, fuzzy strings, embeddings, graph evidence, LLM disambiguation, and Splink linkage producing ResolvedEntity.* --- 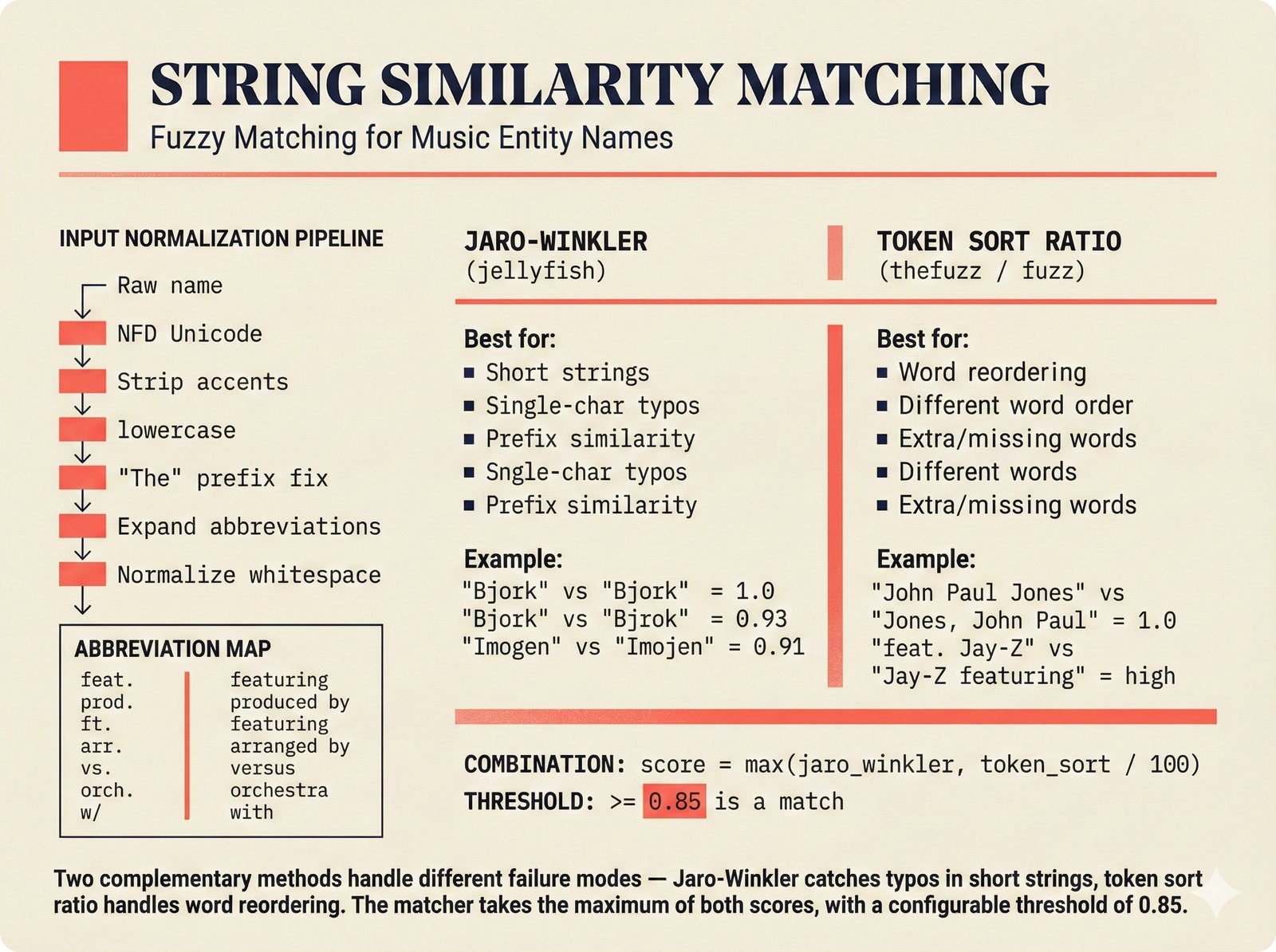 *String similarity methods: Jaro-Winkler for typo detection and token sort ratio for word reordering at 0.85 match threshold.* --- 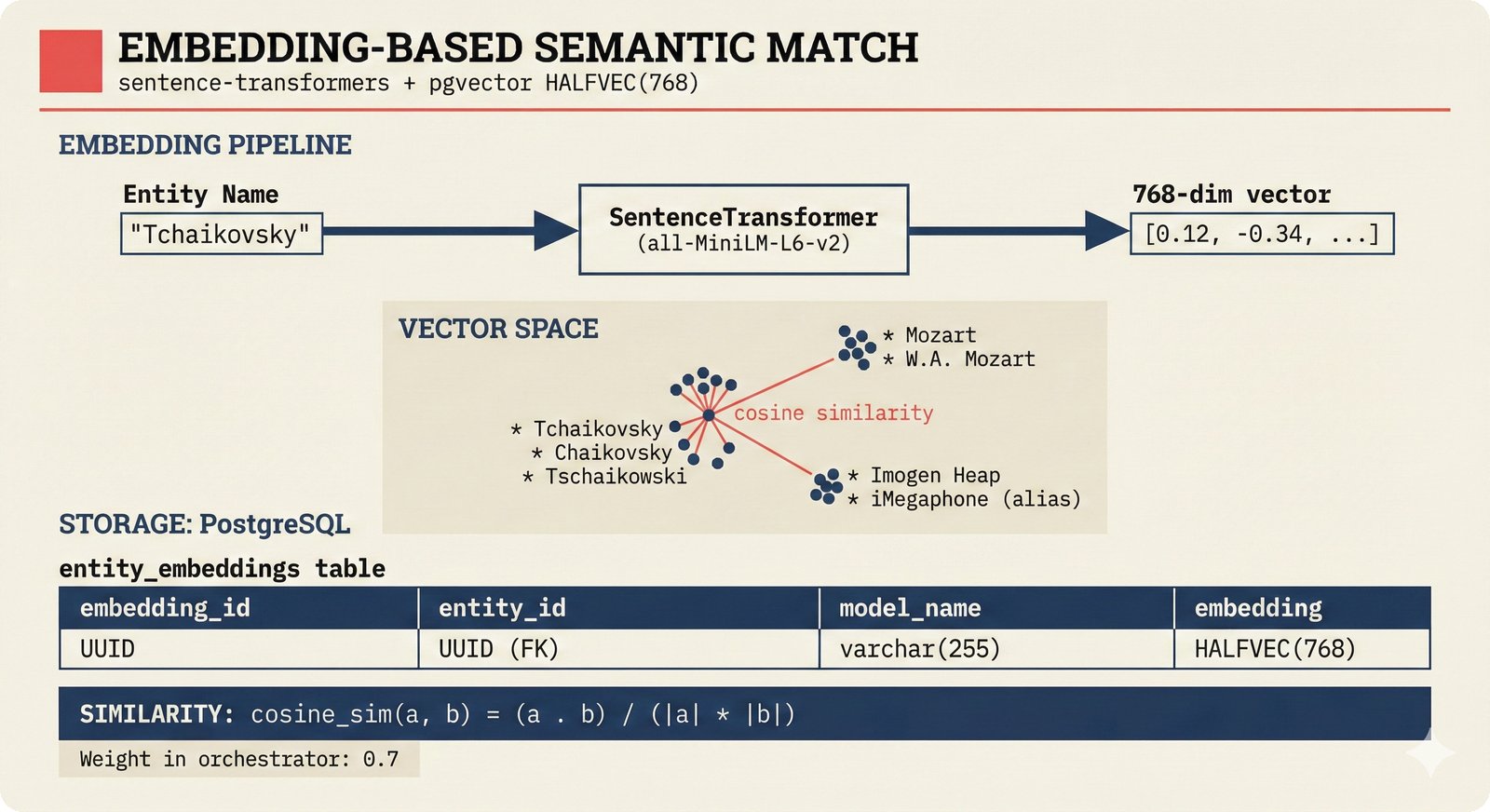 *pgvector embedding match: 768-dimensional sentence-transformer vectors catching translations and alias variations that string matching misses.* --- 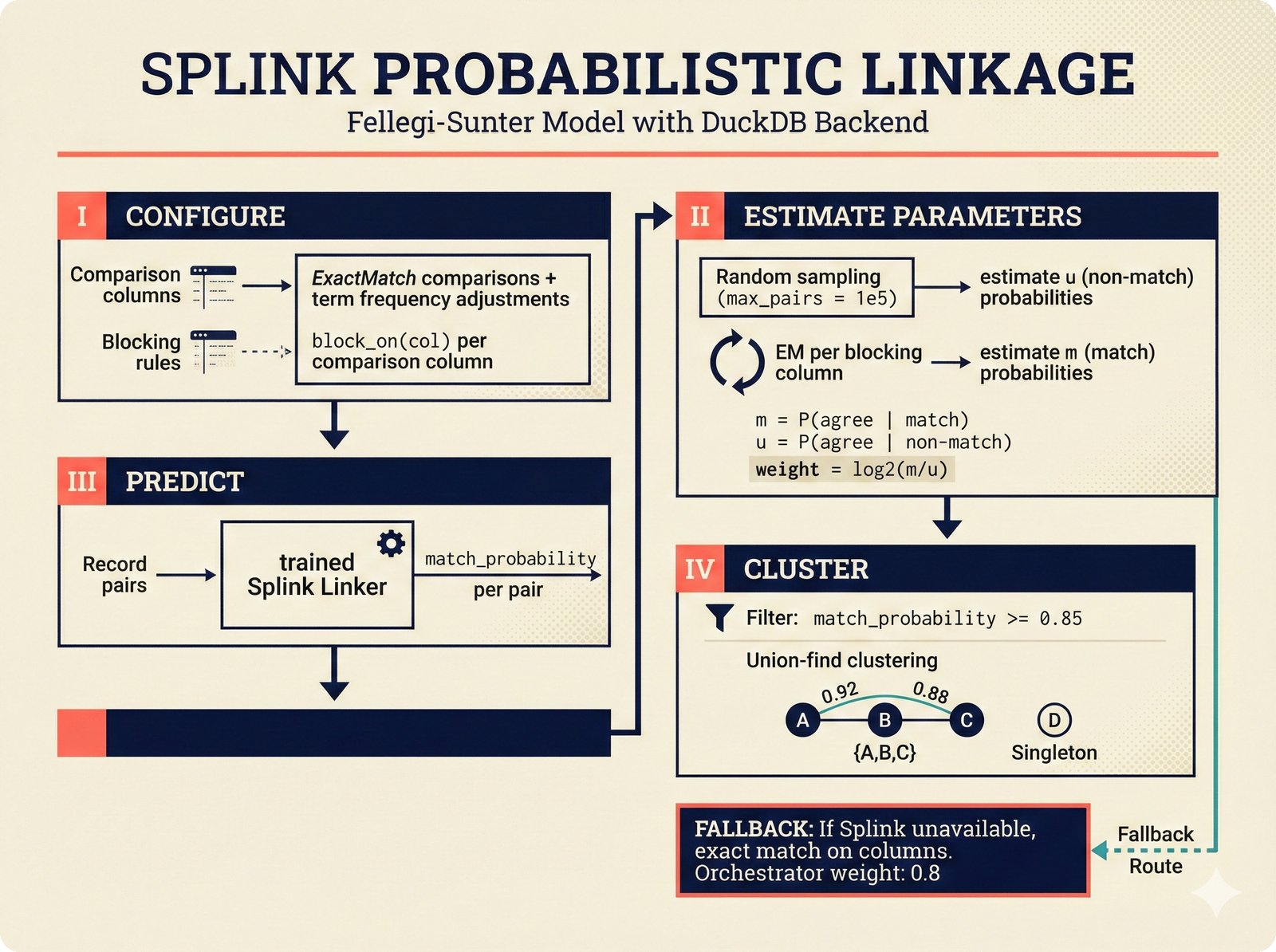 *Splink probabilistic linkage: Fellegi-Sunter match/non-match probabilities via EM, DuckDB backend, and 0.85 threshold clustering.* ---  *ResolvedEntity schema: assurance levels A0-A3, source provenance references, per-method confidence breakdown, and conflict severity.* --- 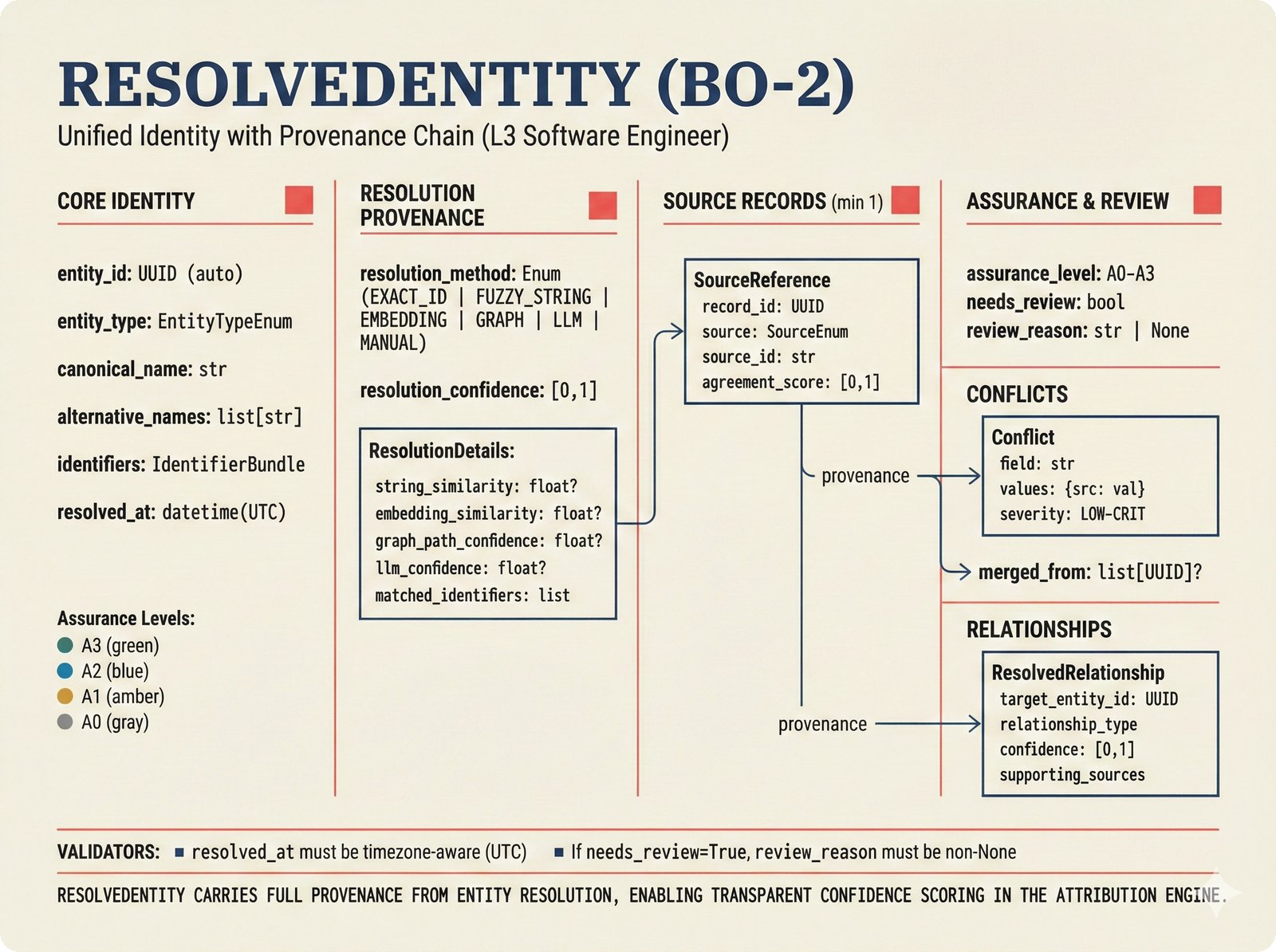 *Attribution engine: weighted credit aggregation, conformal prediction calibration at 90% coverage, and active learning review prioritization.* ---  *Weighted source aggregation: MusicBrainz 0.95, Discogs 0.85, AcoustID 0.80, file 0.70, Artist Input 0.60 -- worked example computing 0.845.* ---  *Conformal calibration: APS method accumulating predictions until 90% coverage, with reliability diagram and Expected Calibration Error.* --- 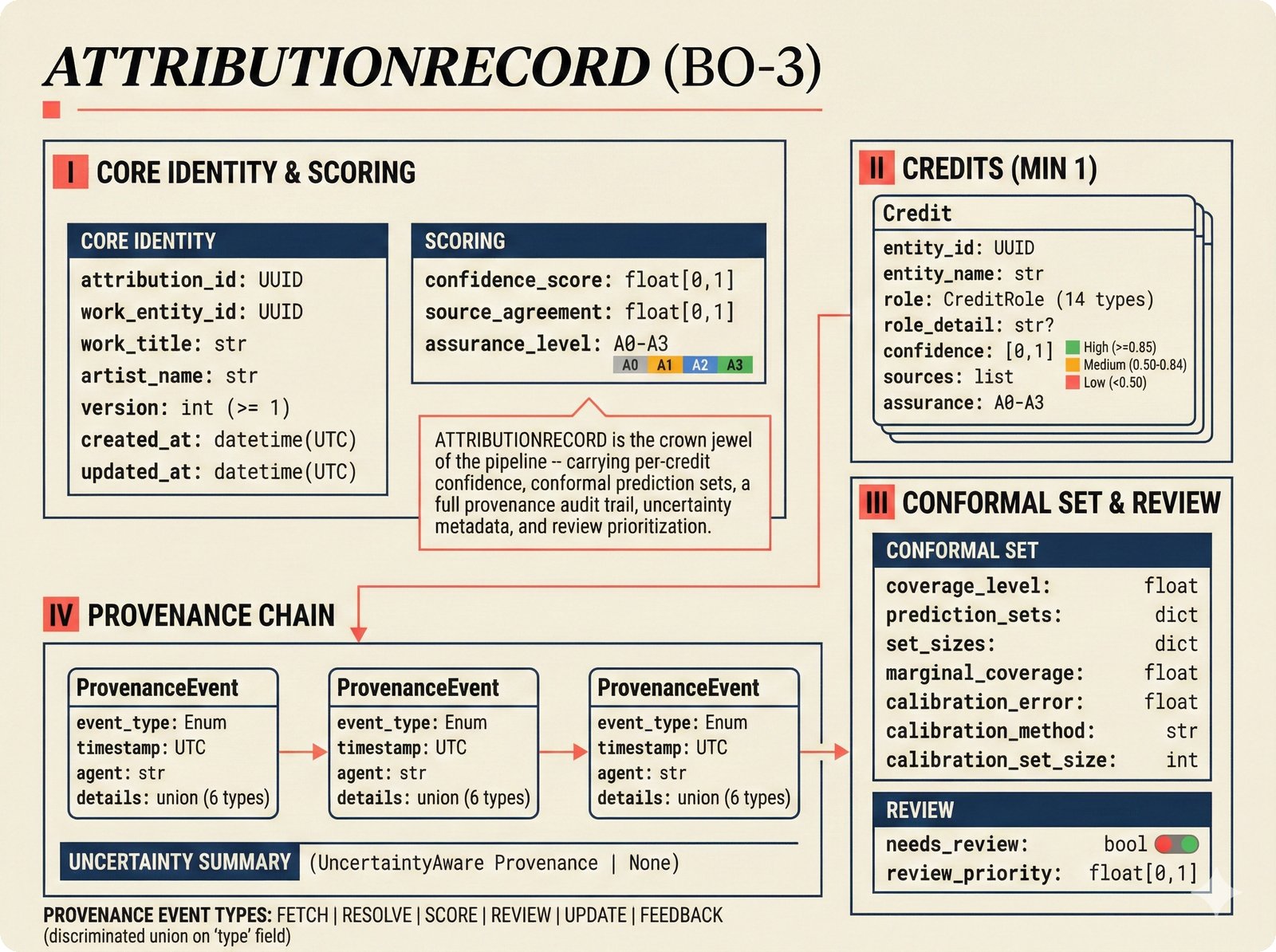 *AttributionRecord schema: per-credit confidence for 14 role types, conformal sets, six provenance event types, and A0-A3 assurance.* ---  *Review priority queue: boundary proximity (30%), source disagreement (25%), conformal ambiguity (15%), never-reviewed (15%), staleness (15%).* --- 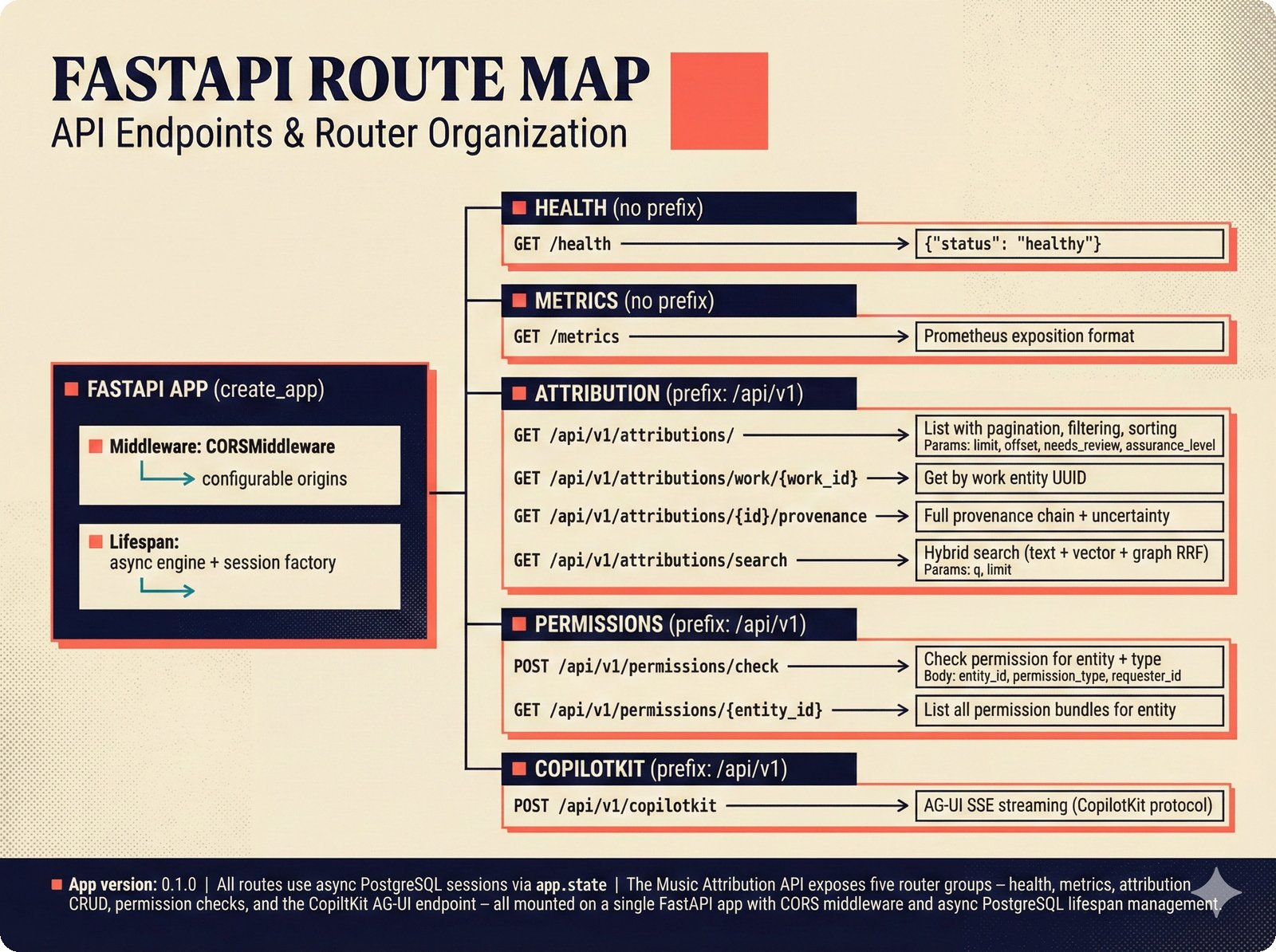 *FastAPI route map: health, Prometheus metrics, attribution CRUD with hybrid search, MCP permissions, and CopilotKit AG-UI endpoint.* --- 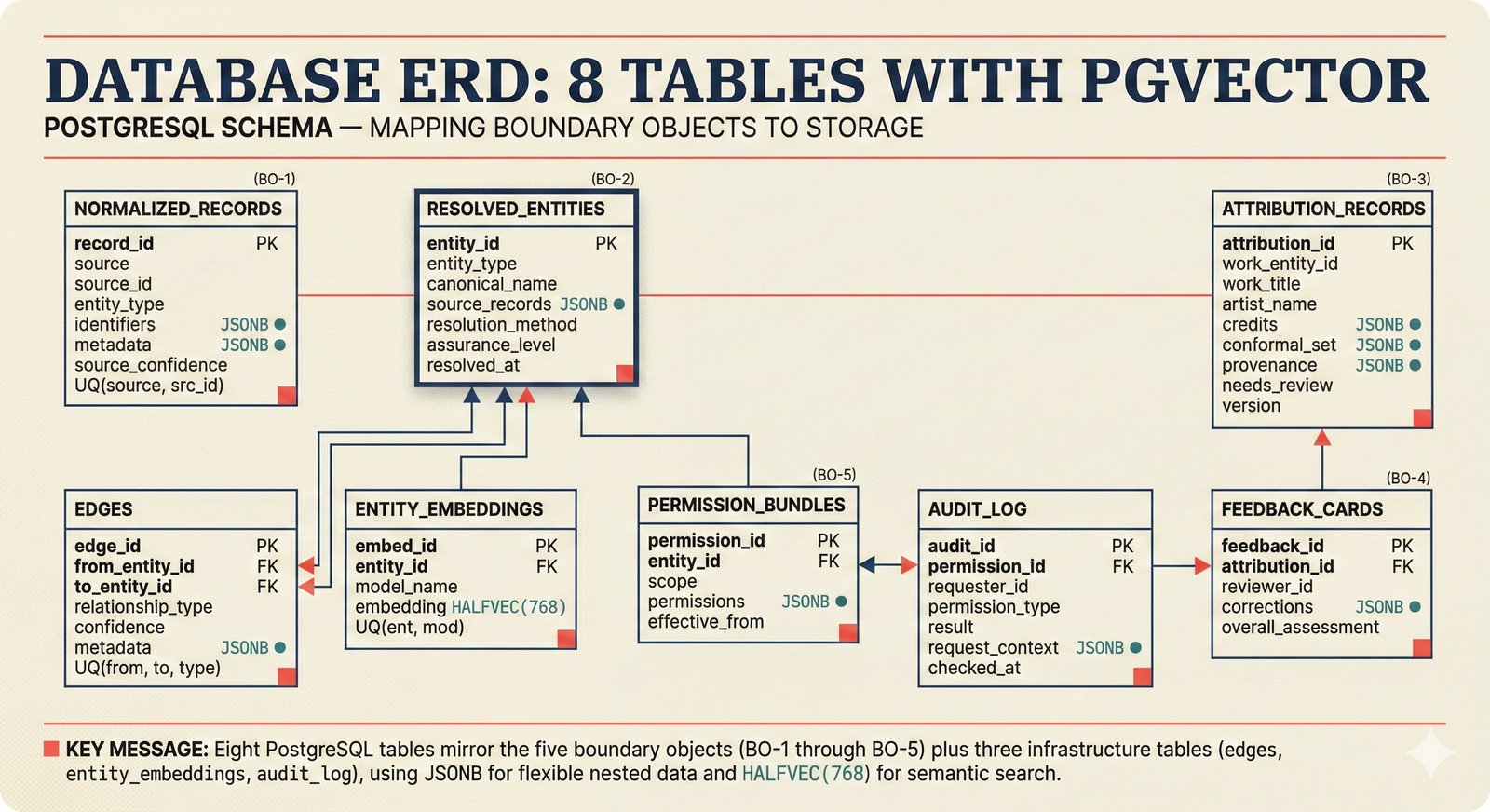 *Database ERD: normalized_records, resolved_entities, attribution_records with JSONB, feedback_cards, permissions, graph edges, embeddings, and audit log.* --- 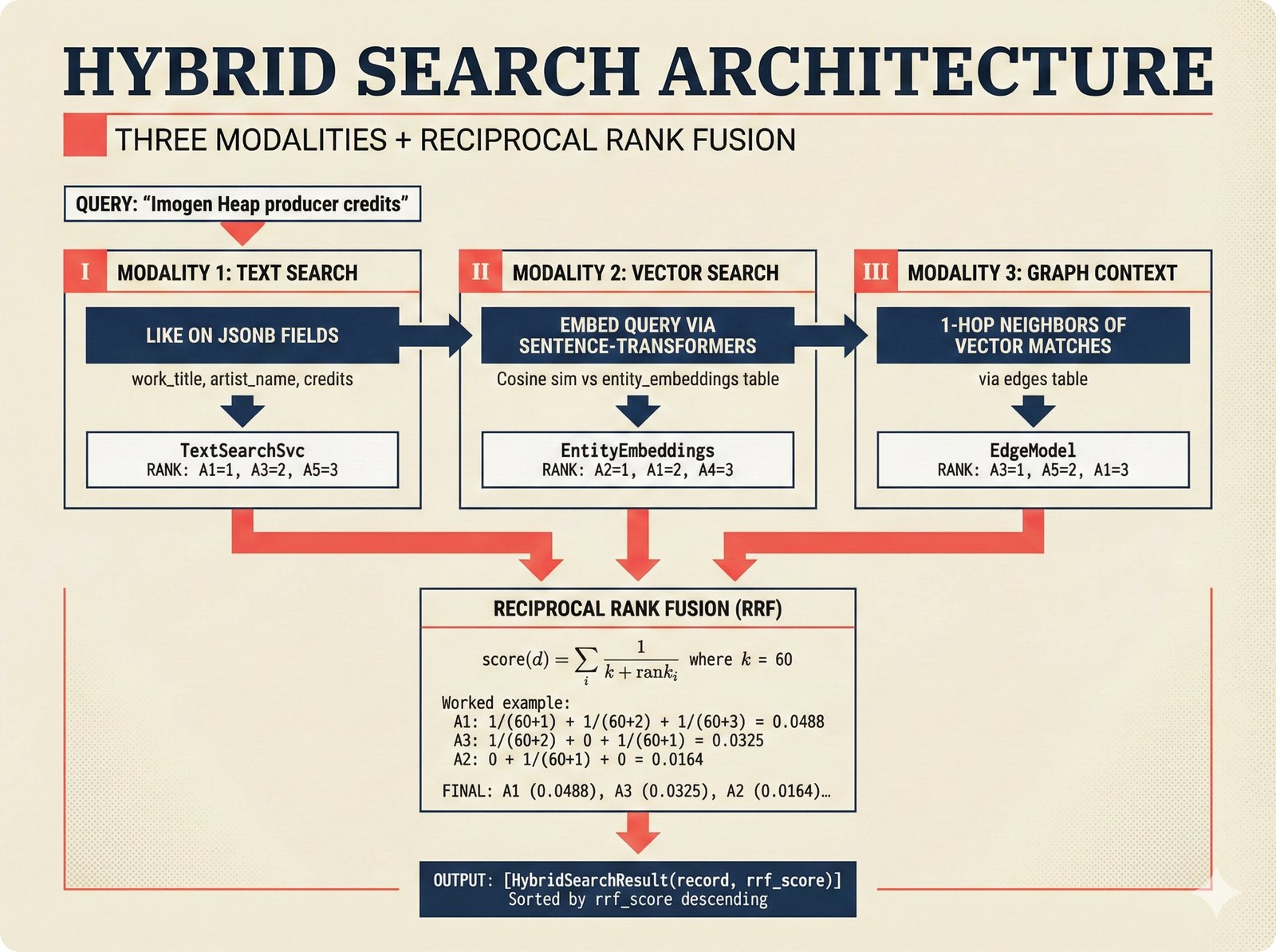 *Hybrid search: full-text LIKE, sentence-transformer pgvector embeddings, and 1-hop graph context fused with RRF (k=60).* --- 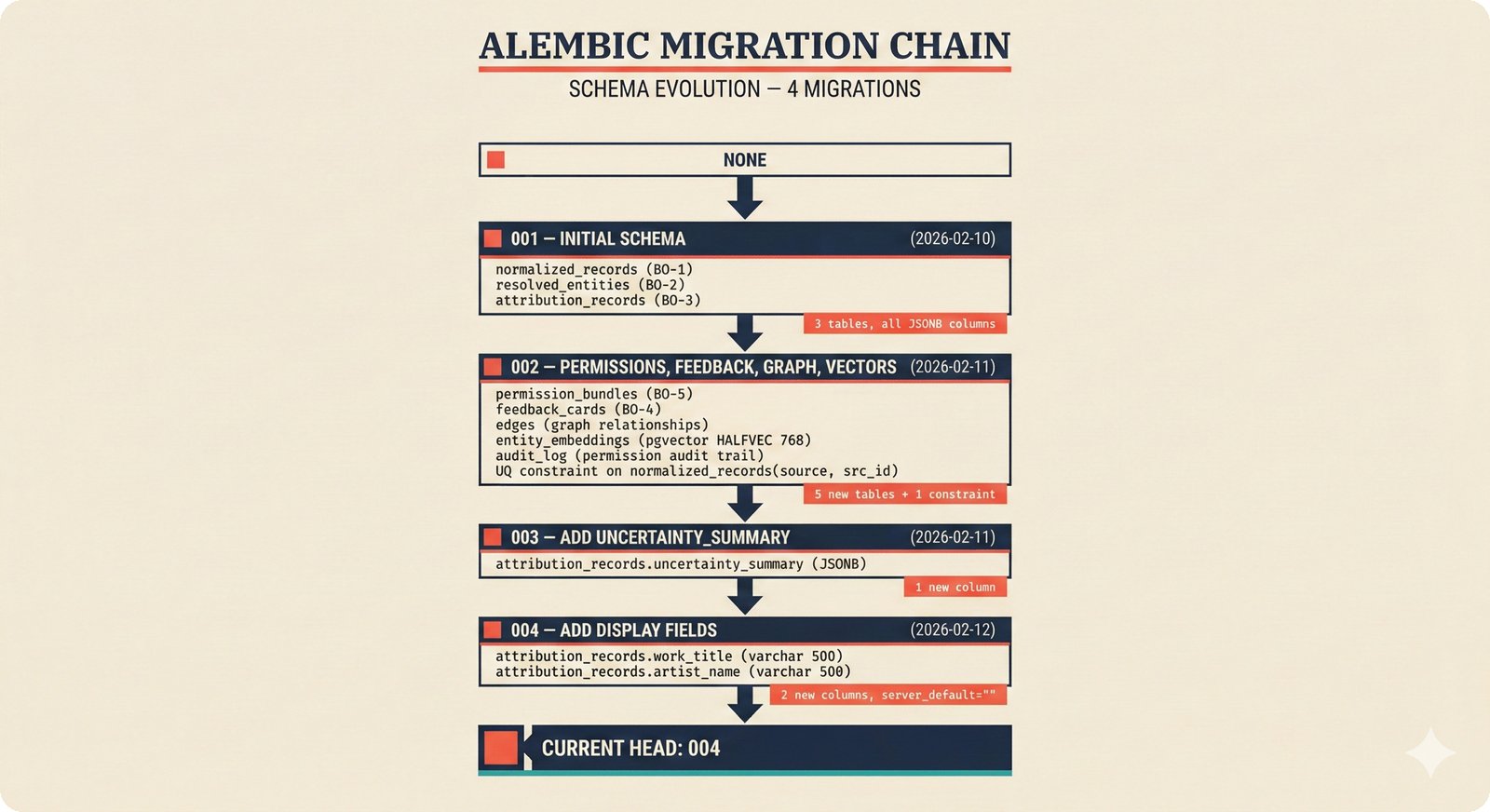 *Alembic migration chain: initial schema, permissions and pgvector, uncertainty metadata, and display fields -- all reversible.* --- 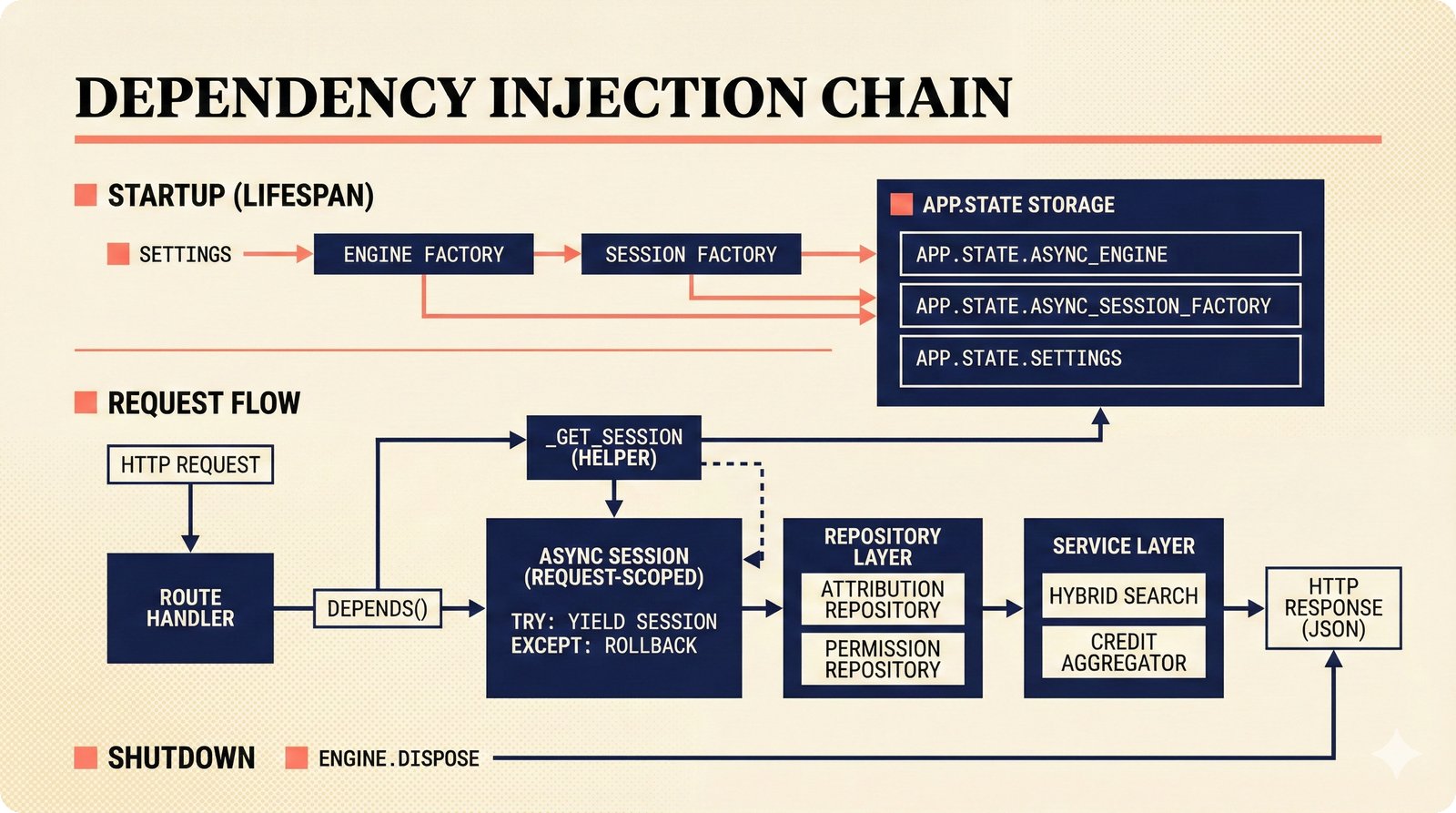 *Dependency injection: lifespan creates async engine on app.state, request-scoped sessions flow through repository and service layers.*Agentic UI¶
The agentic UI figures cover the complete end-to-end architecture of the AI-assisted chat interface, from CopilotKit frontend integration through AG-UI protocol to PydanticAI agent tools, model failover, conversation flow, voice agent upsell, and testing strategy.

Full-stack agentic UI: CopilotKit sidebar to AG-UI SSE to PydanticAI agent with four tools and bidirectional DuetUI context.

PydanticAI agent architecture: domain-specific system prompt, AgentDeps for database access, four tools, and Claude Haiku default.

AG-UI protocol flow: RunStarted, TextMessageStart, chunked Content, TextMessageEnd, StateSnapshot, RunFinished via SSE.

CopilotKit integration: provider with graceful degradation, useCopilotReadable for context, and four useCopilotAction hooks.

Tool: explain_confidence -- work ID to database lookup, source agreement extraction, confidence factors, and human-readable output.

Tool: search_attributions -- hybrid search across attribution records with confidence percentages and assurance levels per hit.

Model failover: environment variable configuration defaulting to Haiku, automatic cascading to more capable models on failure.

Conversation flow: user query chains search_attributions and explain_confidence with source agreement breakdown and live sidebar updates.

Voice agent upsell: subtle aspirational banner for Pro tier -- microphone icon, example query, "Upgrade to Pro" -- no actual voice processing.

Testing strategy: deterministic tests around non-deterministic AI -- proficiency thresholds, event schema validation, and mock agent endpoint testing.
Frontend Design¶
The frontend design figures document the Next.js 15 application architecture, design token system, page routing, component patterns, state management, typography, color system, responsive layout, accessibility, analytics, and adaptive UI proficiency model.
15 figures -- click to expand
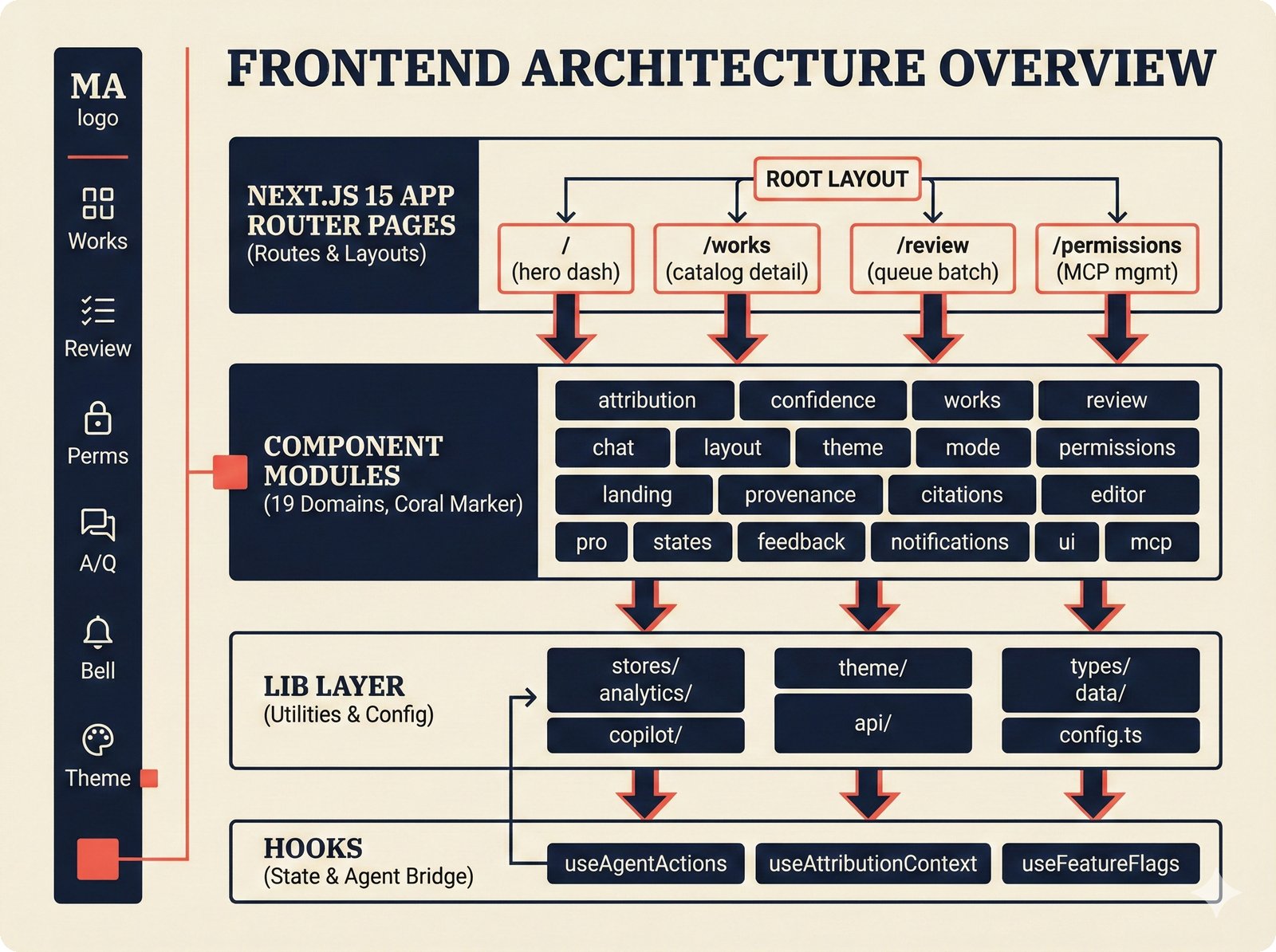 *Frontend architecture: four layers -- pages compose components, components consume lib, hooks wire to Jotai state and CopilotKit agent.* --- 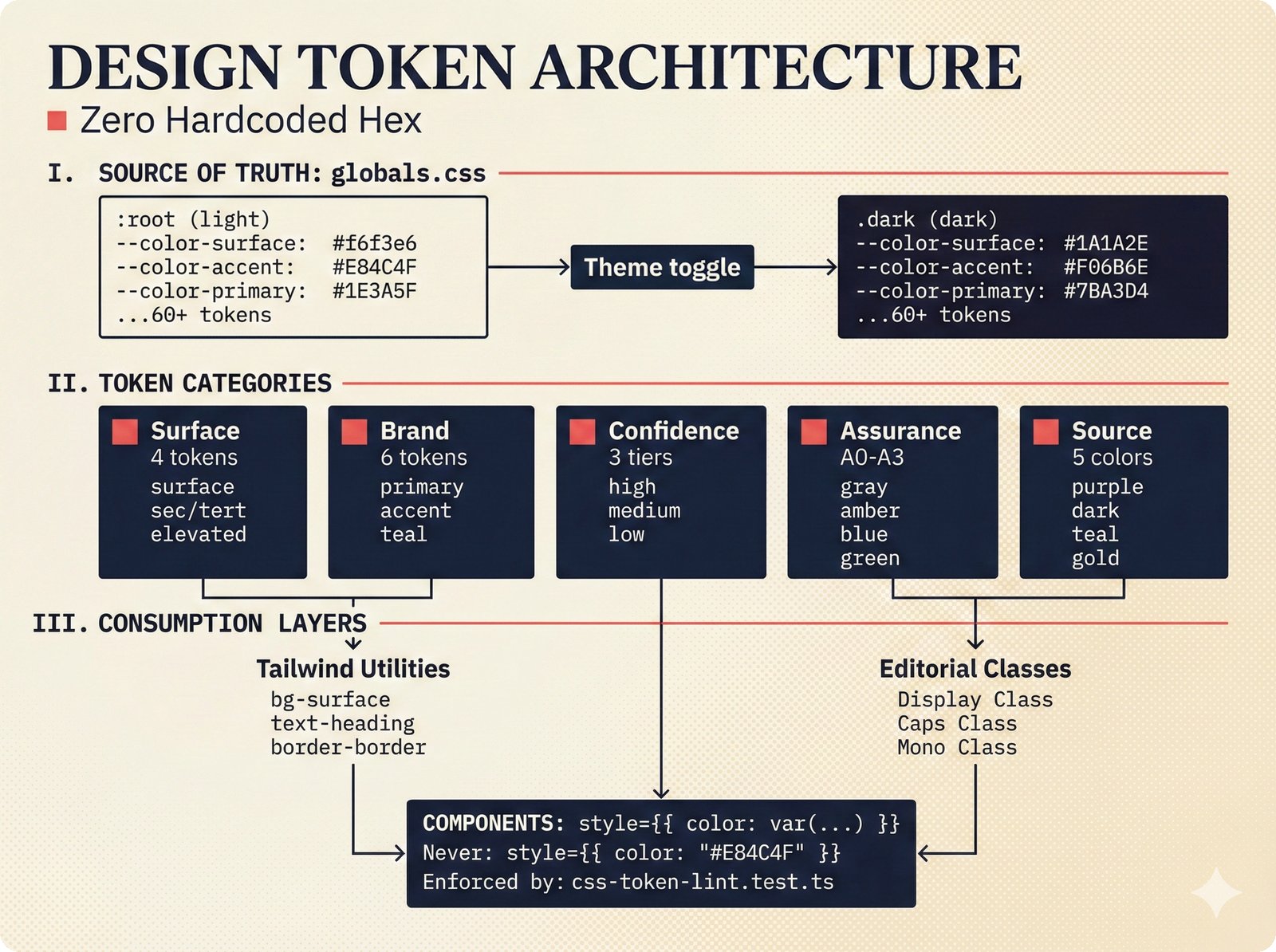 *Design token architecture: 60+ CSS custom properties in globals.css, Tailwind v4 utilities, zero hardcoded hex enforced by lint tests.* --- 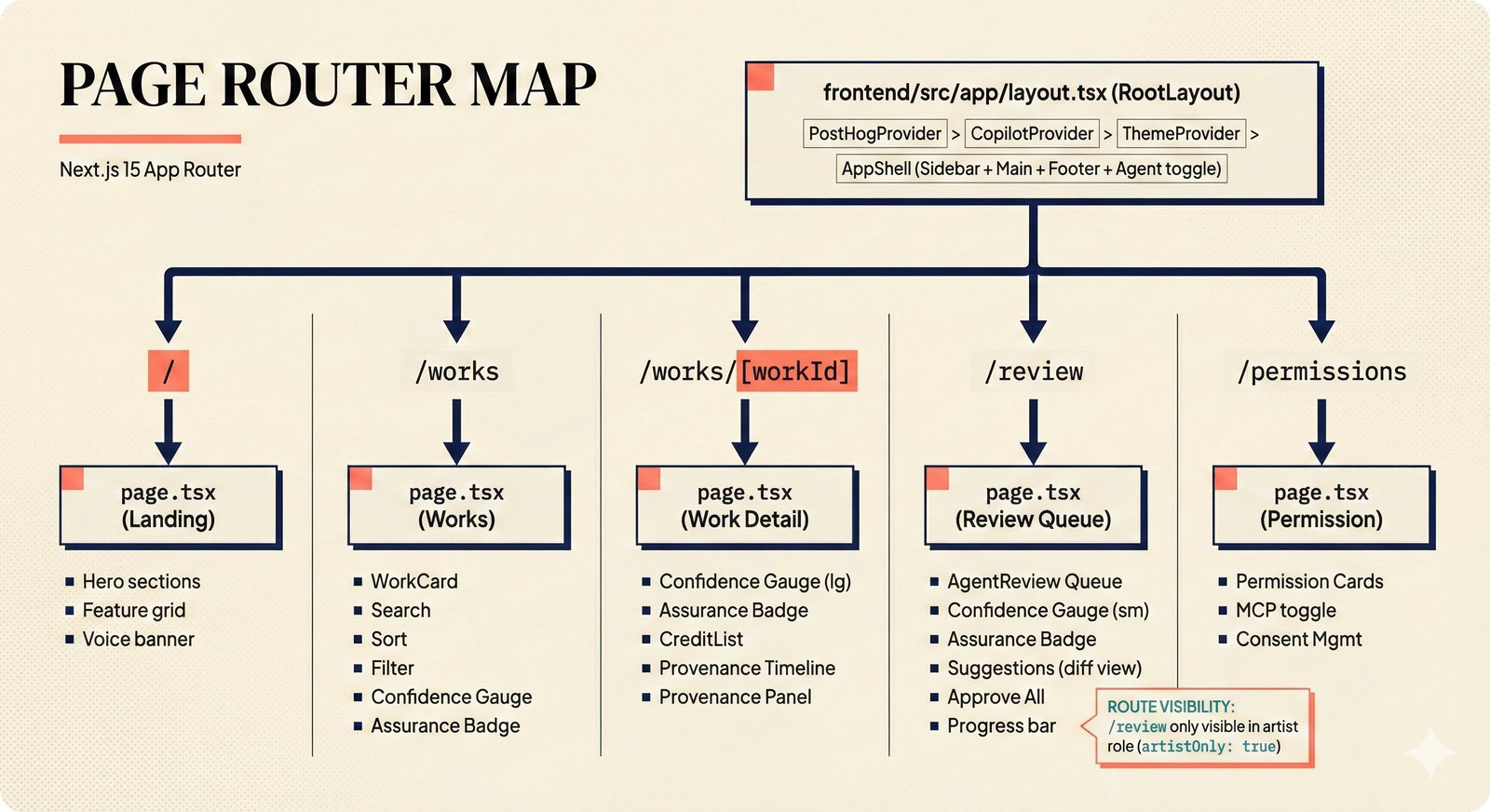 *Page router map: five routes -- home, works catalog, work detail, review queue, and MCP permissions -- branching from shared layout.* ---  *ConfidenceGauge: 270-degree SVG arc in green/amber/red tiers with ARIA meter role and motion-safe mount animation.* --- 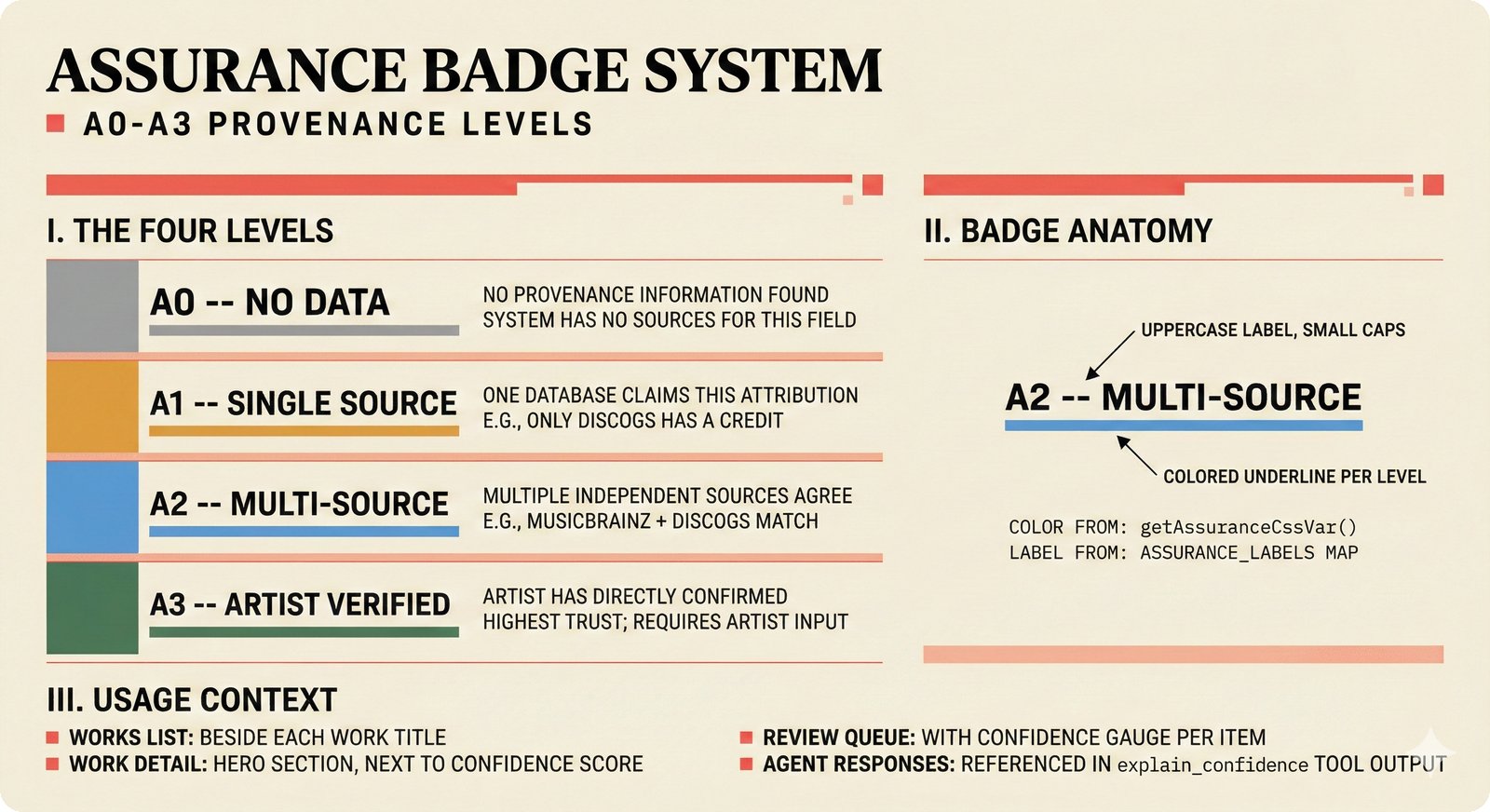 *Assurance badges: A0 gray (no data), A1 amber (single source), A2 blue (multi-source), A3 green (artist verified).* ---  *Works list layout: fixed sidebar navigation, horizontal rows with confidence gauges, assurance badges, and Jotai-driven search/sort.* ---  *Work detail layout: hero confidence gauge, per-credit scores with source tags, Perplexity-style provenance, and chronological timeline.* ---  *Review queue workflow: agent narration header, progress tracking, suggestion diffs showing before/after, and batch approval.* --- 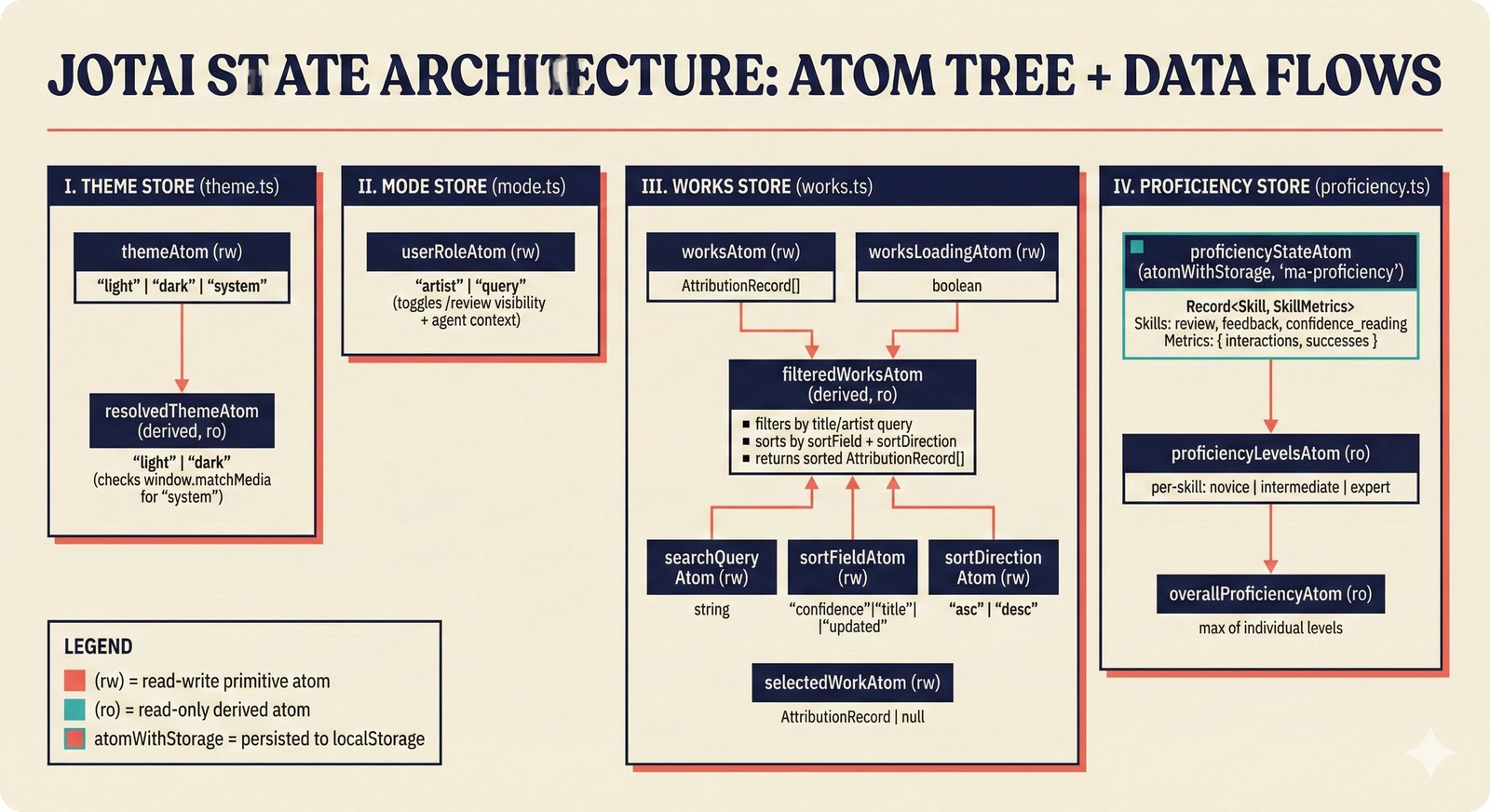 *Jotai state architecture: four atom stores for theme, role mode, works catalog with filtered/sorted atoms, and localStorage proficiency.* ---  *Typography system: Instrument Serif for editorial display, Plus Jakarta Sans for body/UI, IBM Plex Mono for data values.* ---  *Color system: warm cream/dark navy surfaces, coral red accent, confidence tiers, A0-A3 assurance, five source colors, and role accents.* --- 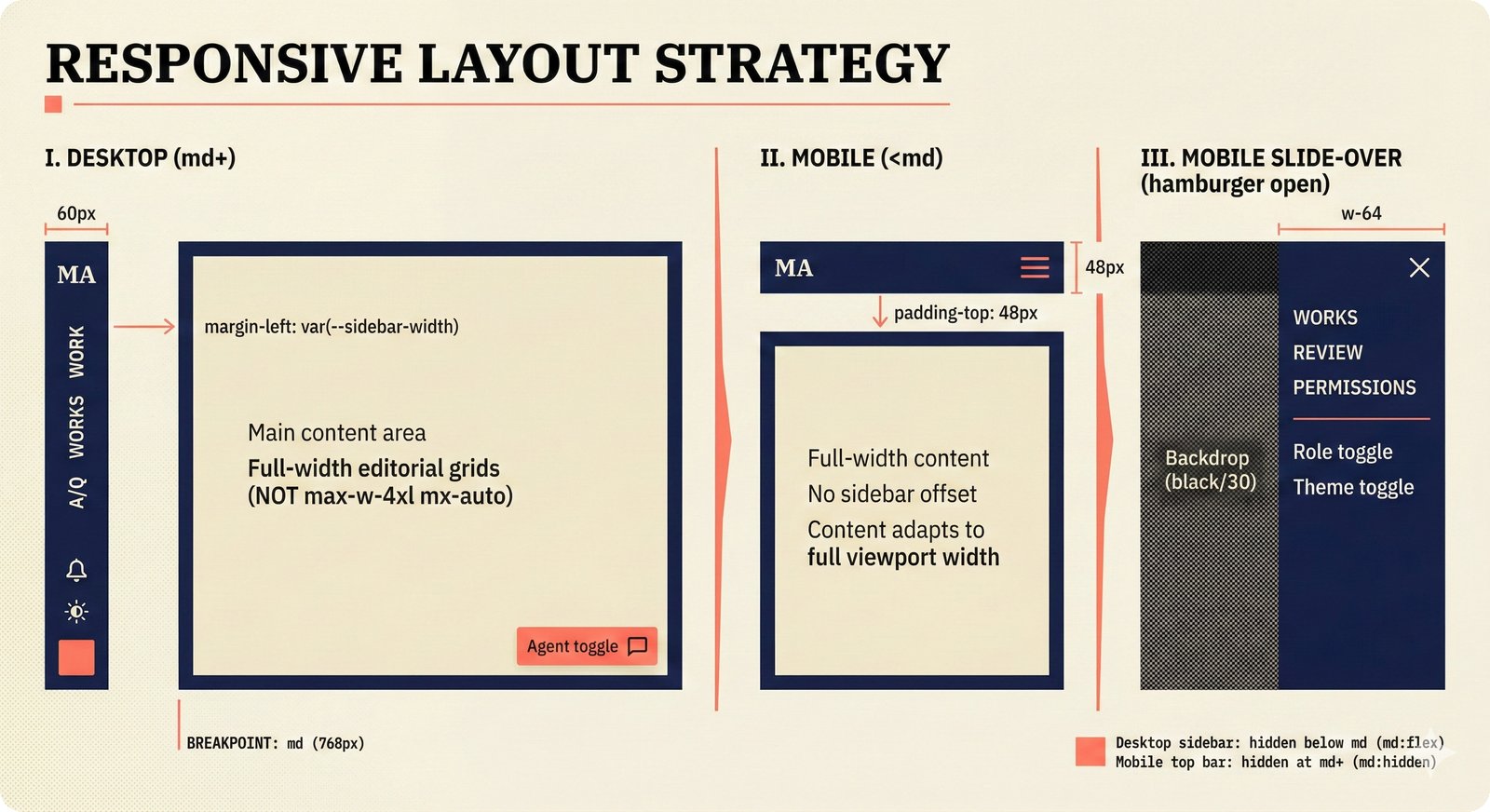 *Responsive layout: desktop fixed sidebar, mobile top bar with hamburger, Tailwind v4 breakpoints for any device.* --- 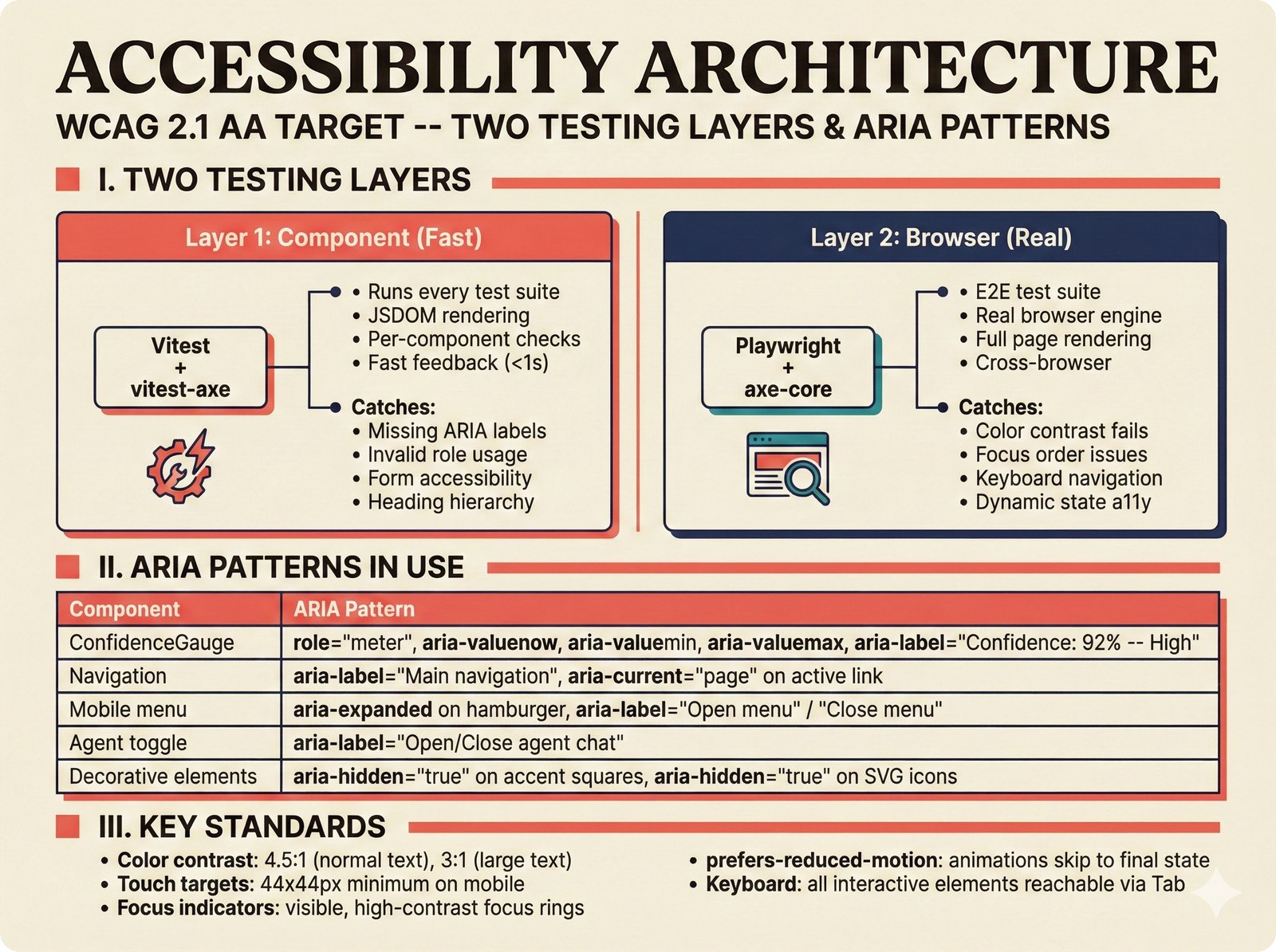 *Accessibility architecture: fast component-level vitest-axe checks and real-browser Playwright axe-core validation with ARIA pattern catalog.* --- 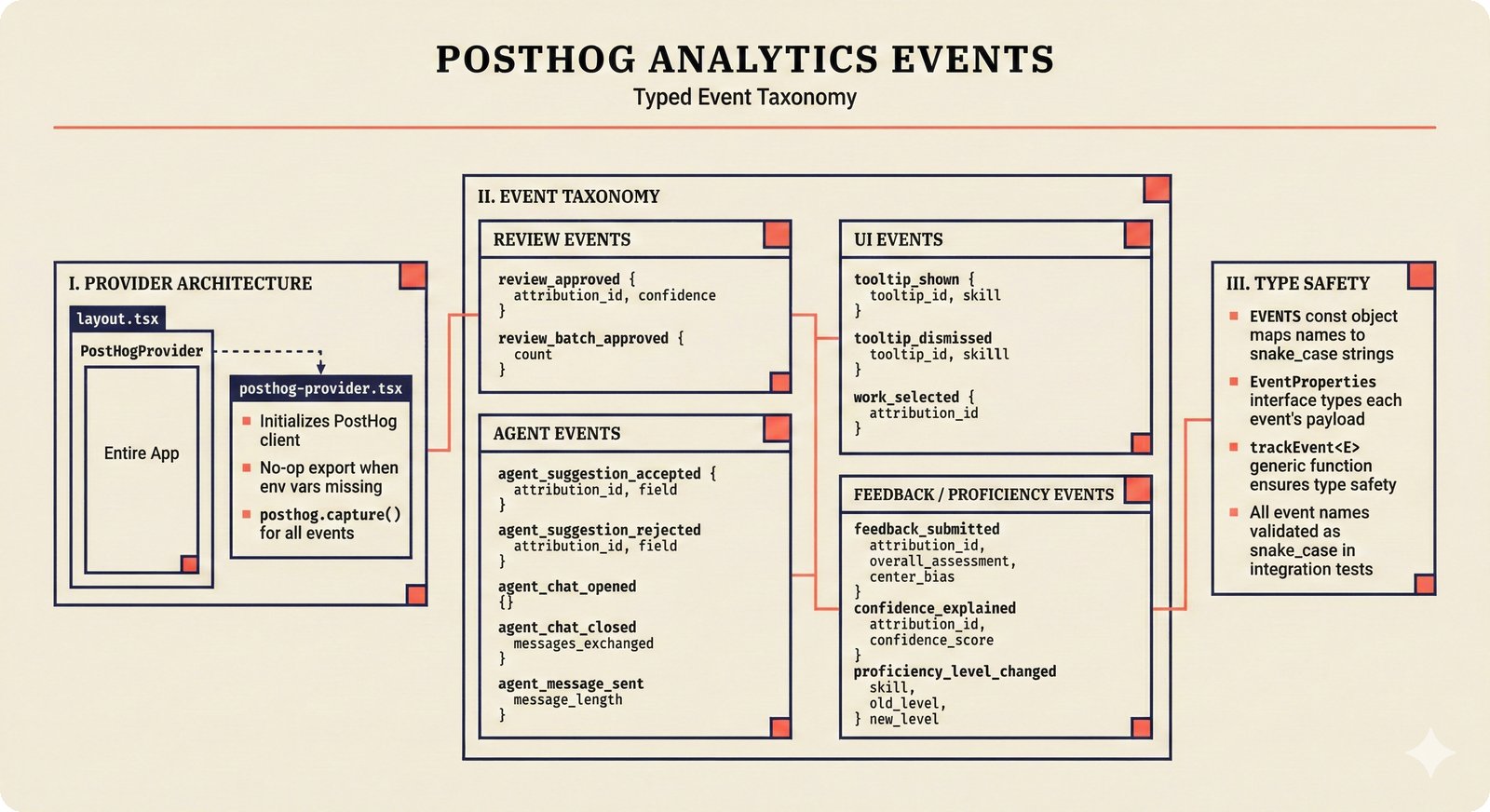 *PostHog analytics: 12 typed events tracking review approval, agent chat, interactions, and feedback with graceful no-op fallback.* --- 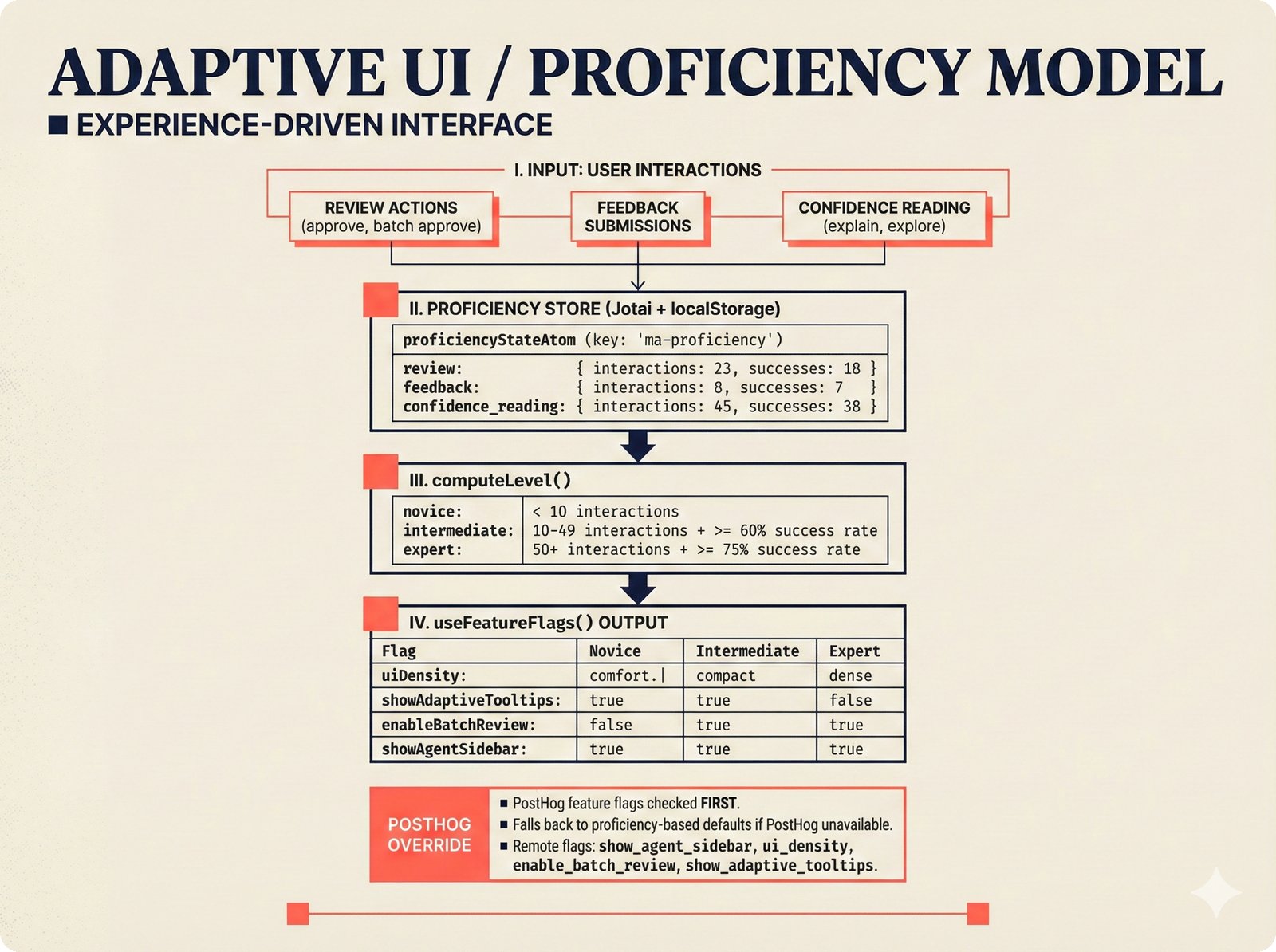 *Adaptive UI proficiency: user interactions feed Jotai store, computeLevel produces novice/intermediate/expert, useFeatureFlags adapts UI density.*Technology Choices¶
Each technology choice figure documents a specific architecture decision from the probabilistic PRD -- comparing selected options against alternatives with rationale. Covers framework selection, database strategy, confidence methods, package management, deployment, and sovereignty considerations.
18 figures -- click to expand
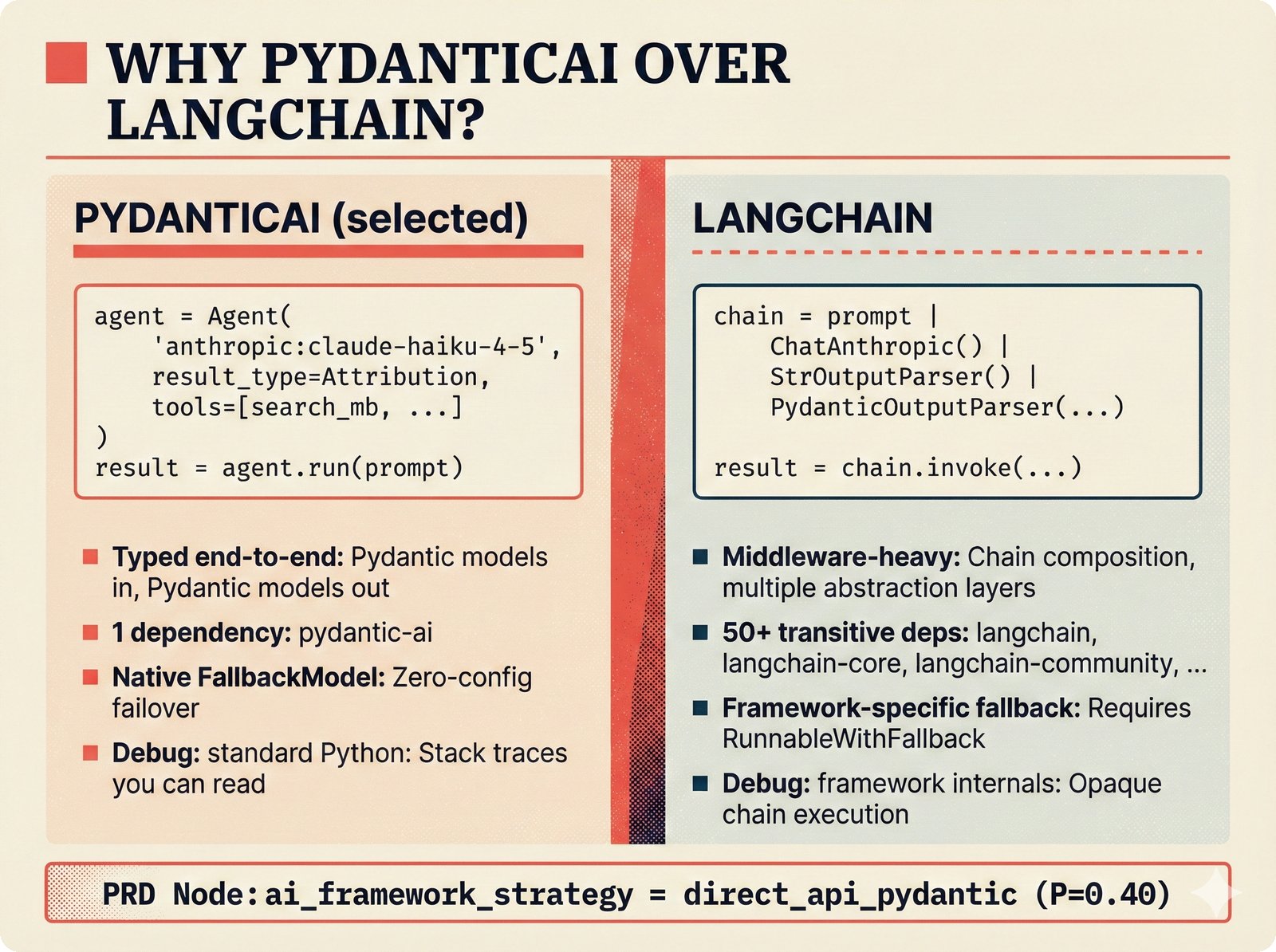 *PydanticAI over LangChain: typed Pydantic-native agents with fewer dependencies and readable stack traces.* ---  *CopilotKit AG-UI: open-source streaming with 31 event types and MCP integration for bidirectional shared state.* --- 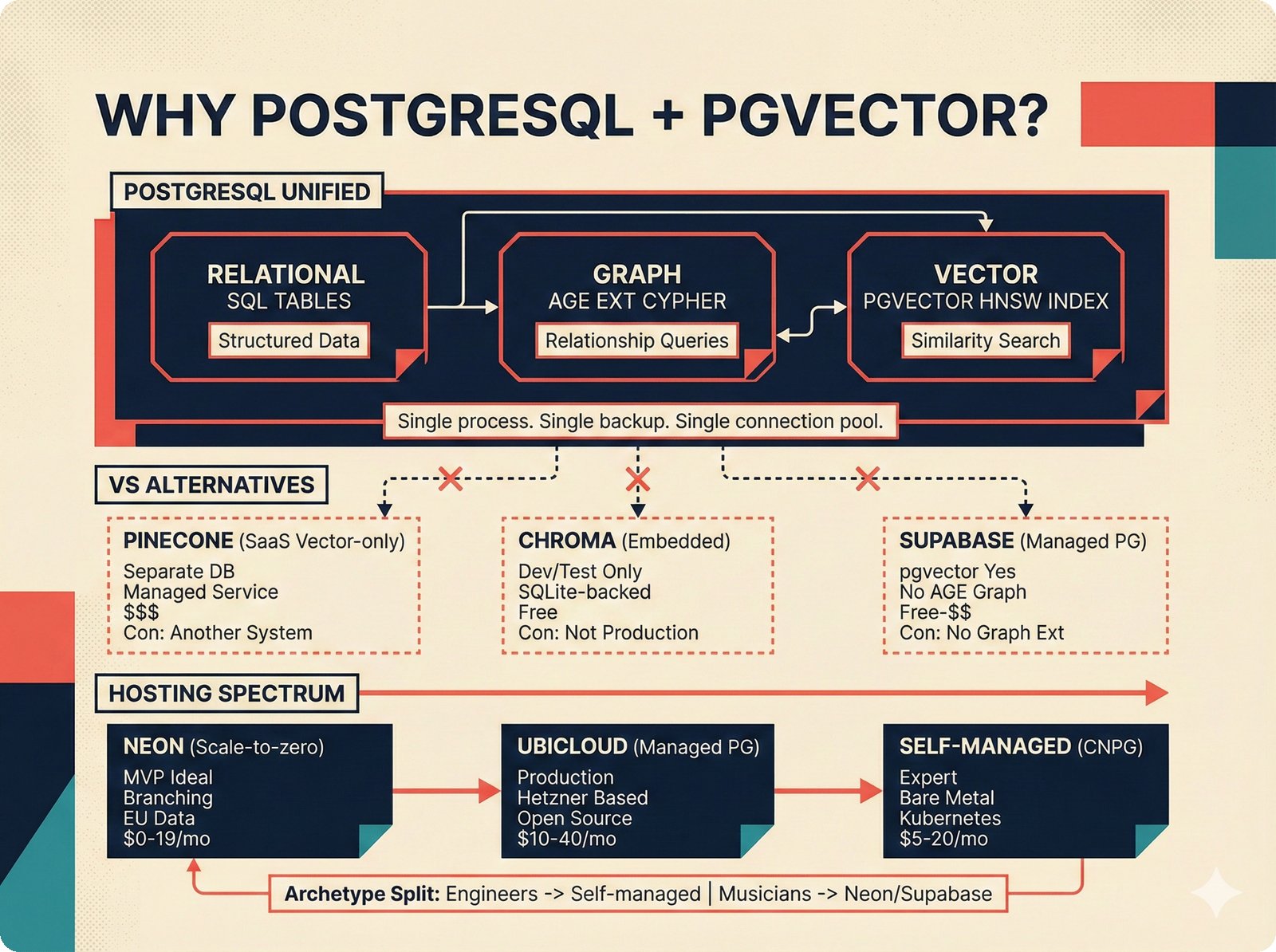 *PostgreSQL pgvector: relational, graph, and vector unified -- compared against Pinecone, Chroma, and Supabase with hosting spectrum.* --- 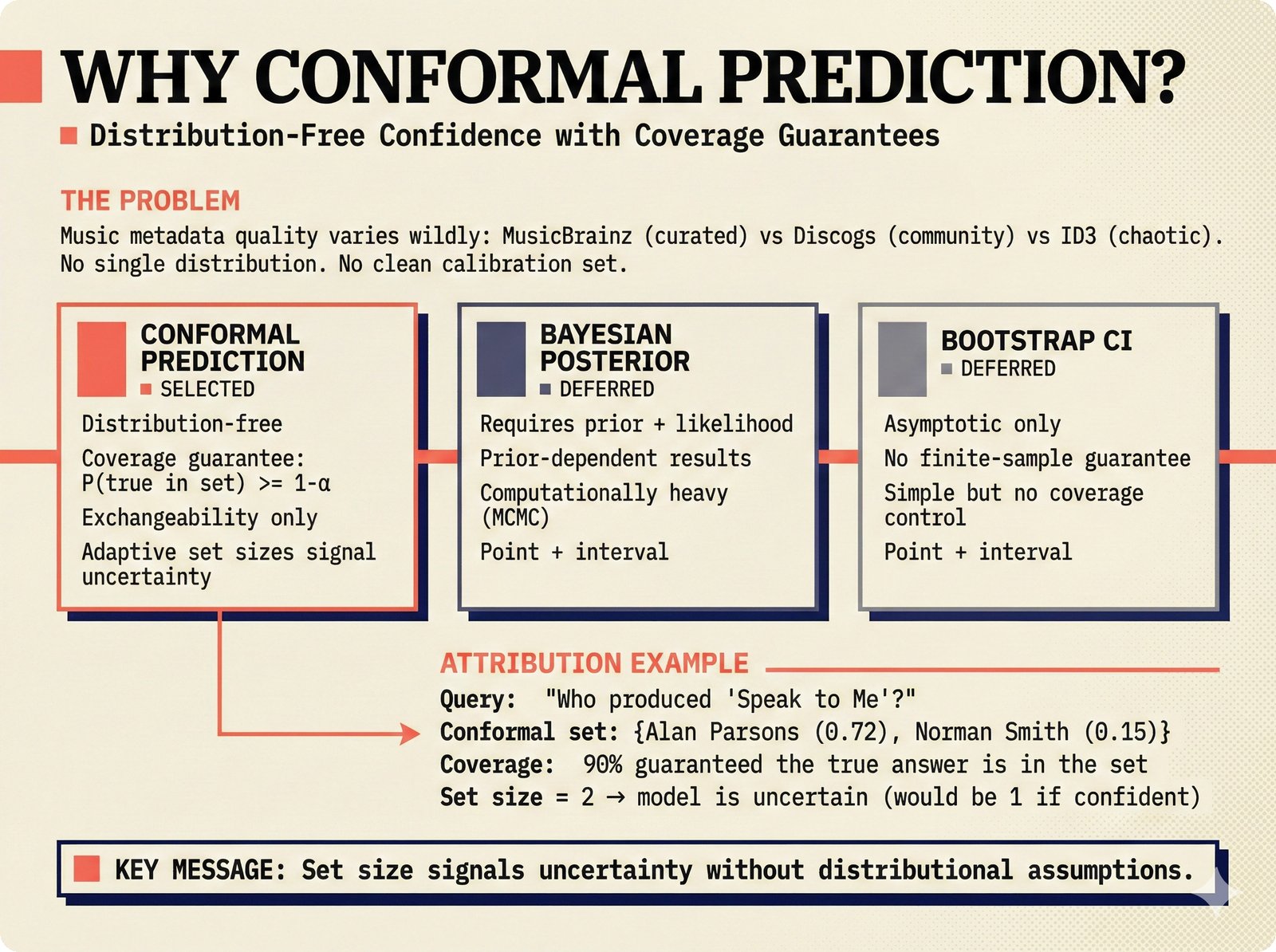 *Conformal prediction: distribution-free coverage guarantees for heterogeneous music metadata where quality varies across sources.* --- 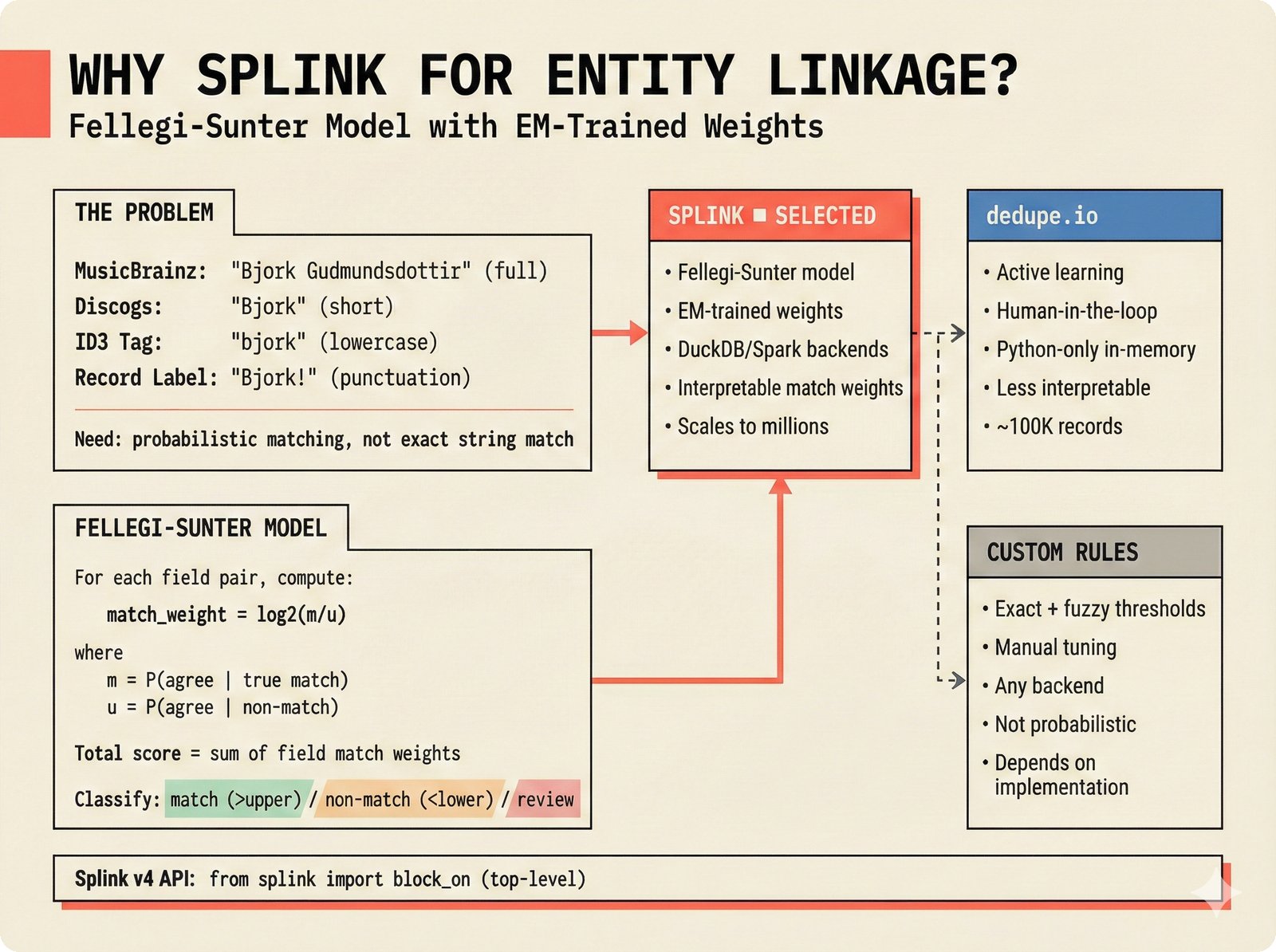 *Splink linkage: Fellegi-Sunter EM-trained match weights for artist identity matching across MusicBrainz, Discogs, and file metadata.* ---  *FastAPI over Django: async-native, Pydantic-integrated, lightweight modular monolith with MCP streaming support.* --- 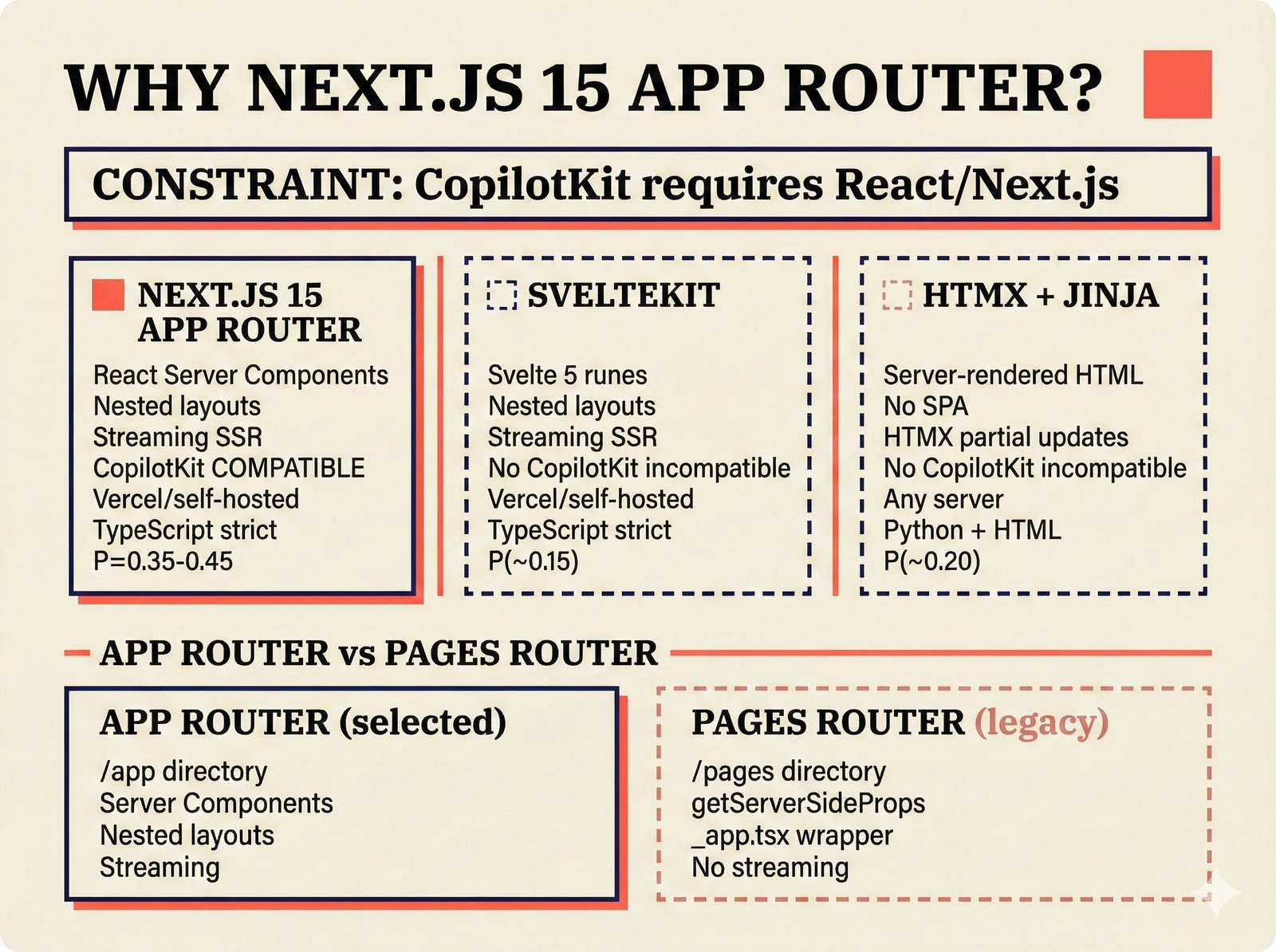 *Next.js App Router: CopilotKit React dependency, server components, and streaming SSR for confidence display.* ---  *Jotai over Redux: minimal two-line atom definitions for theme, role mode, and works state with zero boilerplate.* --- 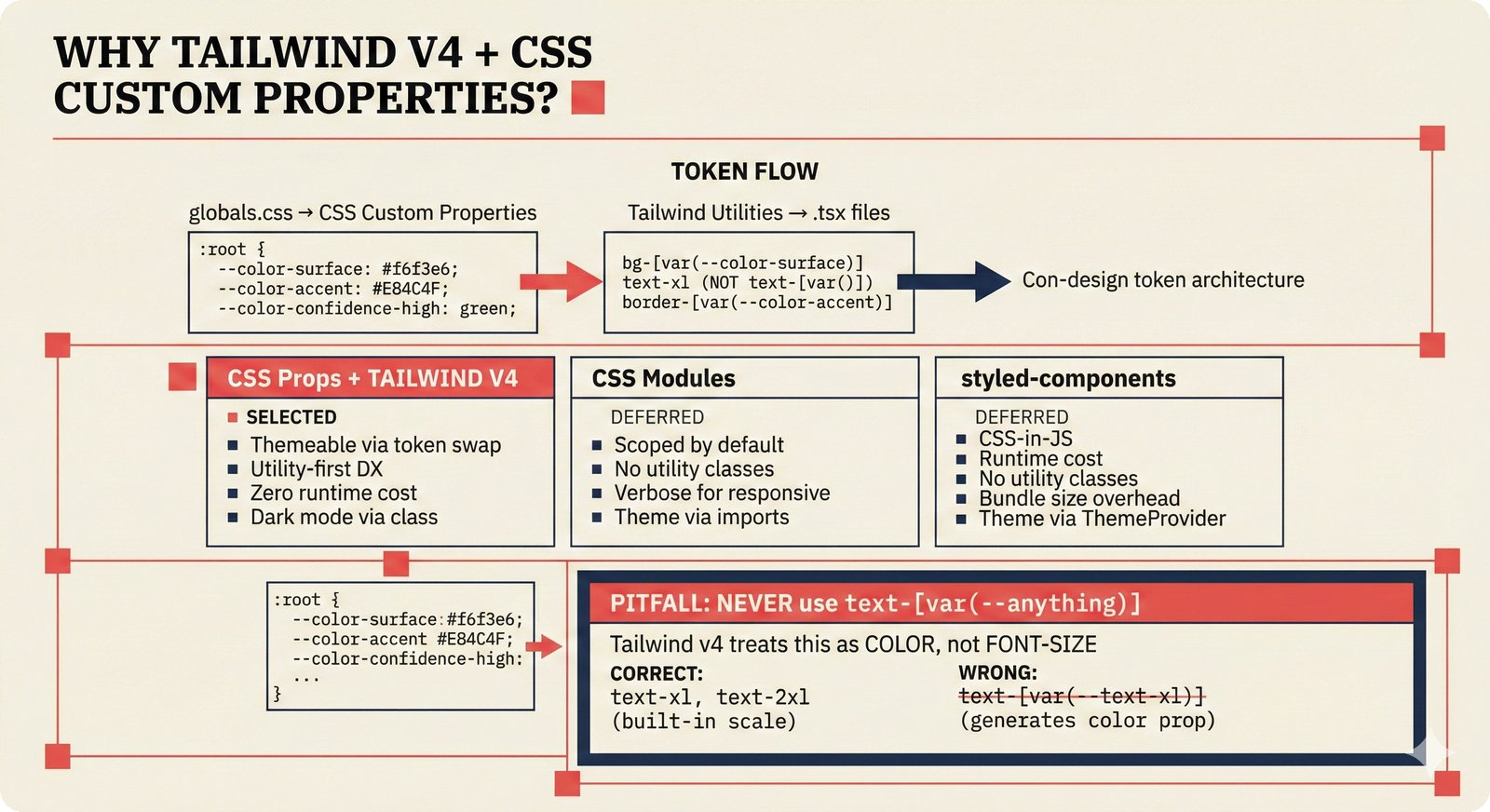 *Tailwind v4 CSS properties: zero-hardcoded-hex color tokens with critical text-[var()] pitfall warning.* ---  *uv over pip: 100x faster Rust-based resolution, deterministic lockfiles, native dependency groups -- pip and conda banned.* ---  *MCP permissions: machine-readable AI training consent queries replacing ambiguous license text with structured allow/deny responses.* --- 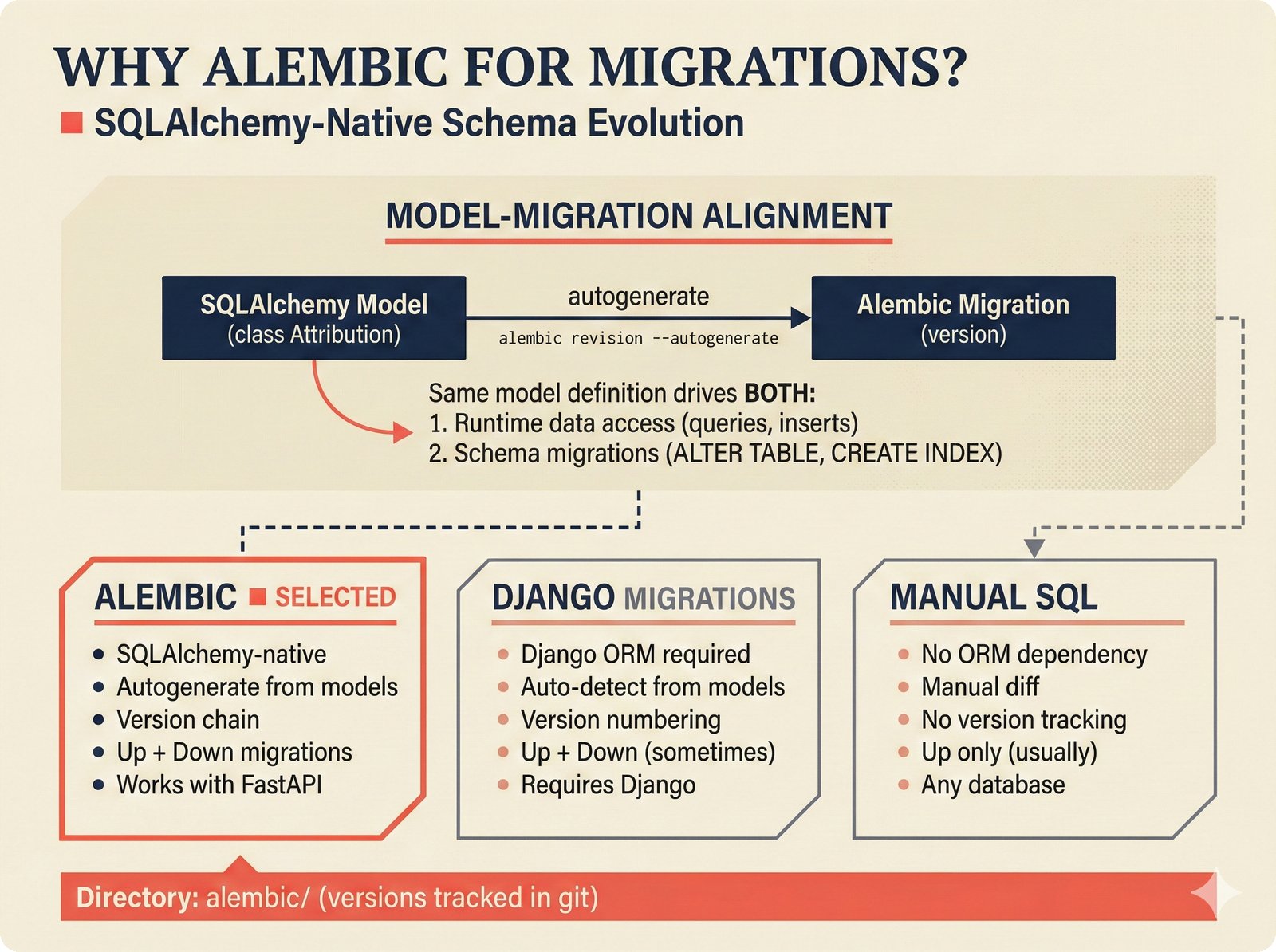 *Alembic migrations: SQLAlchemy-native autogeneration for version-controlled schema evolution.* ---  *tinytag over mutagen: BSD-3 preserves permissive licensing while providing read-only ID3, FLAC, and MP4 tag support.* ---  *PostHog plus Sentry: typed product analytics and error tracking -- Highlight.io deprecated, Datadog cost-prohibitive.* --- 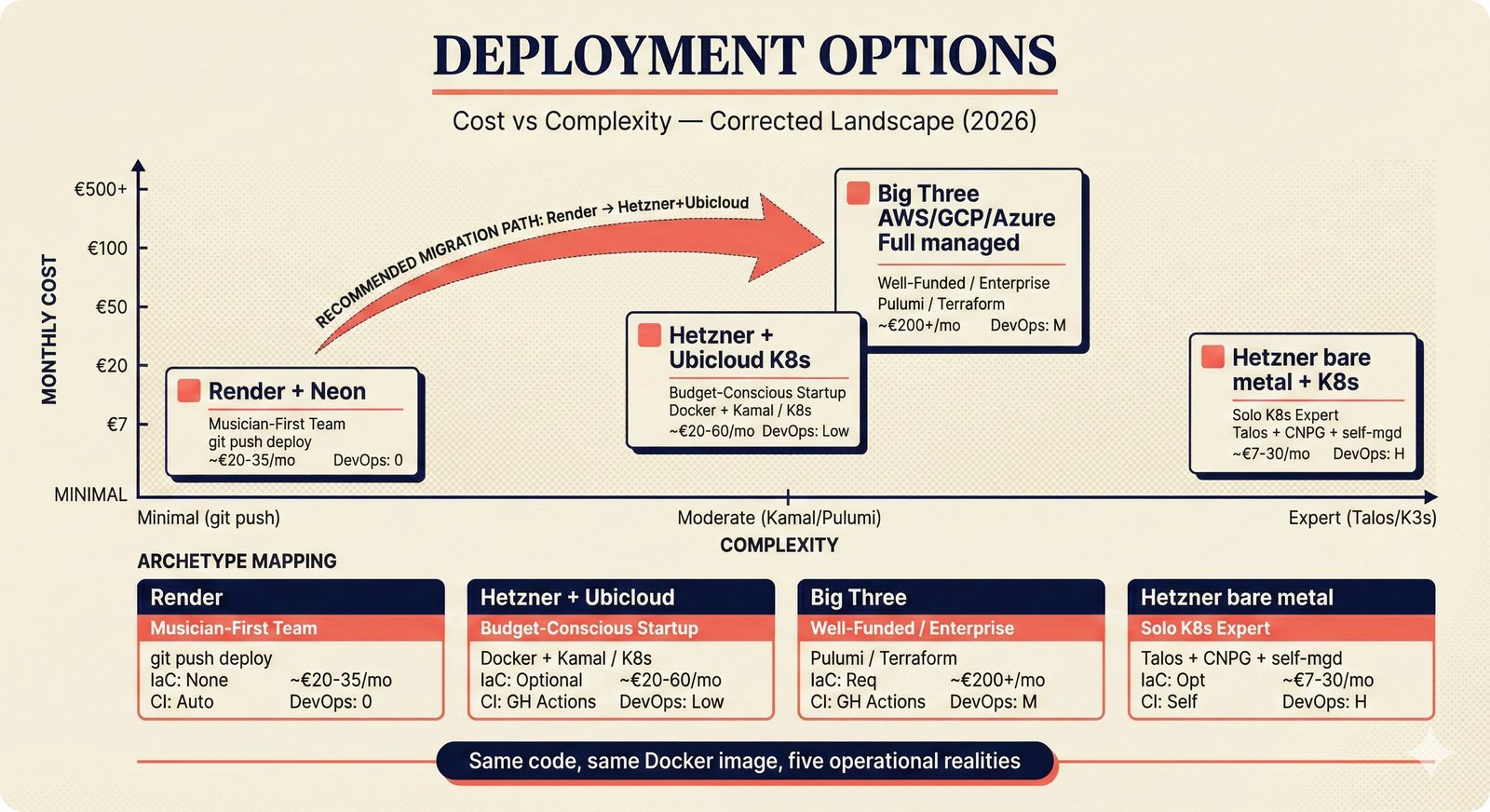 *Deployment options: Render (simplest), Hetzner+Ubicloud (recommended), Big Three hyperscalers, and bare-metal Kubernetes.* ---  *Object storage: R2 at $0 egress versus S3 at $9,000/month at 100TB -- critical FinOps for audio-heavy workloads.* ---  *Pulumi over Terraform: Python-native IaC, official MCP server for Claude deployments, Apache 2.0 versus HashiCorp BSL.* --- 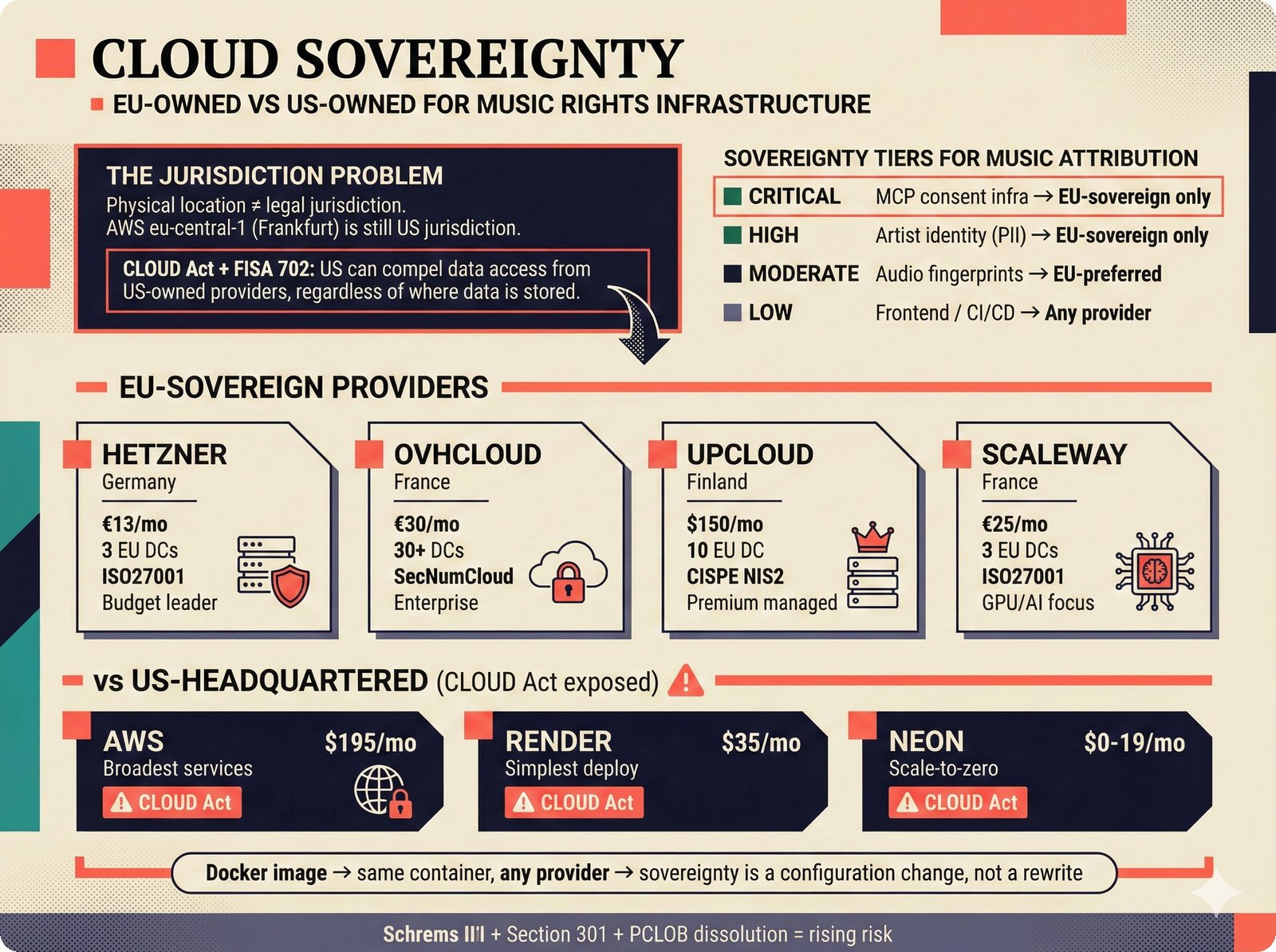 *Cloud sovereignty: Hetzner, OVHcloud, UpCloud, Scaleway versus CLOUD Act/FISA-exposed providers with four sovereignty tiers.*PRD Decision Network¶
The probabilistic PRD figures explain the novel decision framework used to capture architecture choices as a Bayesian network rather than fixed specifications. Covers the ELI5 introduction, full network visualization, foundation/integration/operational decisions, node anatomy, team archetypes, domain overlays, versioning history, and scaffold-versus-product distinction.

Probabilistic PRD ELI5: weighted options replace fixed specs, adapting to different team archetypes.

Full decision network: 78 nodes, 131 conditional probability edges, five levels, dual-subgraph (50 core + 28 ecosystem).

Foundation decisions: build vs buy, target market, revenue model, and regulatory posture cascading into architecture.

Integration decisions: Anthropic LLM, PydanticAI routing, CopilotKit agentic UI with conditional probability reinforcement.

Operational decisions: 13 deployment nodes and 14 operations nodes with ecosystem compliance, monitoring, and health.

Decision node anatomy: options with priors, conditional dependencies, archetype weight overrides, volatility, and domain applicability.

Team archetypes: Engineer-Heavy, Musician-First, Solo Hacker, Well-Funded Startup -- each activating different PRD paths.

Domain overlay: music attribution and Digital Product Passport share core pipeline -- differing in sources, assurance levels, and regulation.

PRD versioning timeline: v1.0 (15 nodes) to v3.0 (78 nodes) across ten versions with 28-node ecosystem expansion.

Scaffold vs product: configurable research framework with four archetypes versus deployed production with one fixed architecture.
Ecosystem Integration¶
The ecosystem integration figures map the 28 external-facing nodes in the PRD network -- covering integration archetypes, partnership models, TDA providers, CMO licensing, content ID, platform connectors, metadata registries, agent interop protocols, knowledge graphs, ethical certification, compliance reporting, edge inference, eval frameworks, and strategic ambiguity.
16 figures -- click to expand
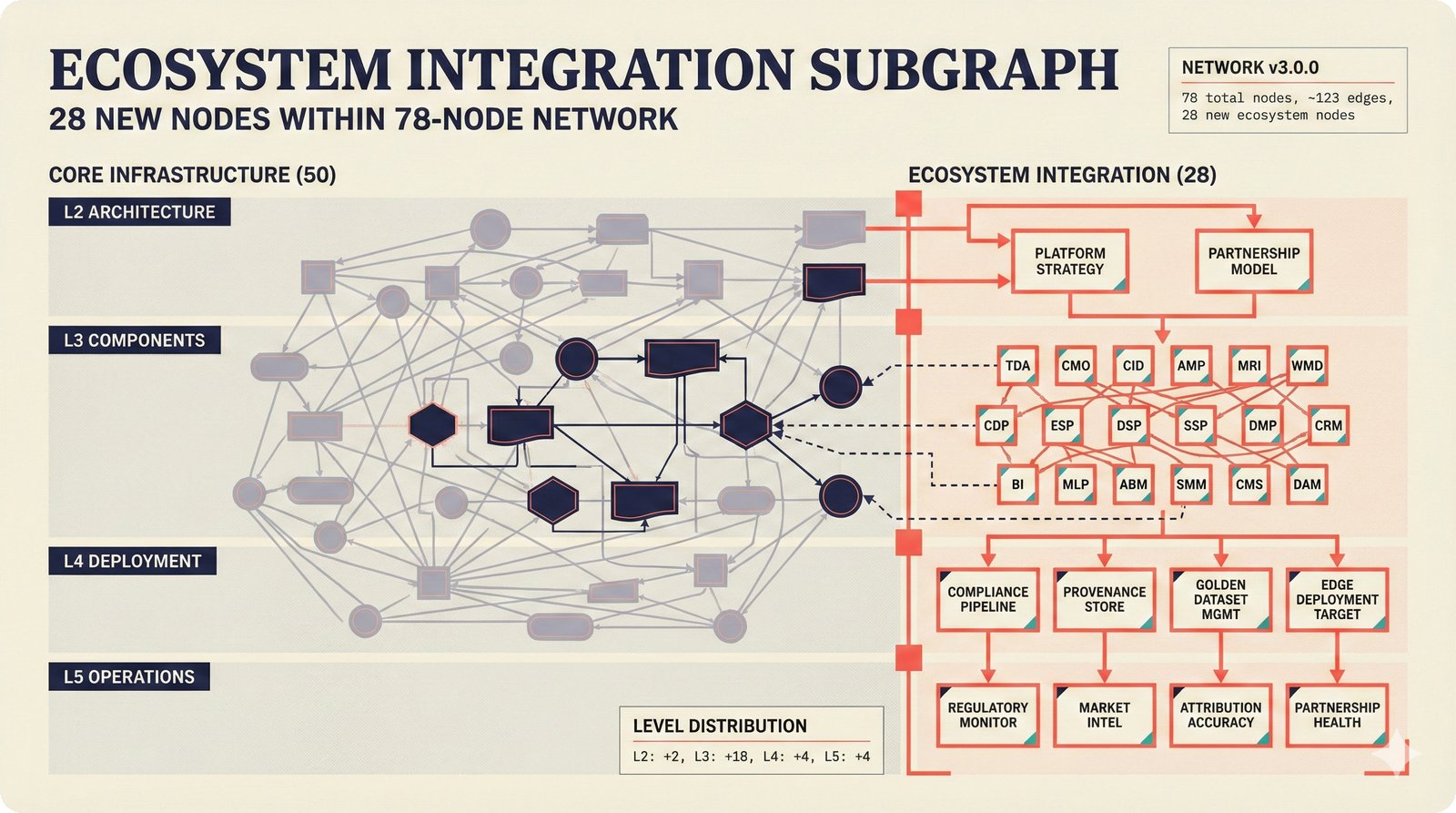 *Ecosystem subgraph: 28 integration nodes within the 78-node PRD network forming a coherent external-facing cluster.* --- 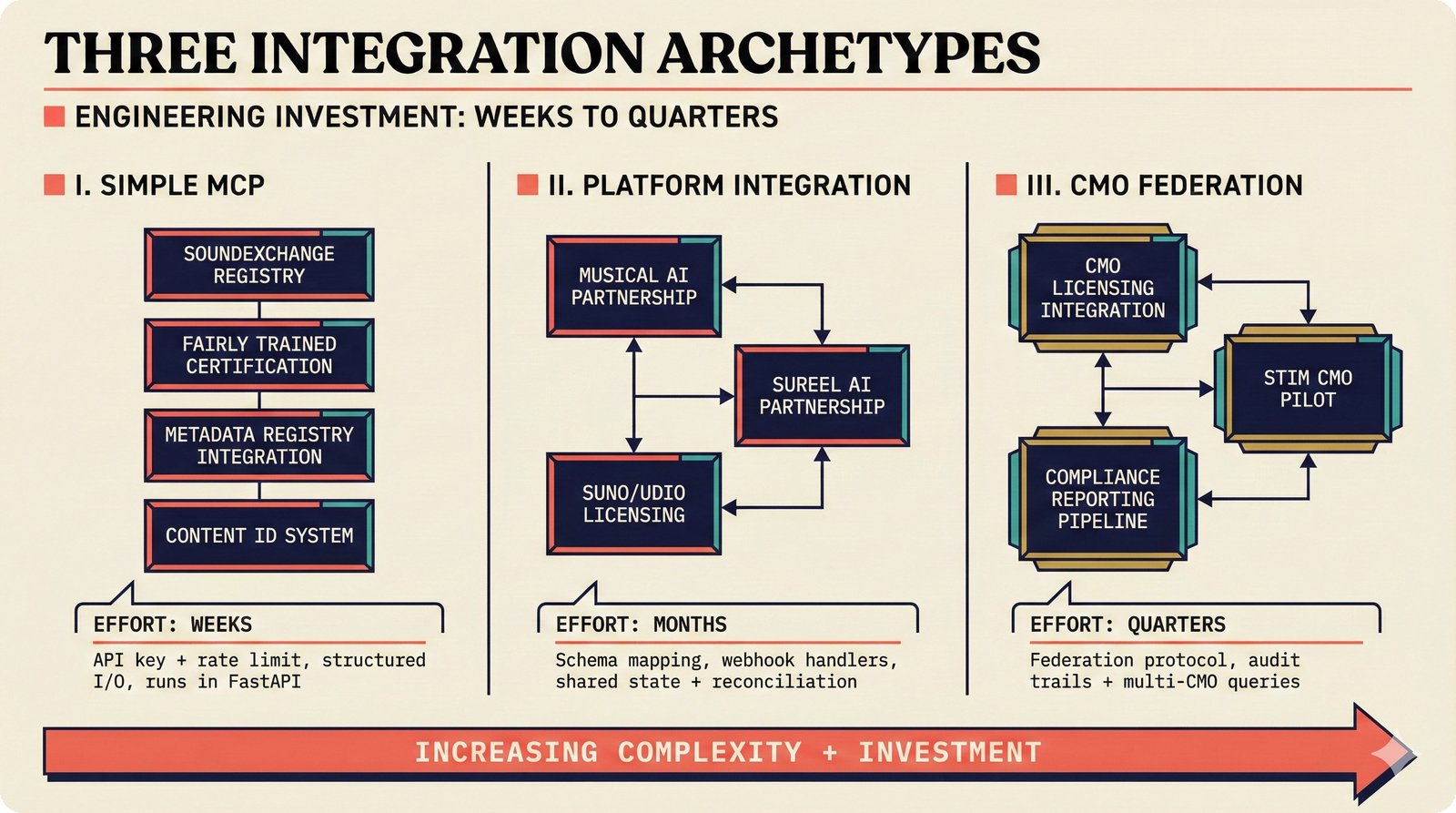 *Three archetypes: Simple MCP adapter, Platform Integration connector, and institutional CMO Federation -- escalating commitment.* --- 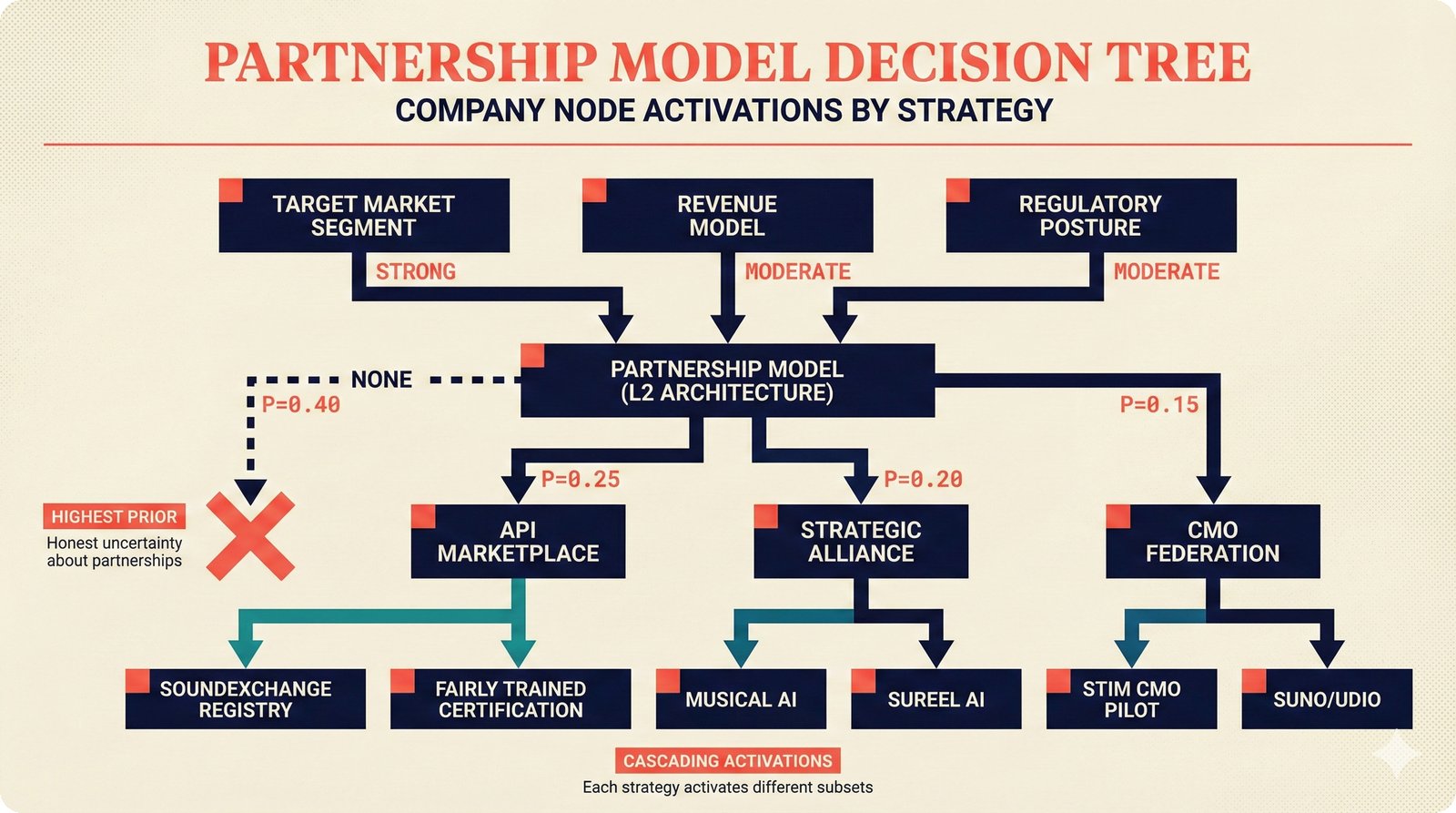 *Partnership model decision tree: cascading from business posture to activation of six specific company nodes.* --- 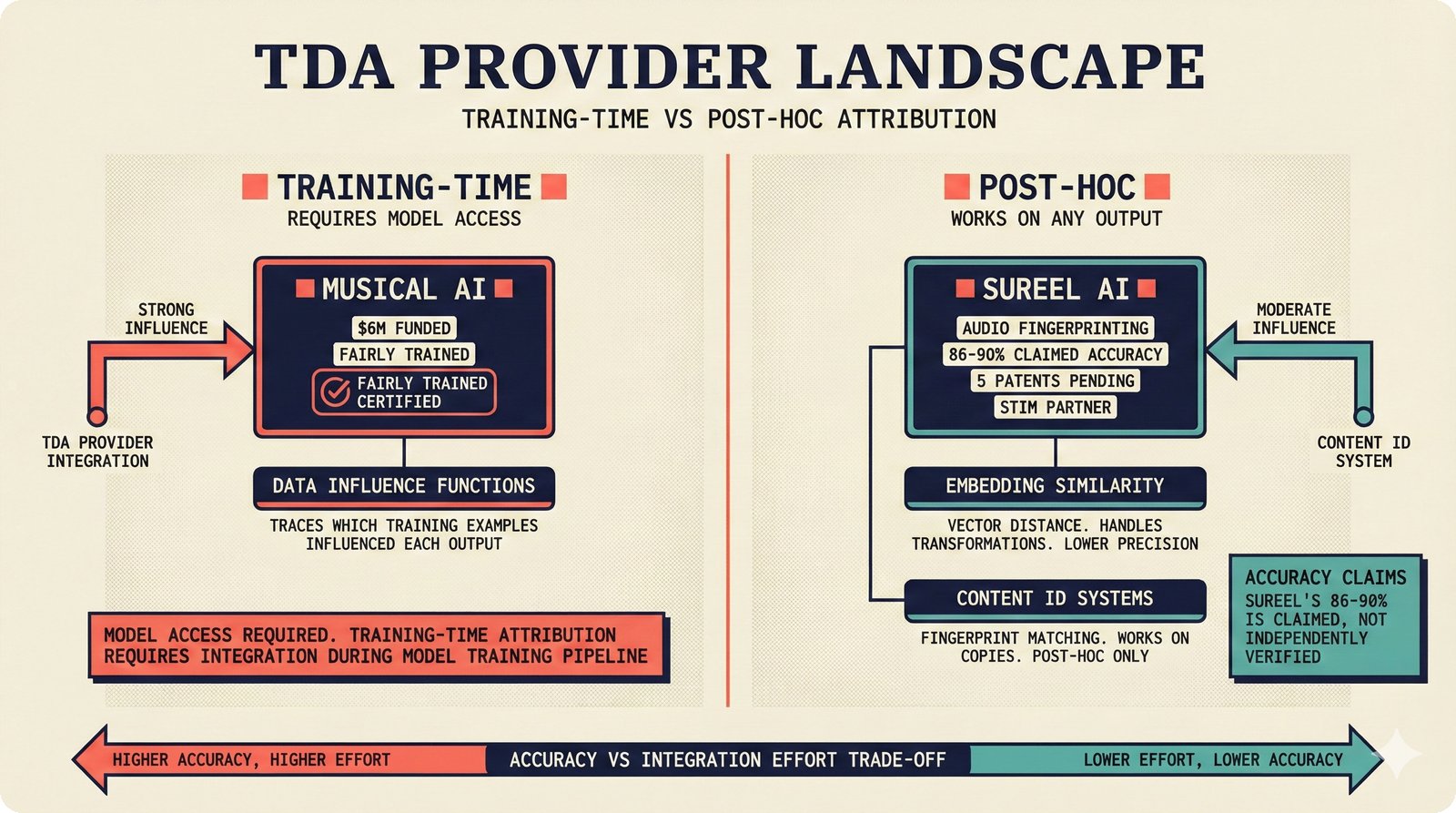 *TDA provider landscape: training-time versus post-hoc attribution approaches with seven methods compared.* --- 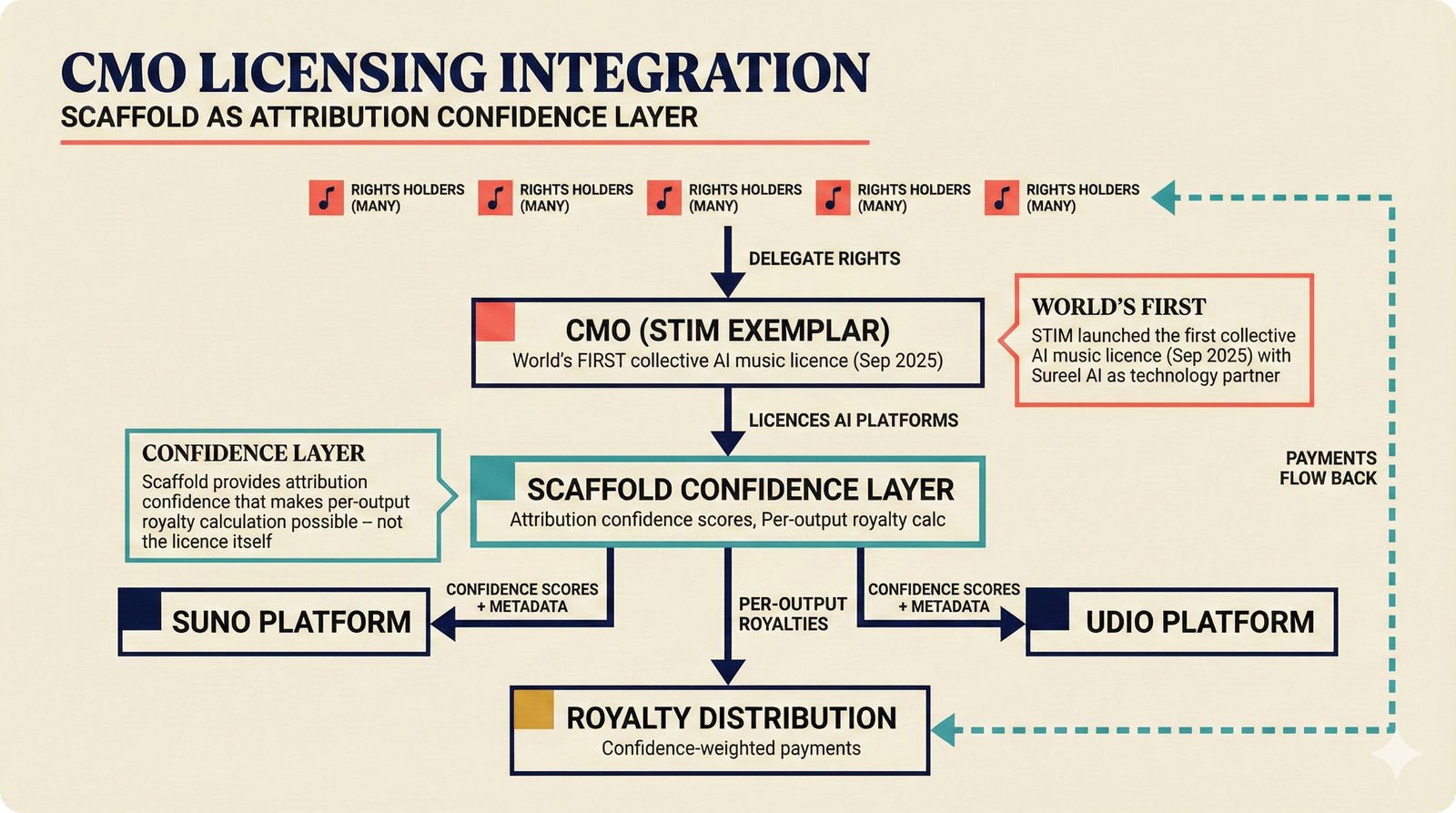 *CMO licensing architecture: scaffold feeds attribution confidence into CMO royalty distribution pipelines.* --- 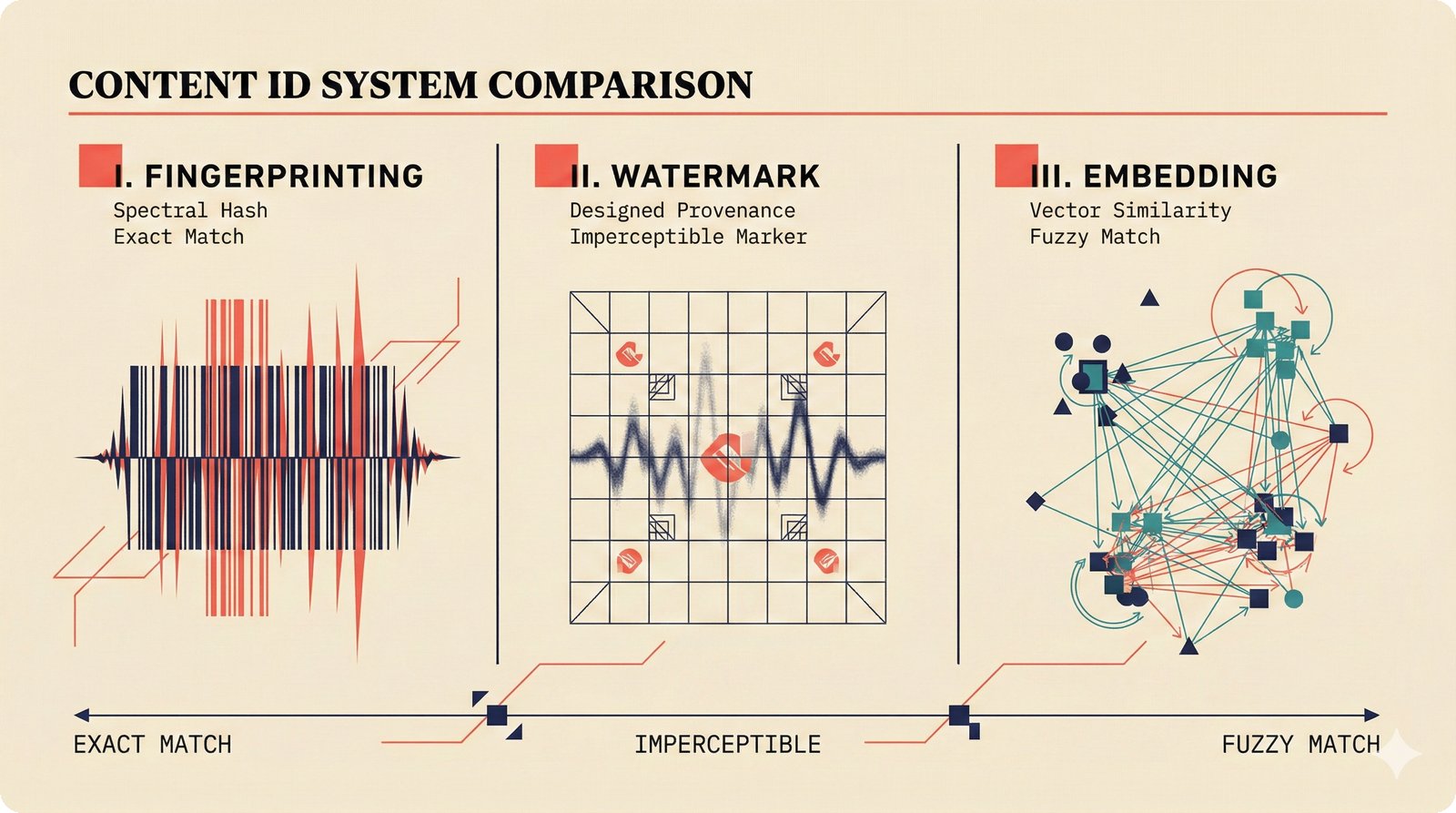 *Content ID comparison: three detection paradigms -- fingerprinting, watermark detection, and embedding similarity.* --- 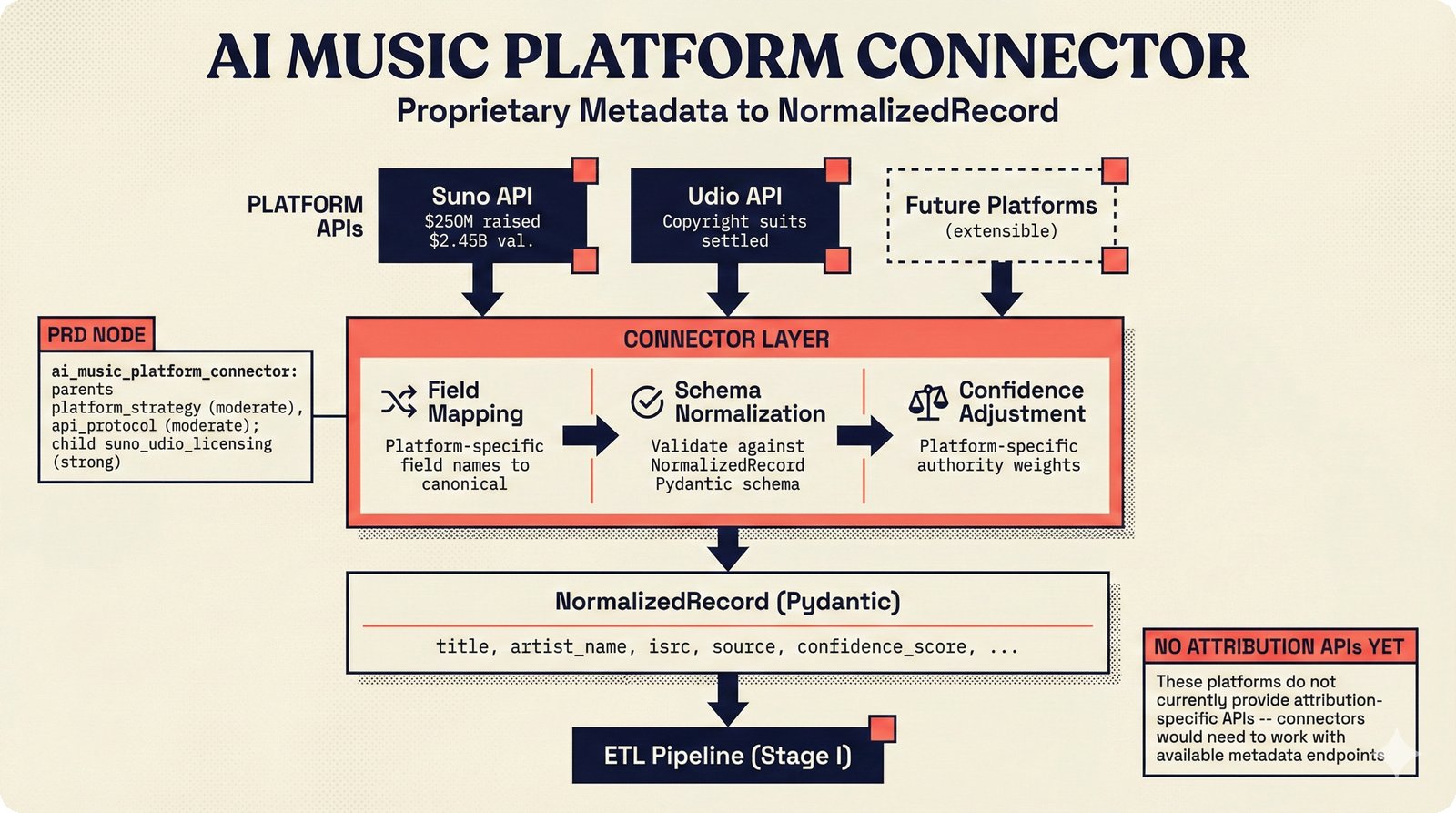 *Platform connector design: normalizing diverse AI music platform metadata into the NormalizedRecord schema.* --- 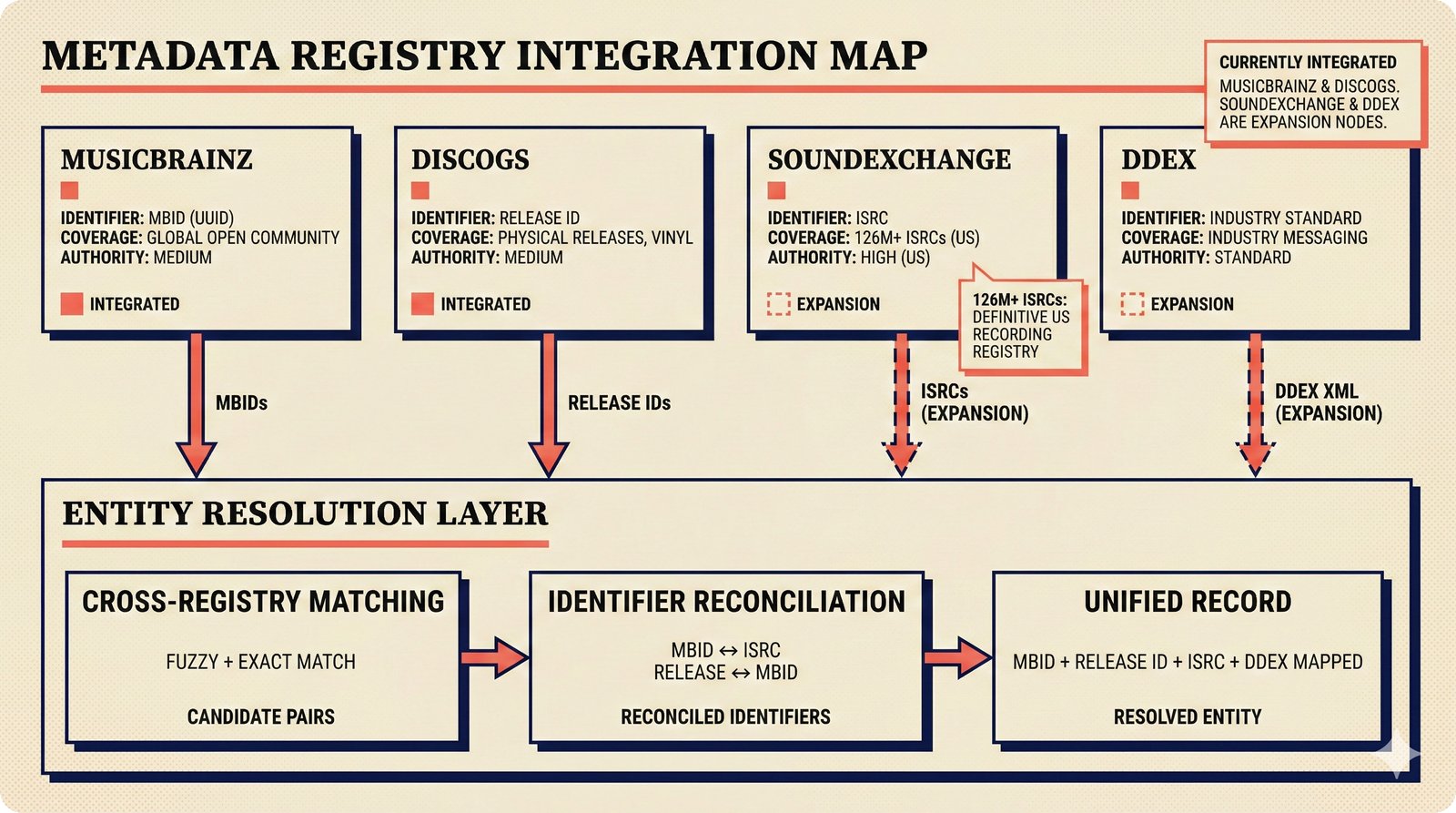 *Metadata registry map: four major registries unified through the entity resolution pipeline.* --- 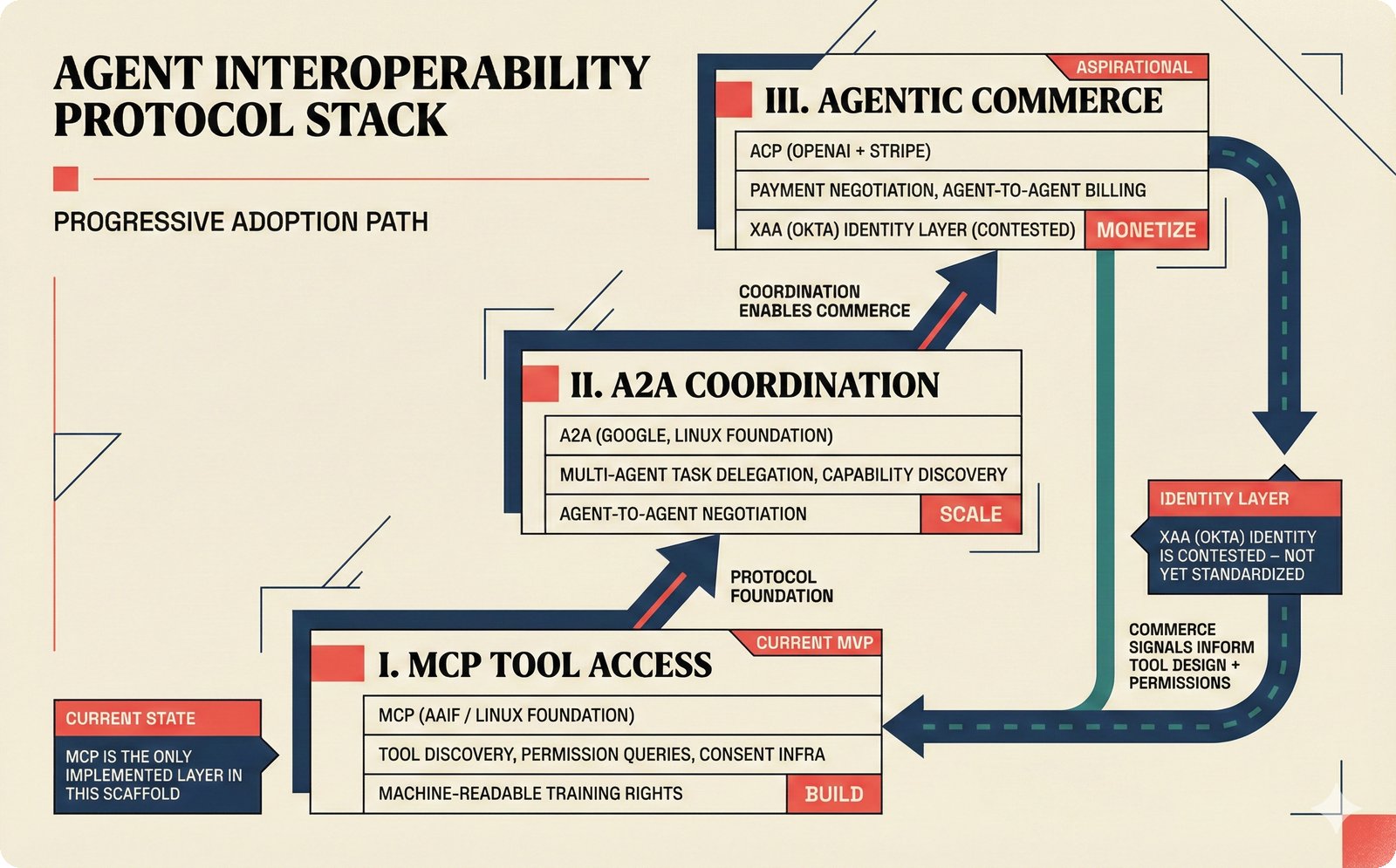 *Agent interop protocol stack: MCP for tool access, A2A for coordination, ACP/TAP for commerce layers.* --- 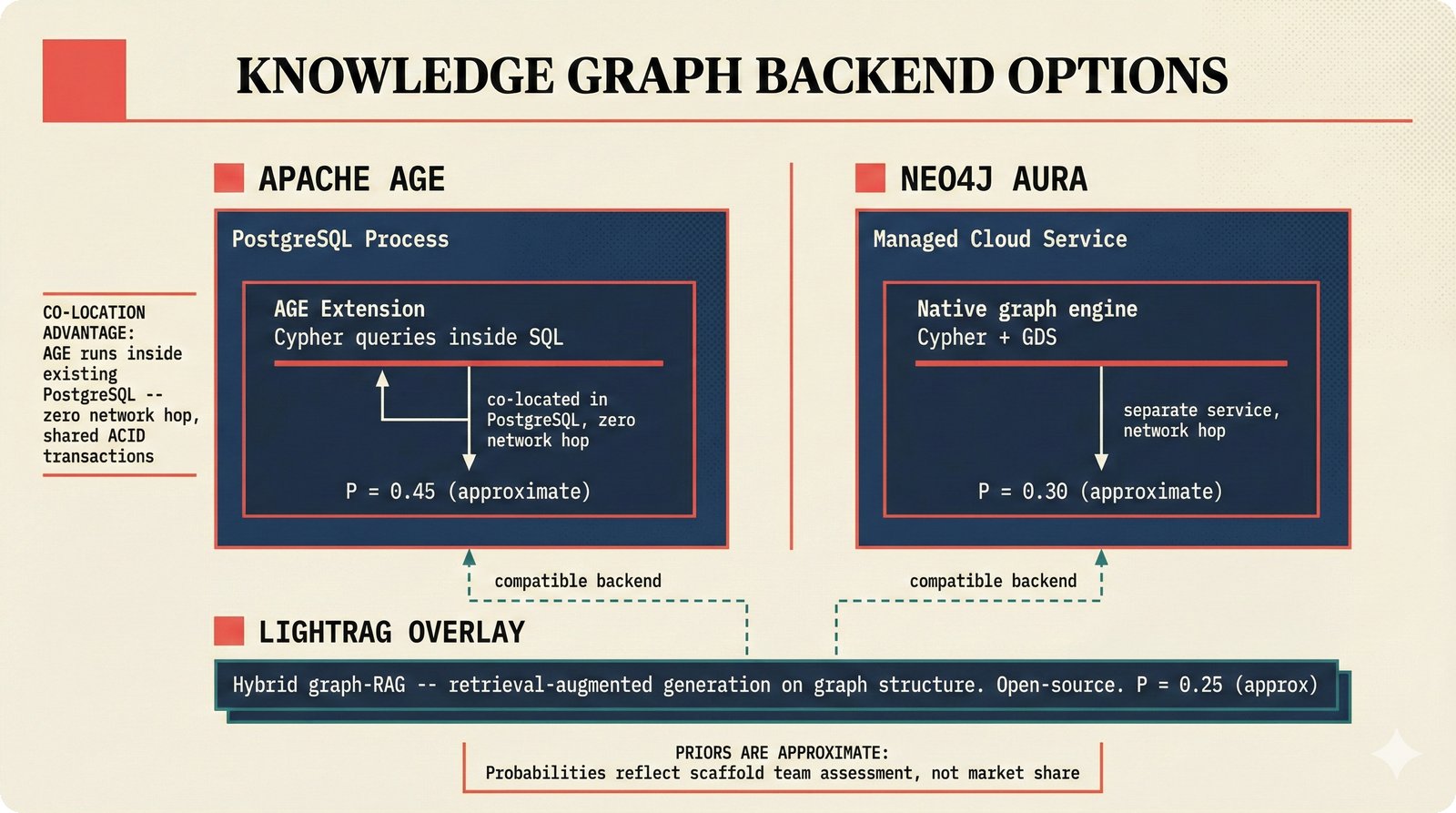 *Knowledge graph options: Apache AGE co-located with PostgreSQL, Neo4j Aura managed, and LightRAG hybrid.* --- 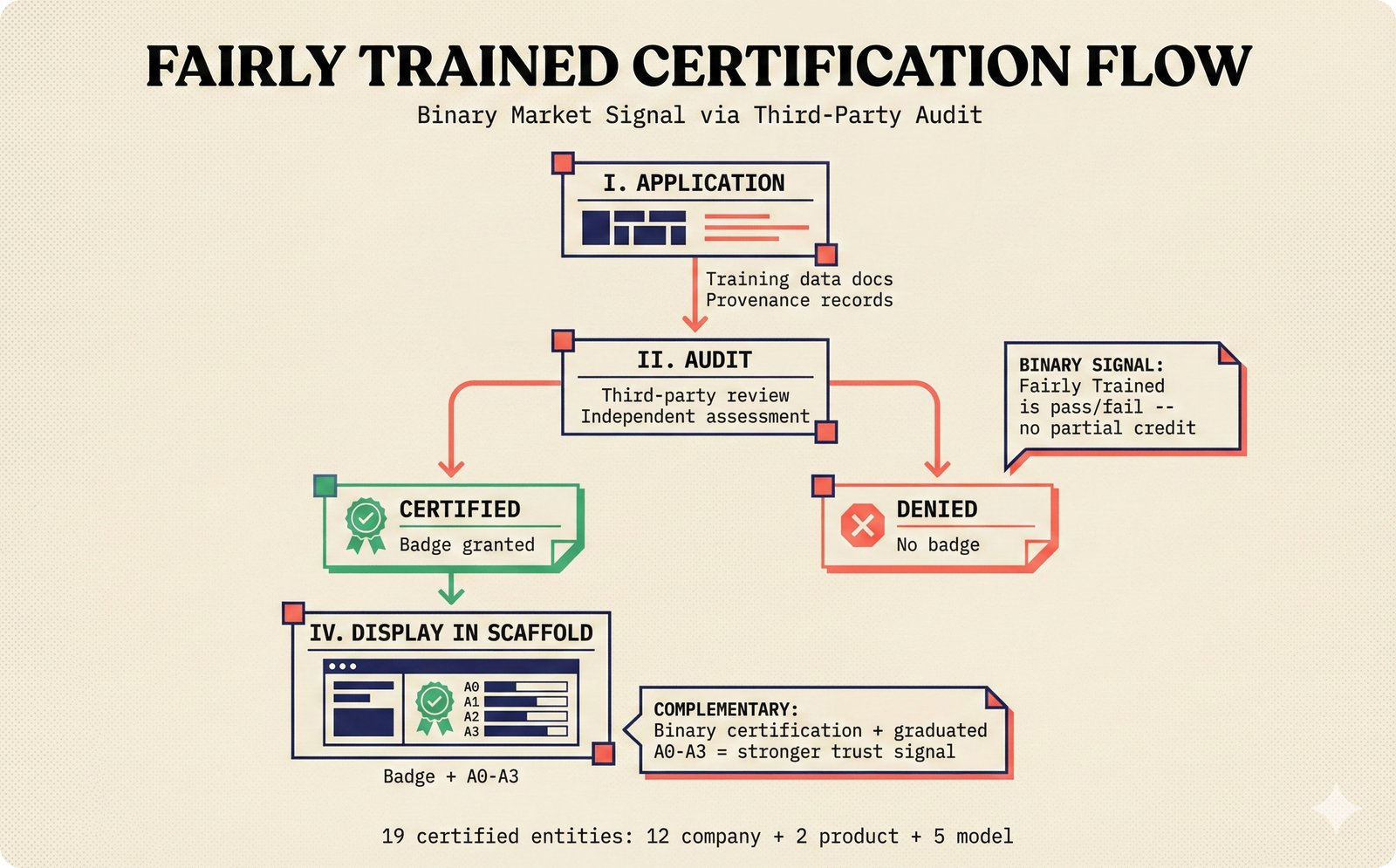 *Fairly Trained certification: binary trained/not-trained audit signal complementing the scaffold's A0-A3 assurance levels.* --- 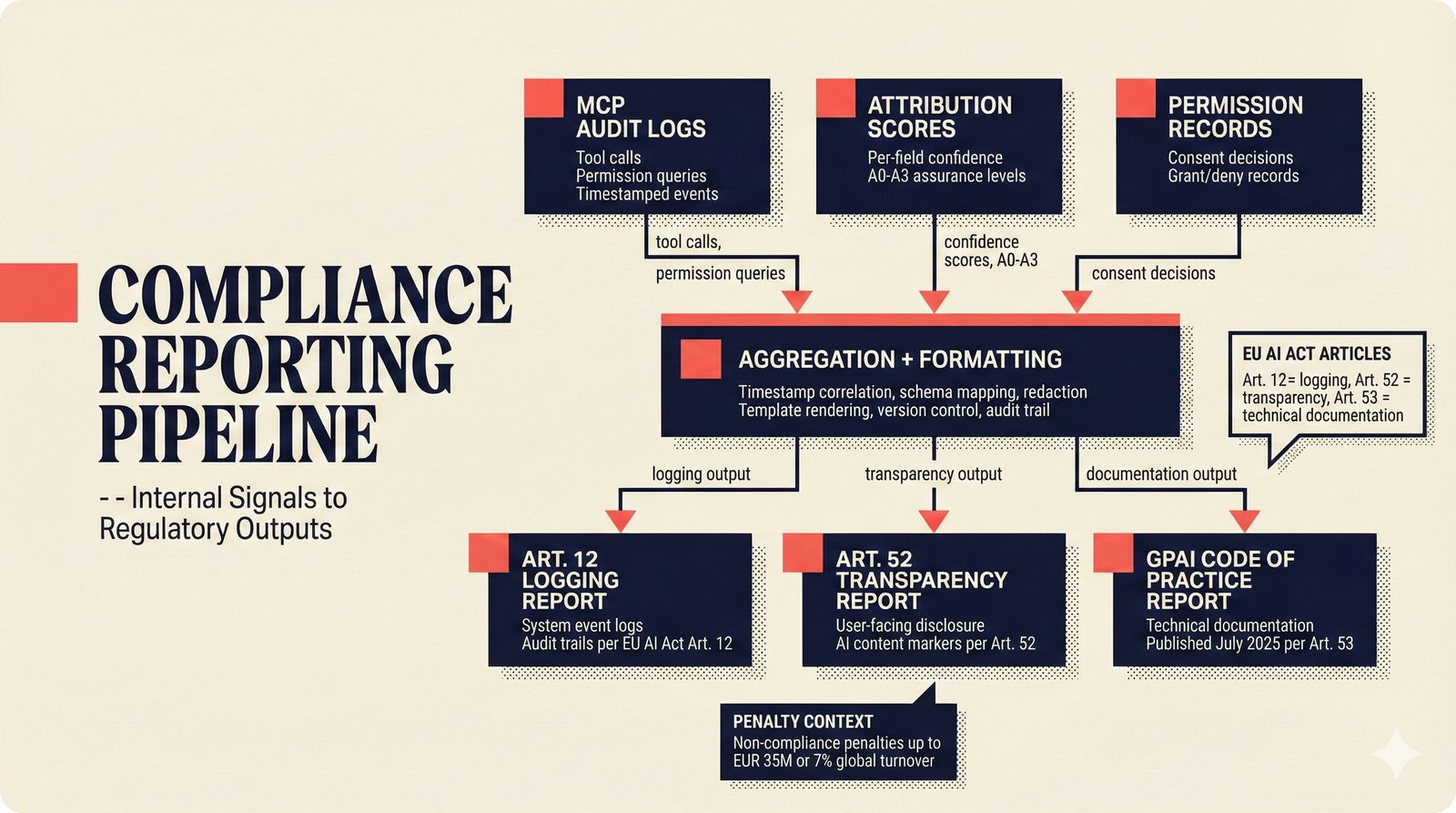 *Compliance reporting: audit logs and confidence scores flowing into EU AI Act transparency reports.* --- 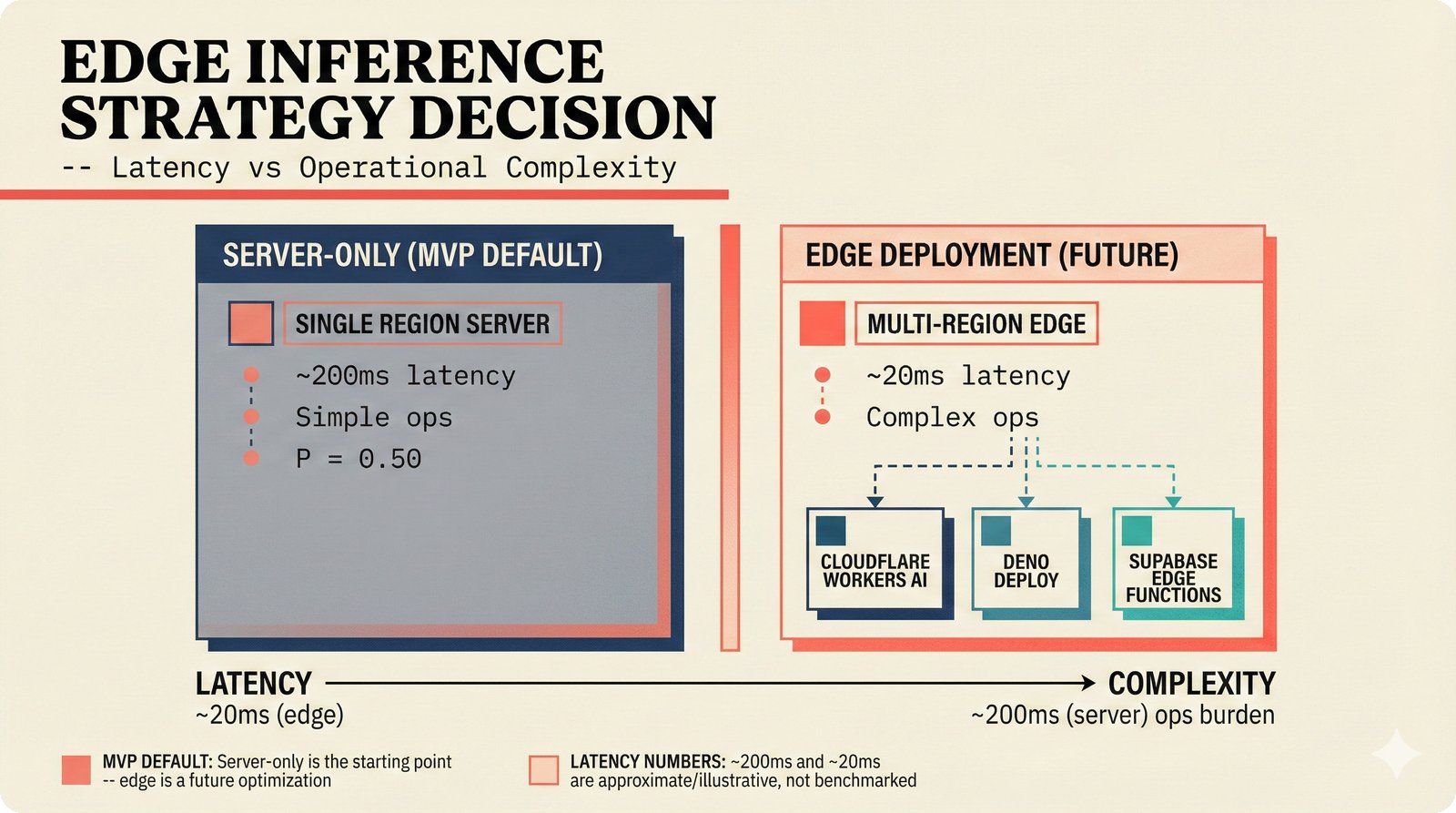 *Edge inference strategy: server-only MVP default with optional edge deployment for latency-sensitive use cases.* --- 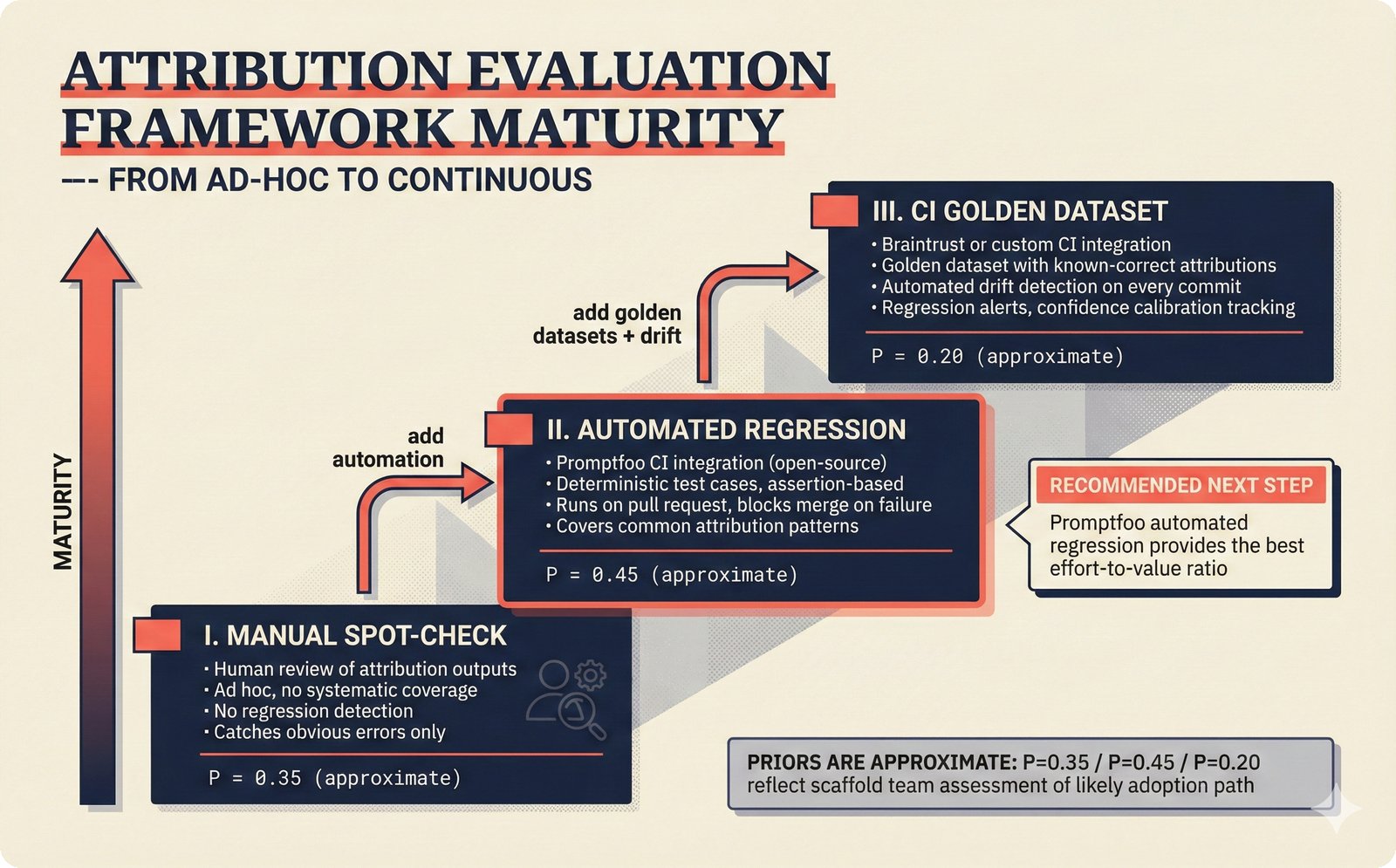 *Eval framework maturity: manual spot-checks, automated regression, CI golden datasets -- three maturity stages.* --- 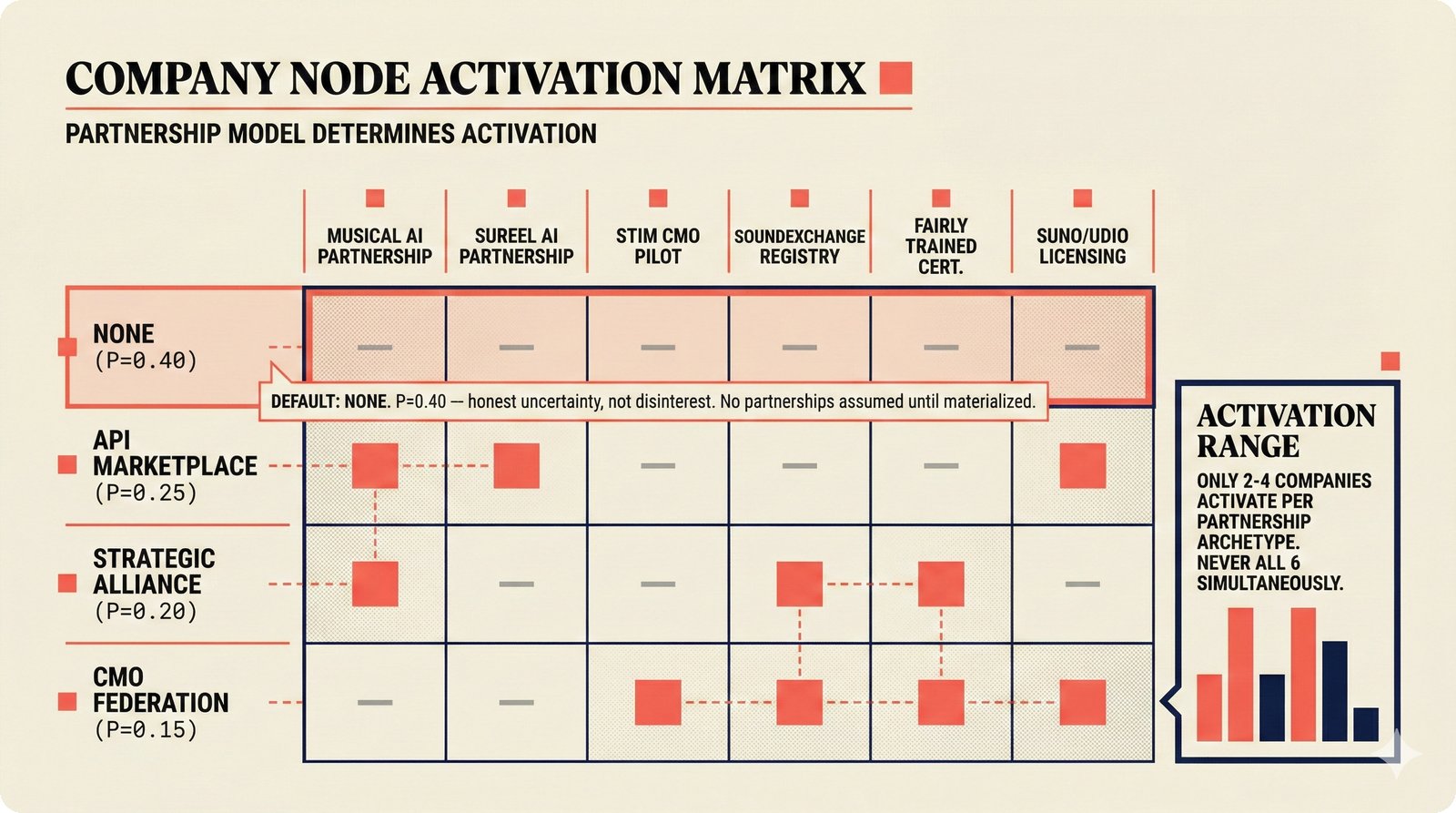 *Company node activation: partnership model determines which of six companies (Sureel, Musical AI, Suno, Udio, STIM, SoundExchange) engage.* --- 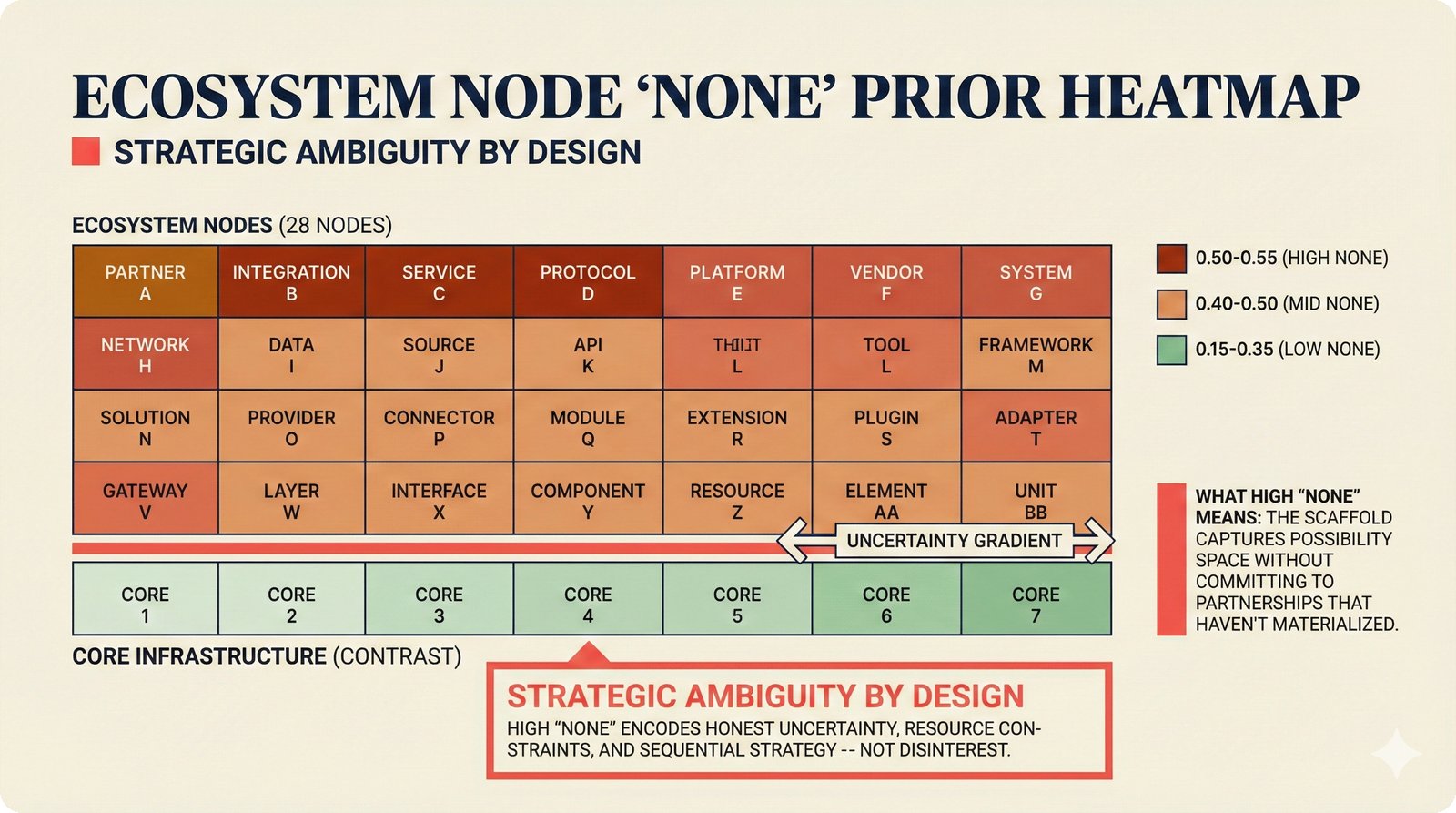 *None-prior heatmap: ecosystem nodes at 0.40-0.55 encode strategic ambiguity -- deliberate optionality, not missing data.*Music AI Landscape¶
The landscape figures provide the broadest context -- mapping the entire music AI field across problem taxonomy, funding patterns, research-to-product gaps, disruption points, maturity spectrum, stakeholder incentives, regulatory fragmentation, TDA methods, watermarking robustness, content ID evolution, licensing models, and research priorities.
33 figures -- click to expand
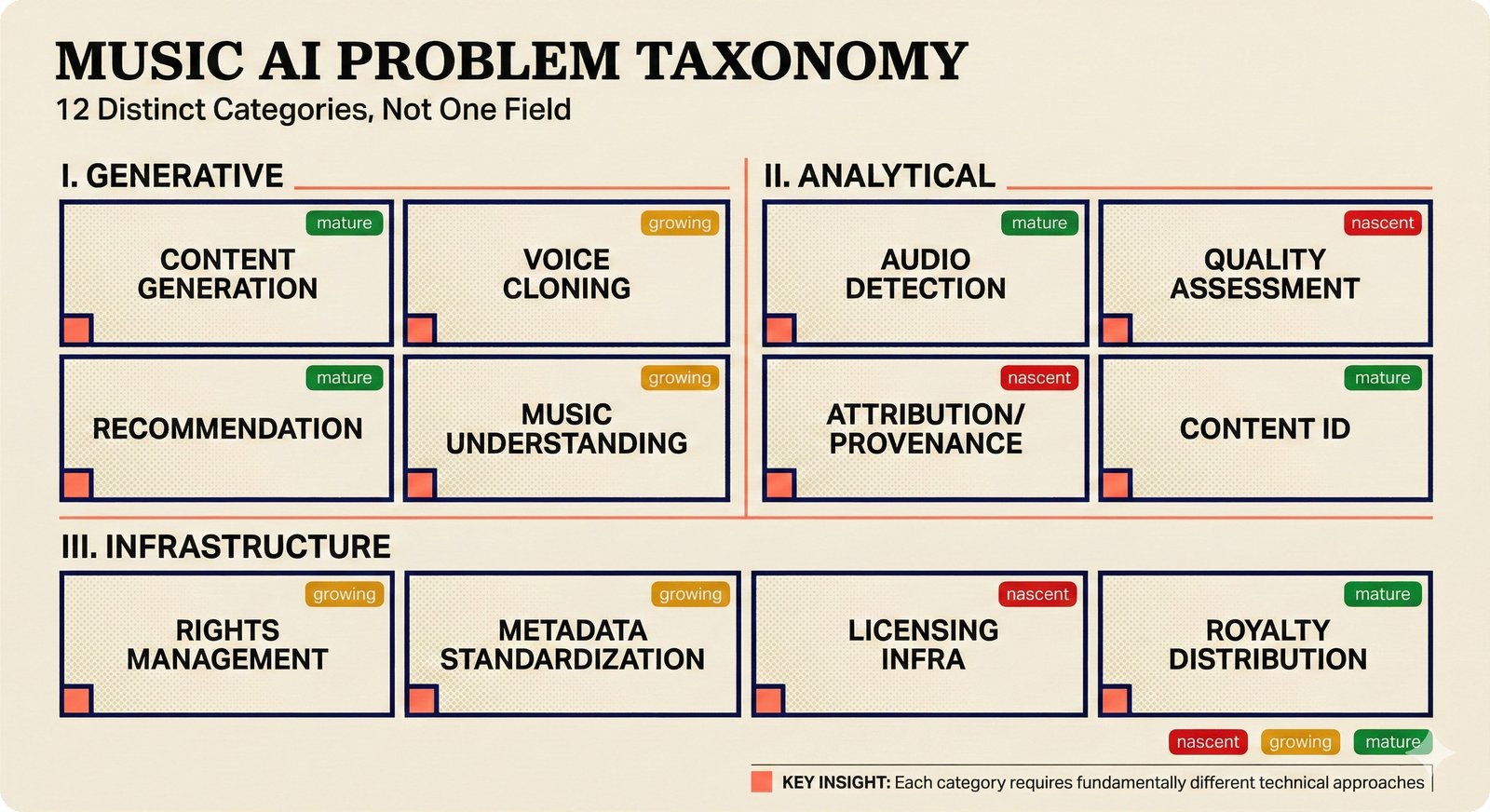 *Problem taxonomy: 12 music AI categories in generative, analytical, and infrastructure groups -- each with distinct maturity levels.* --- 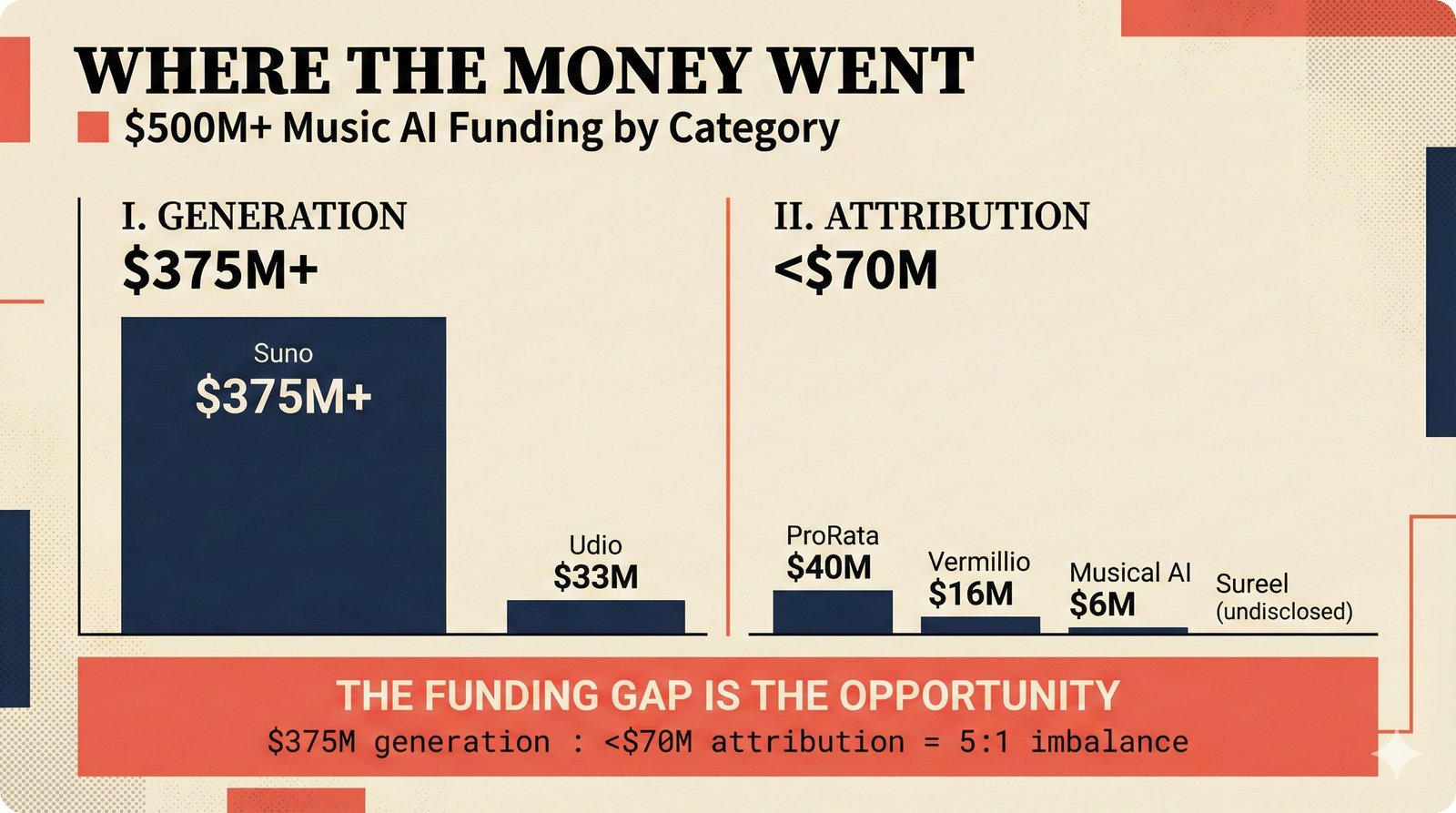 *Funding by category: $375M+ to generation versus under $70M to attribution -- a 5:1 investment gap.* --- 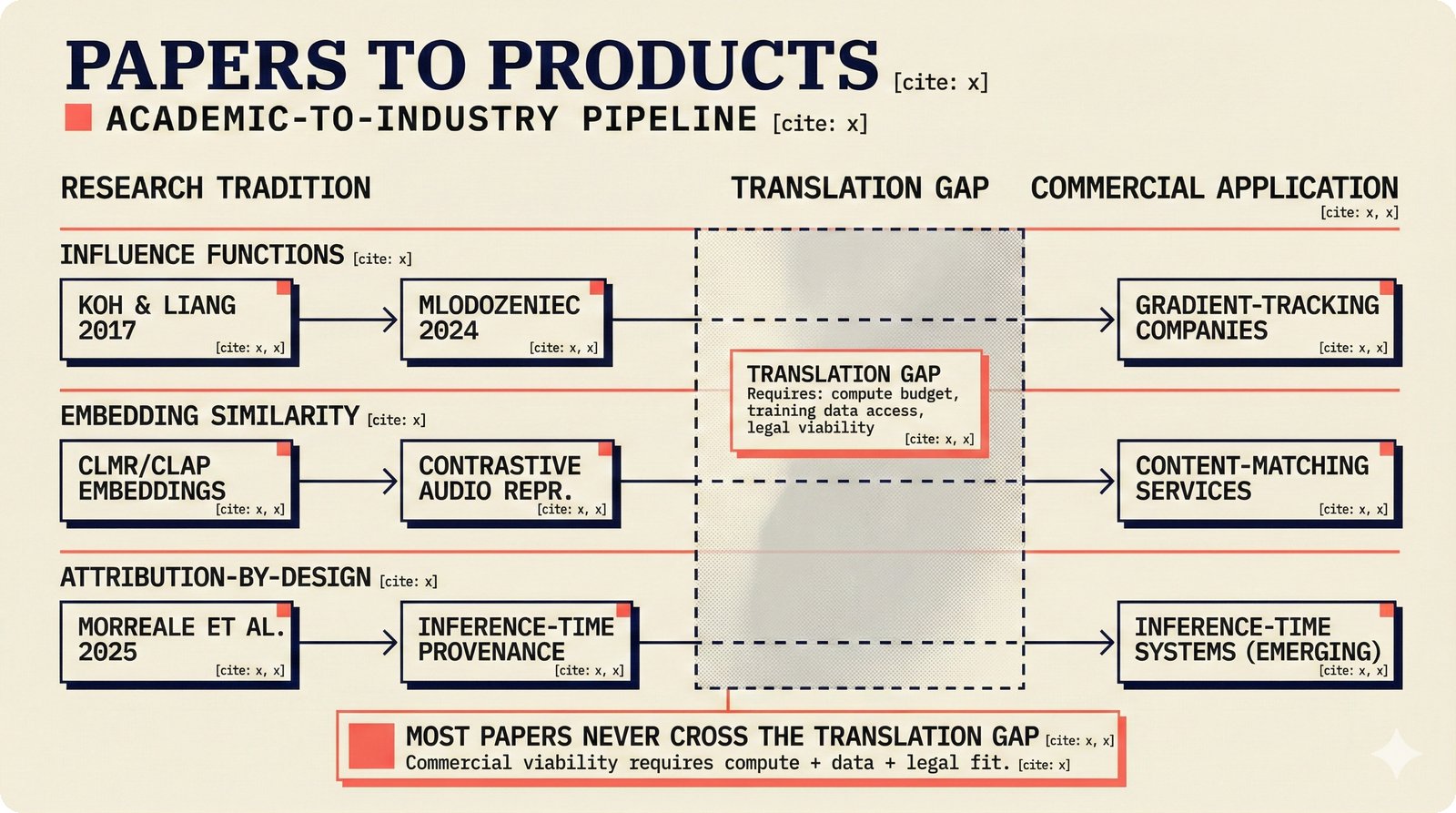 *Papers to products: influence functions, embeddings, and attribution-by-design streams bridging the research-to-product gap.* --- 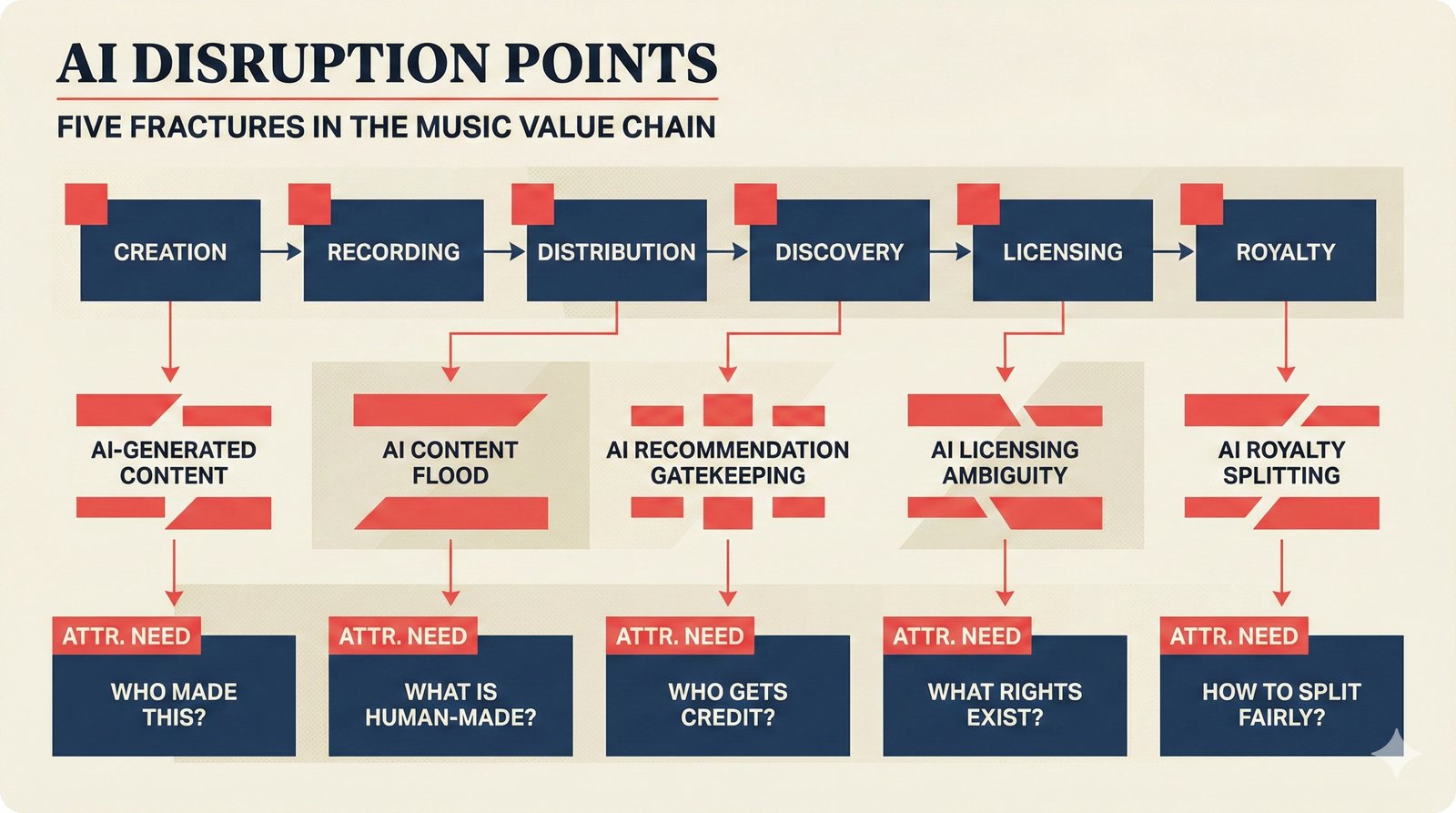 *Disruption points: five places in the music value chain where AI creates new attribution questions.* --- 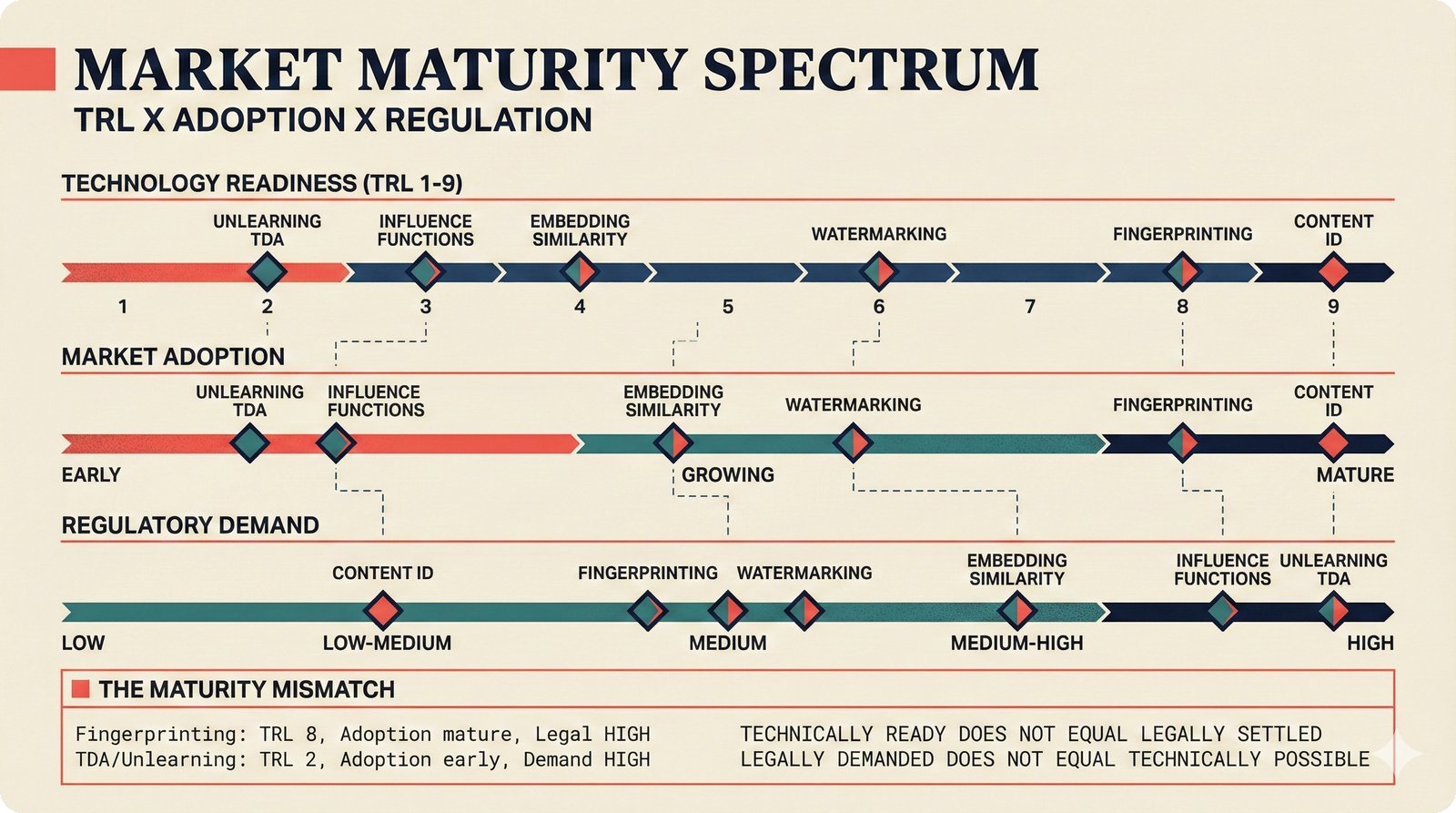 *Maturity spectrum: six approaches mapped by technology readiness, industry adoption, and regulatory pressure.* --- 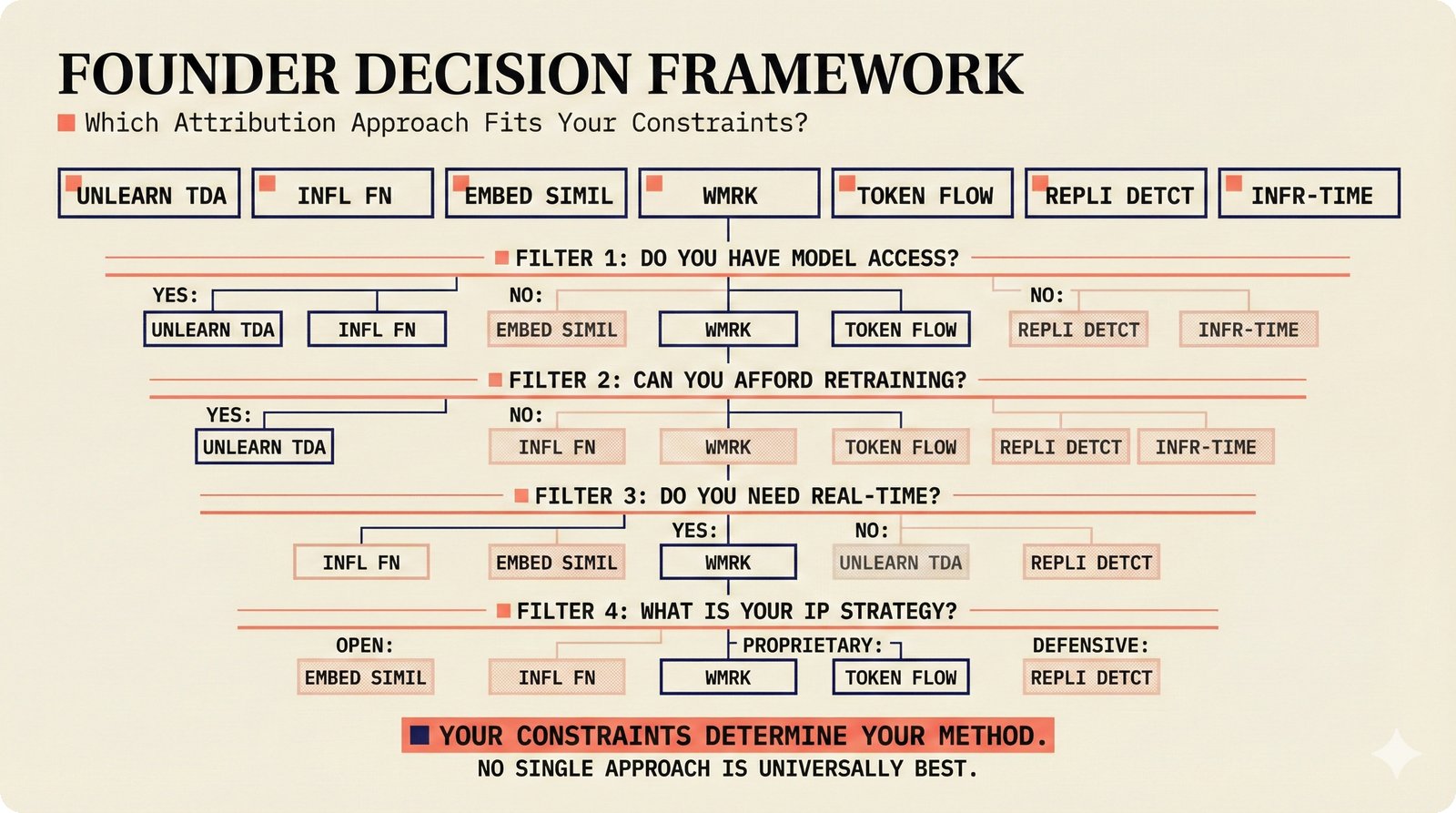 *Founder decision framework: seven methods through four constraint filters yielding one to two viable approaches.* --- 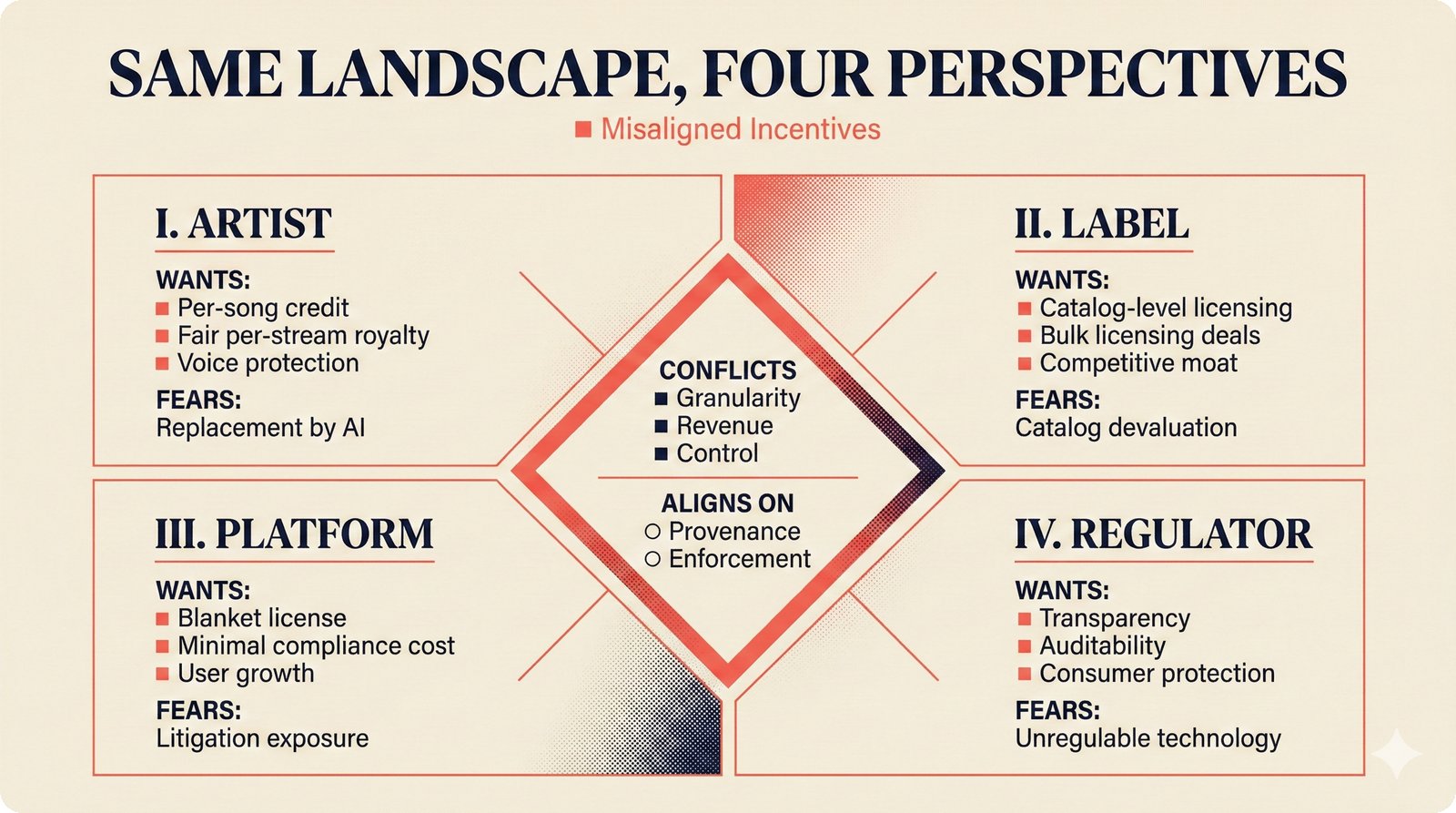 *Misaligned incentives: artists want credit, labels want control, platforms want scale, regulators want transparency.* --- 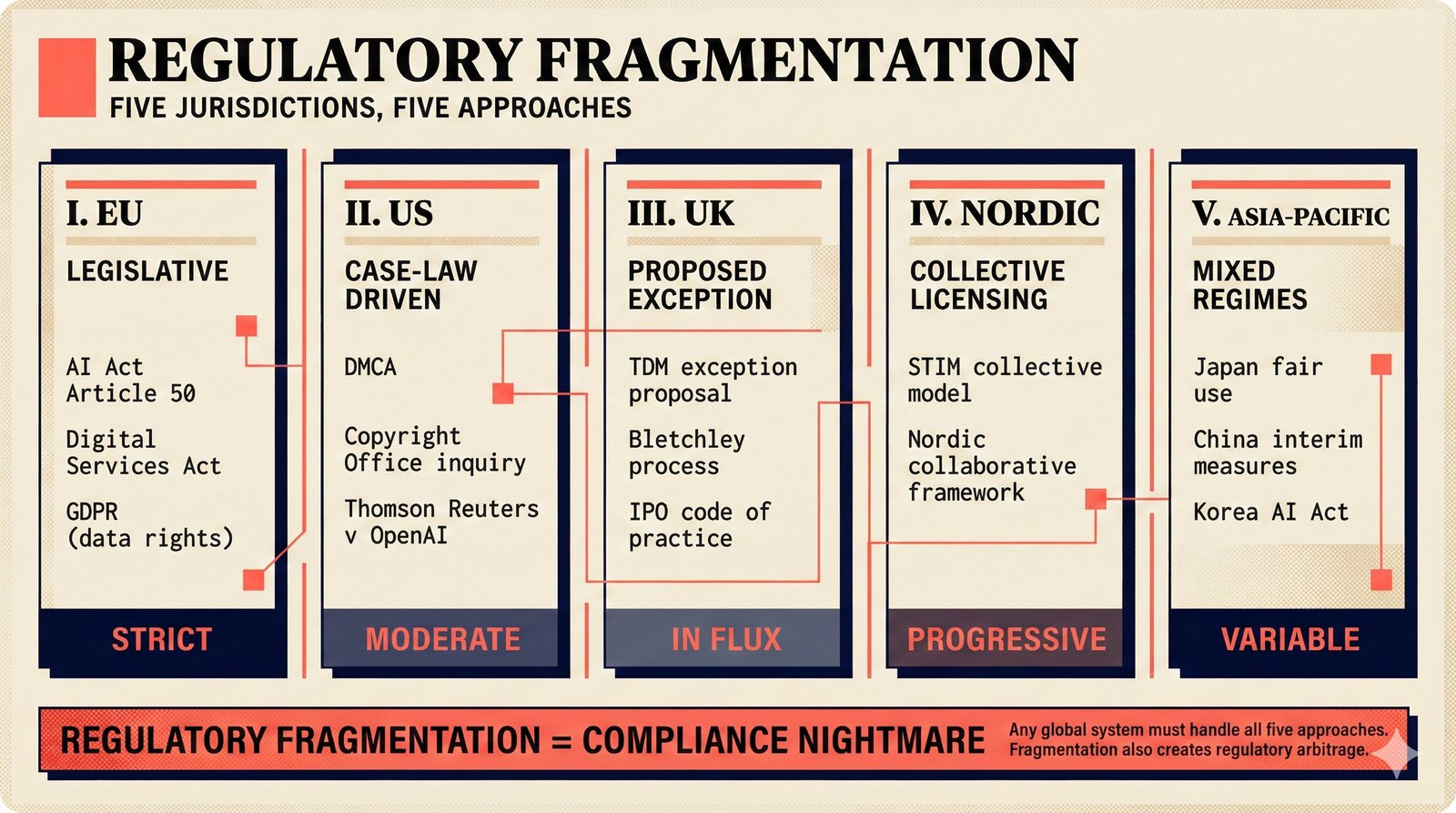 *Regulatory fragmentation: five jurisdictions with incompatible approaches -- EU AI Act, US copyright, UK code of practice.* ---  *Seven TDA methods: influence functions, Shapley values, activation analysis, probing, embedding similarity, watermarking, and provenance -- on a causal-to-corroborative axis.* --- 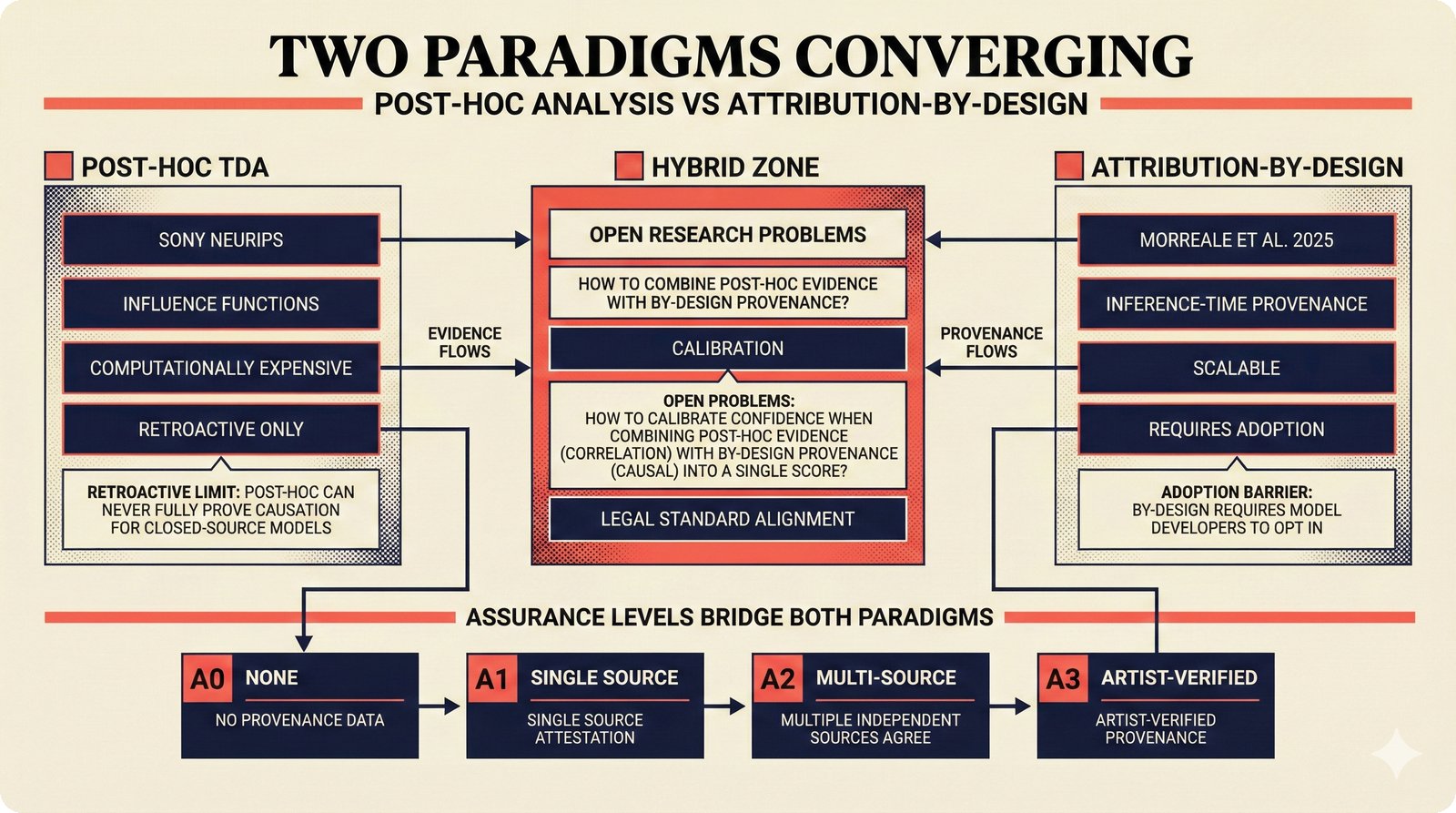 *Two paradigms: post-hoc detection versus attribution-by-design converging at a hybrid zone bridged by A0-A3 assurance.* --- 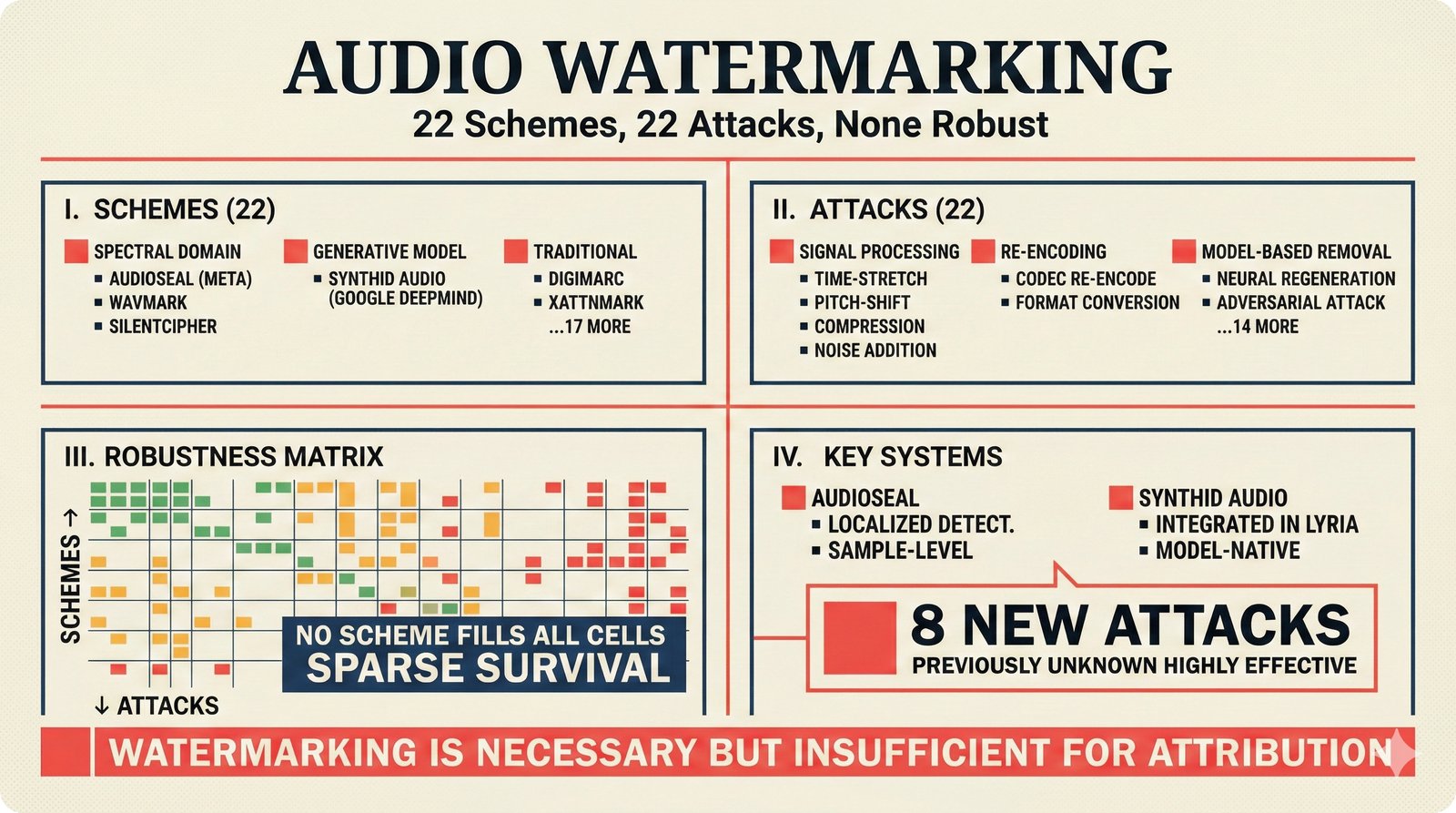 *Watermarking robustness: 22 schemes versus 22 attacks -- no single scheme survives all attack types.* ---  *Content ID evolution: four generations from acoustic fingerprinting through perceptual hashing and watermarks to AI detection.* --- 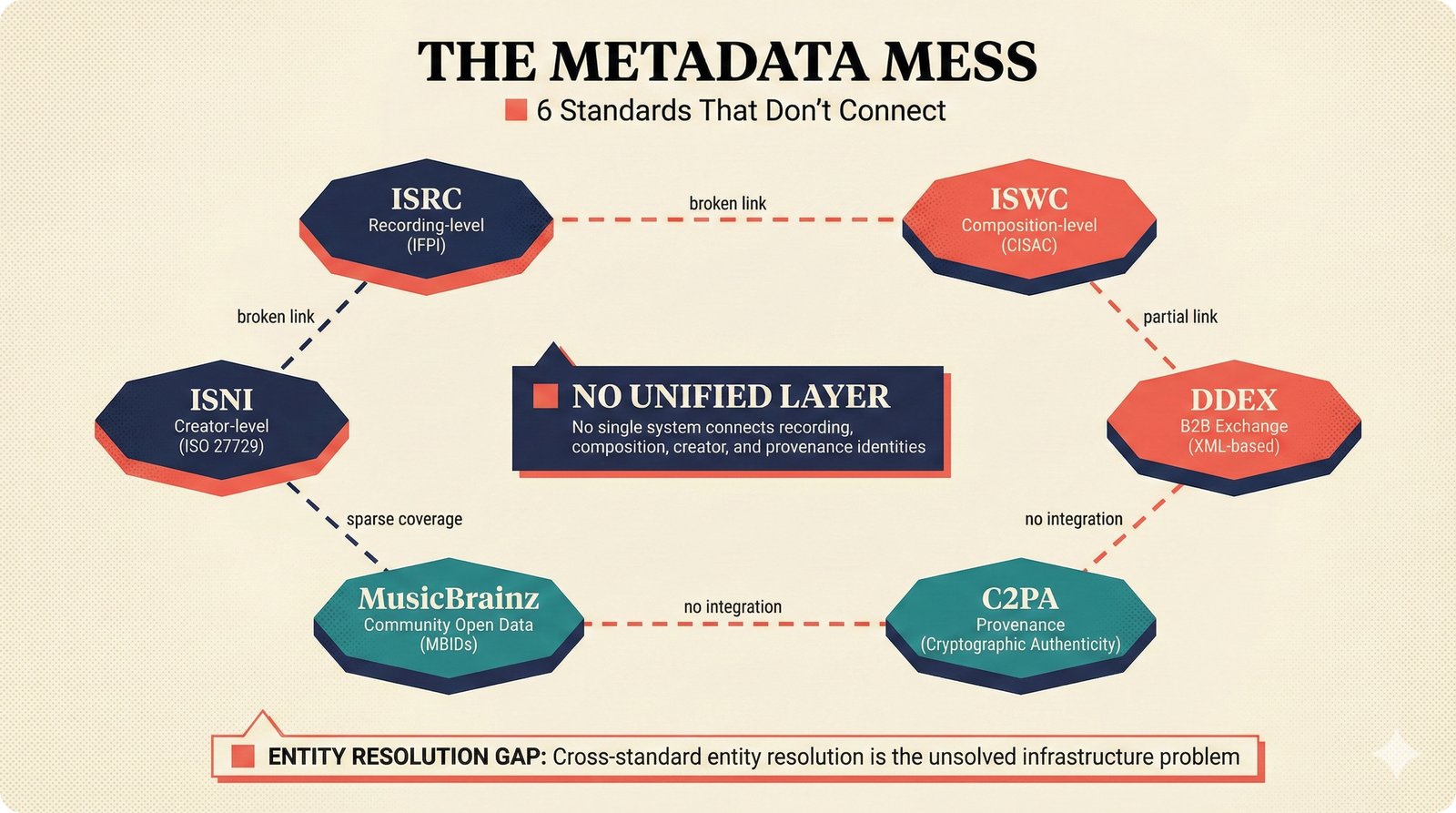 *Metadata mess: ISRC, ISWC, ISNI, IPI, DDEX, and MBID as disconnected islands -- no unified provenance chain exists.* --- 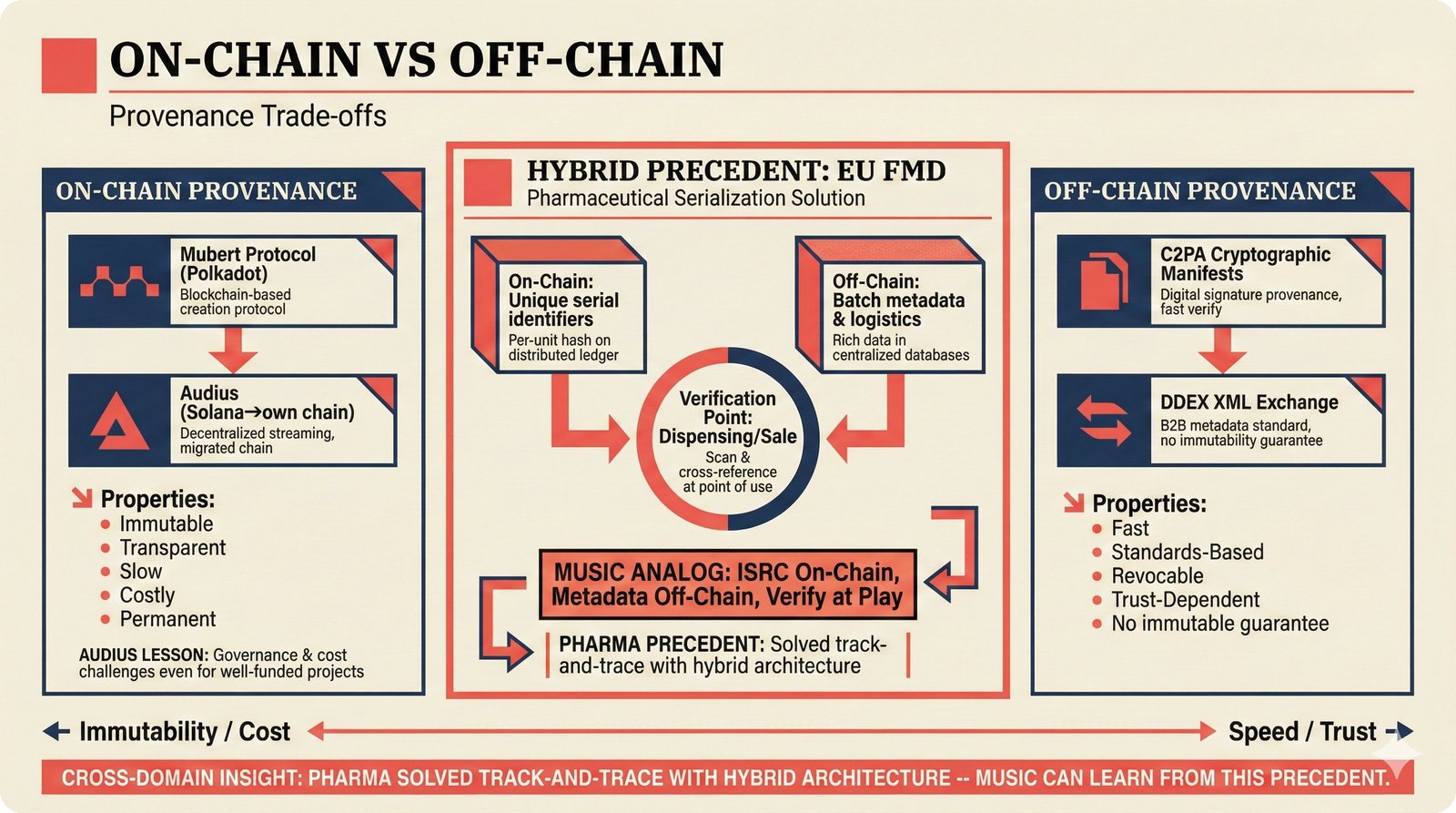 *On-chain vs off-chain: provenance trade-offs with pharmaceutical serialization as a cross-domain hybrid precedent.* --- 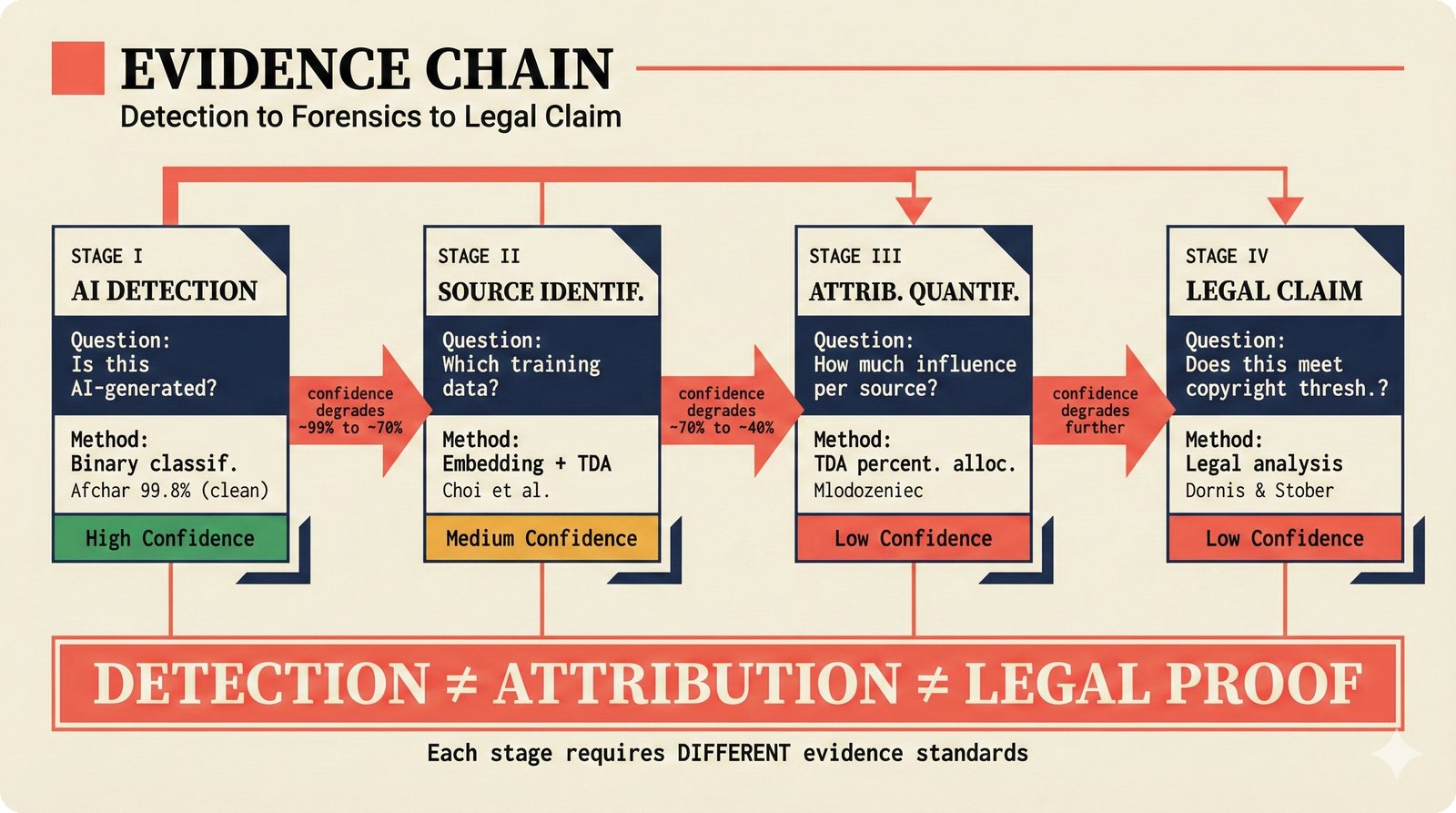 *Evidence chain: confidence degrades from AI detection (0.95) through attribution (0.80) and provenance (0.70) to legal claim (0.50).* --- 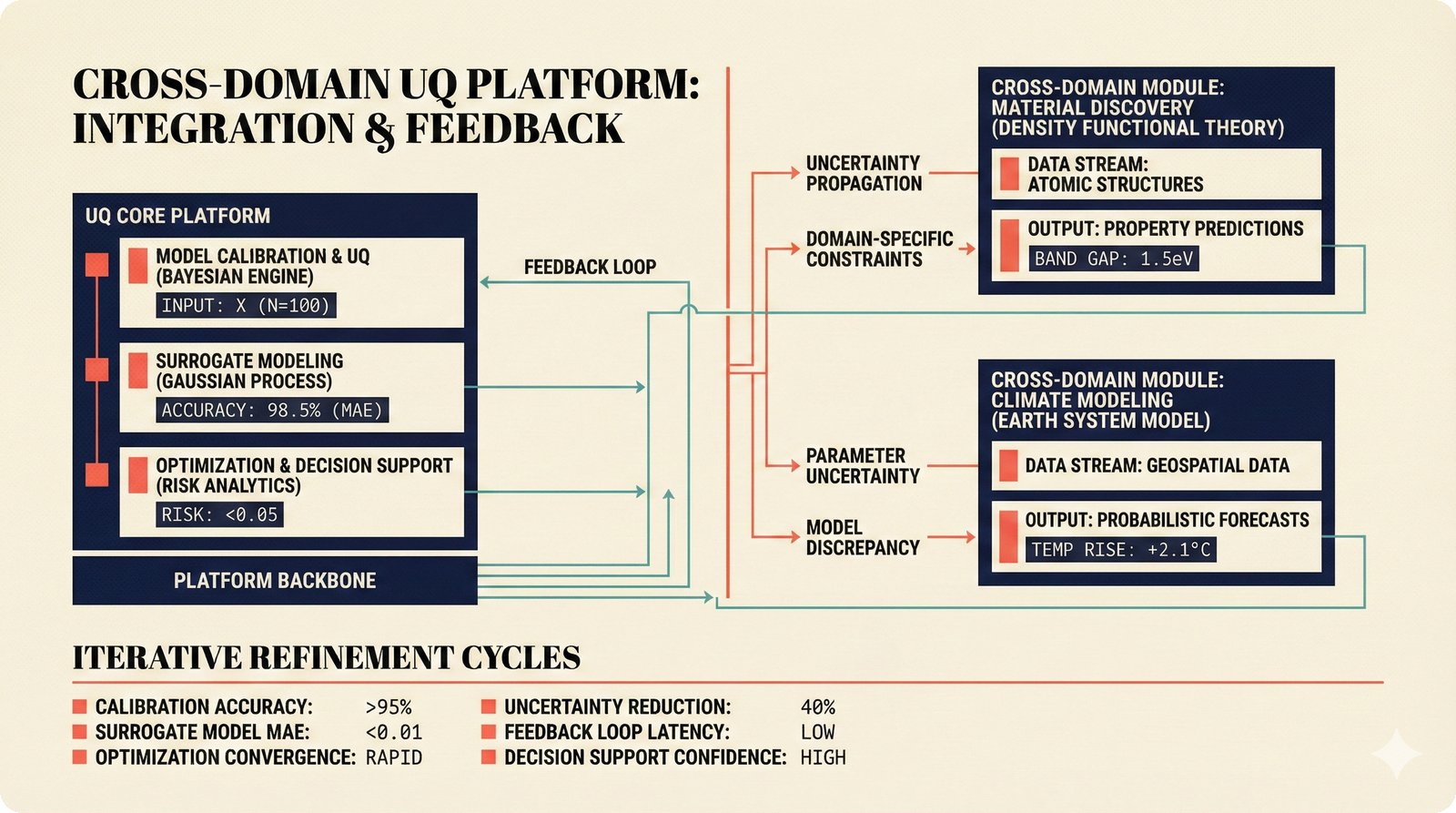 *UQ cross-domain: medical diagnosis, autonomous vehicles, and financial risk share uncertainty quantification methods with music attribution.* --- 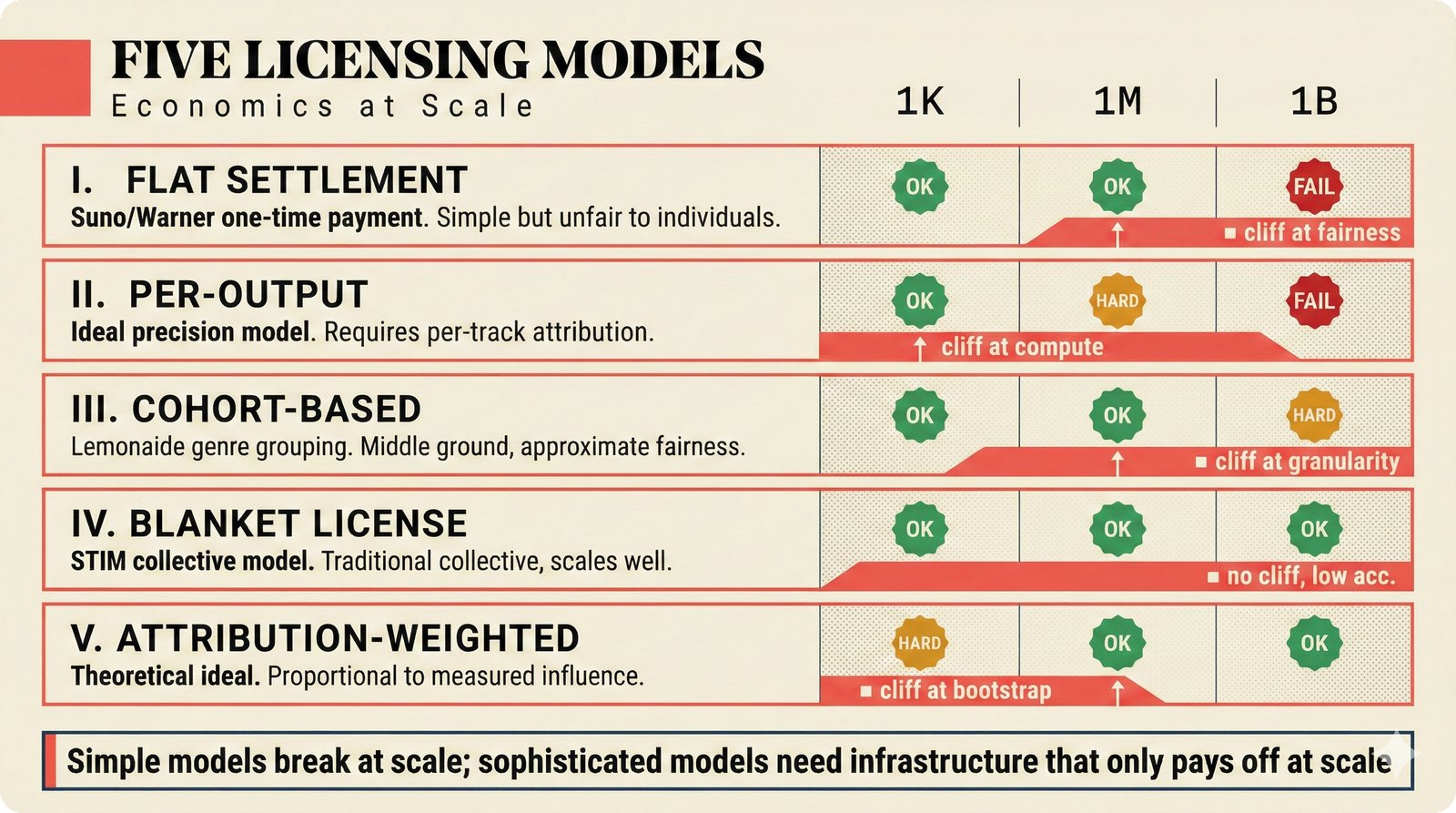 *Licensing models: per-track, blanket, micro-licensing, subscription, and revenue-share compared at three scale points.* --- 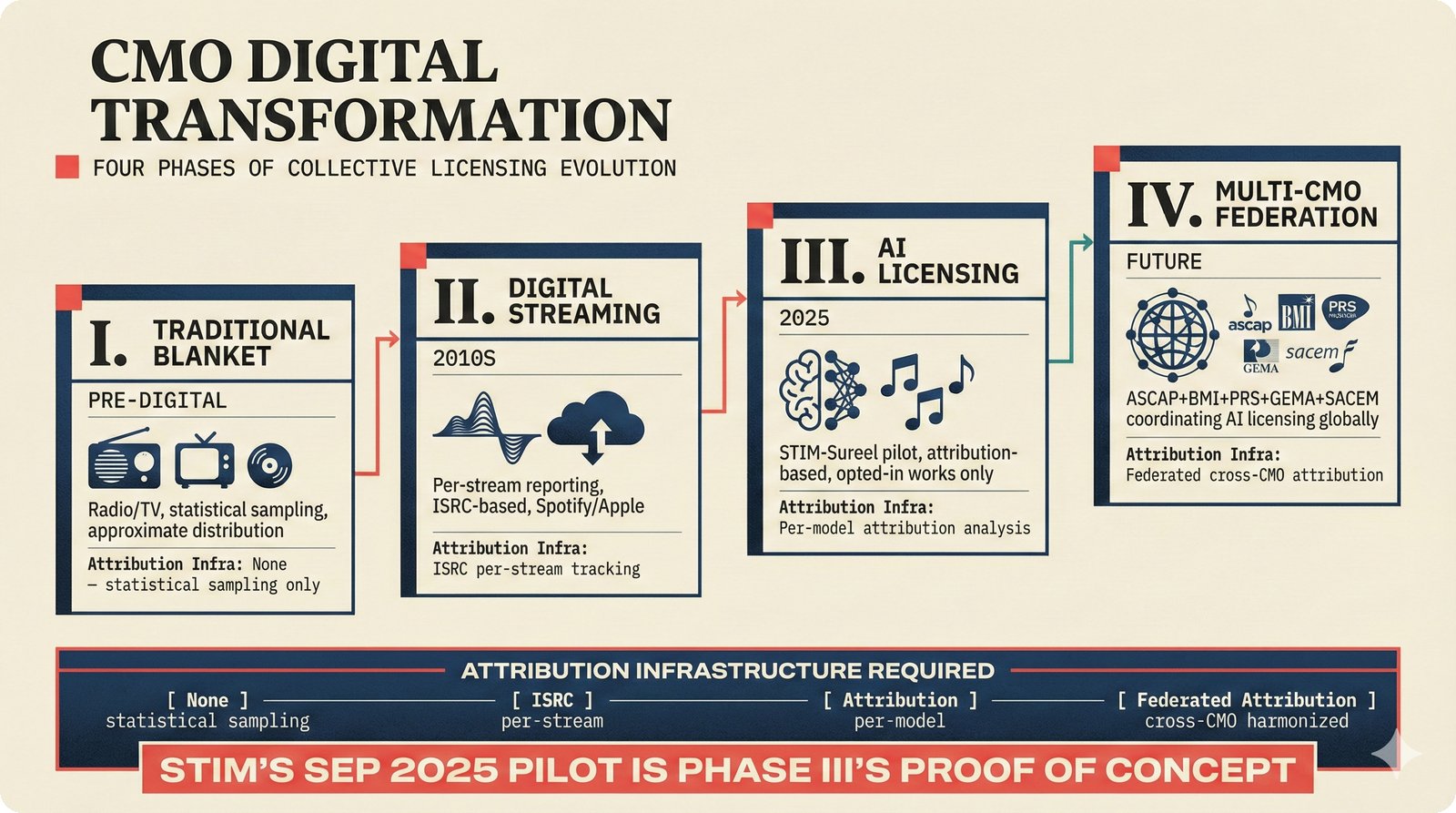 *CMO transformation: blanket licensing to digital streaming to AI licensing to multi-CMO federation -- four evolutionary stages.* --- 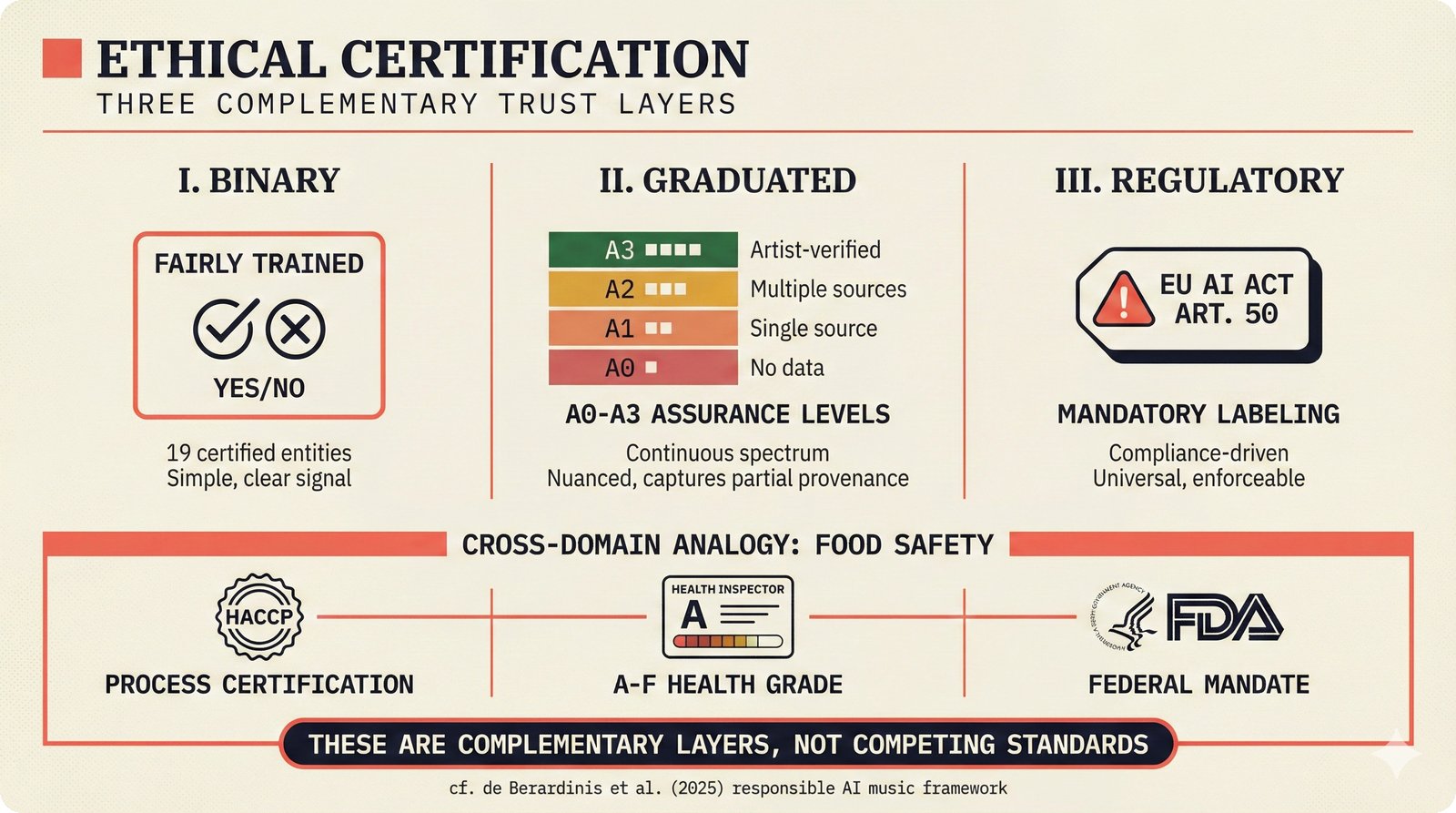 *Ethical certification: Fairly Trained (binary), A0-A3 (graduated), and EU AI Act (regulatory) -- three complementary trust layers.* --- 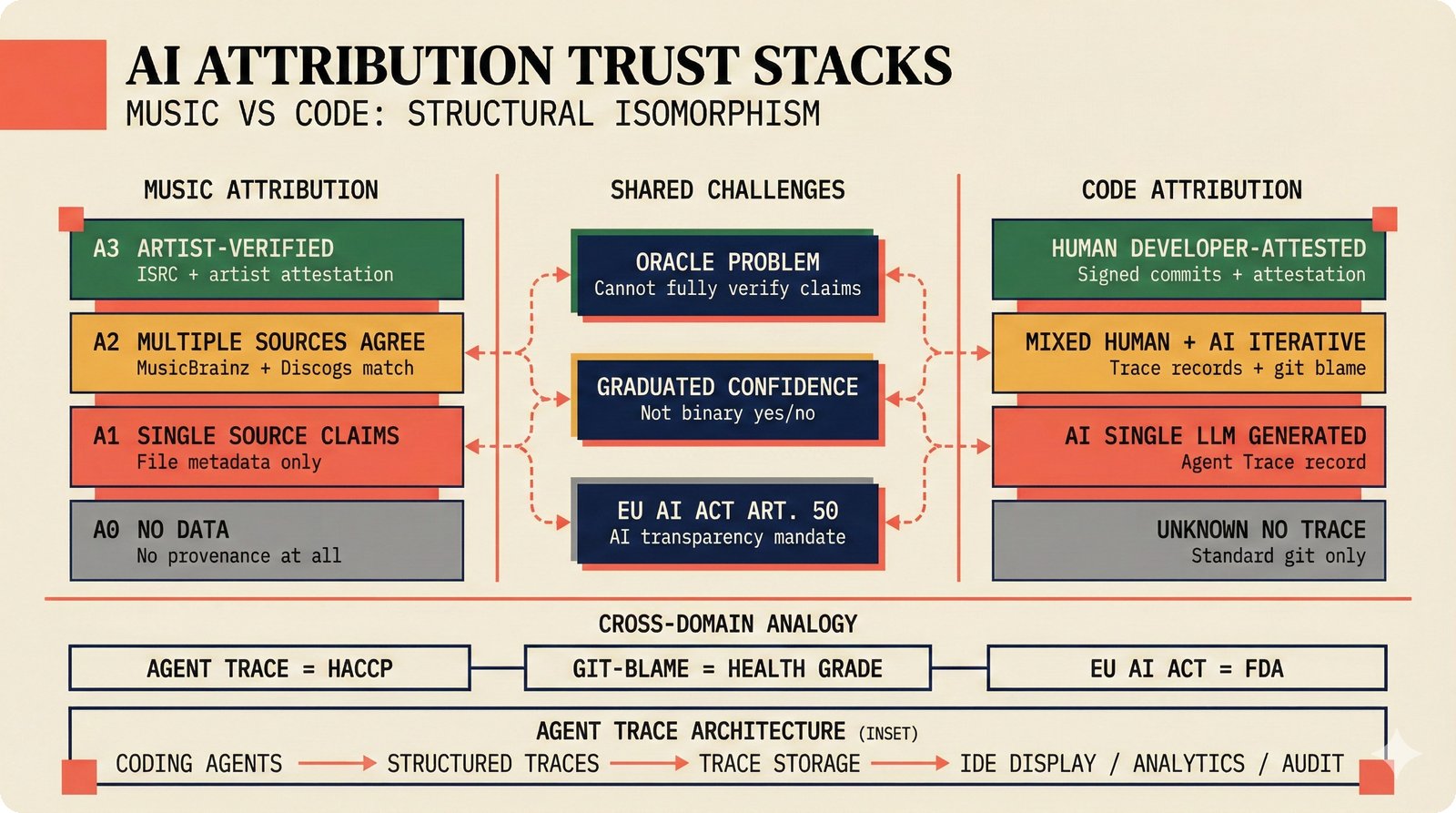 *AI code landscape: music A0-A3 assurance parallels code unknown/AI/mixed/human attribution -- both face the Oracle Problem.* --- 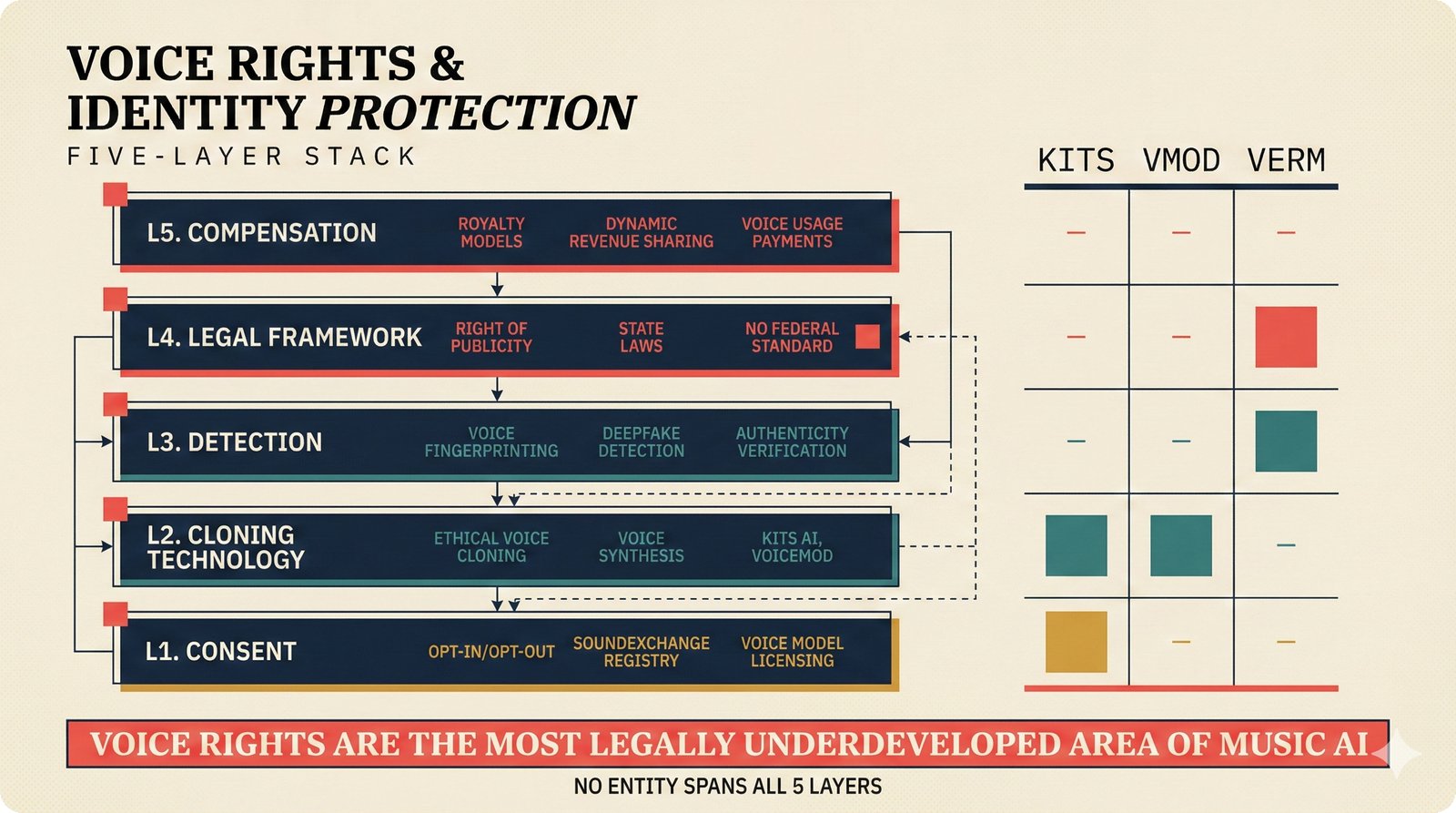 *Voice rights stack: five layers from consent through detection to compensation -- no company spans all layers.* --- 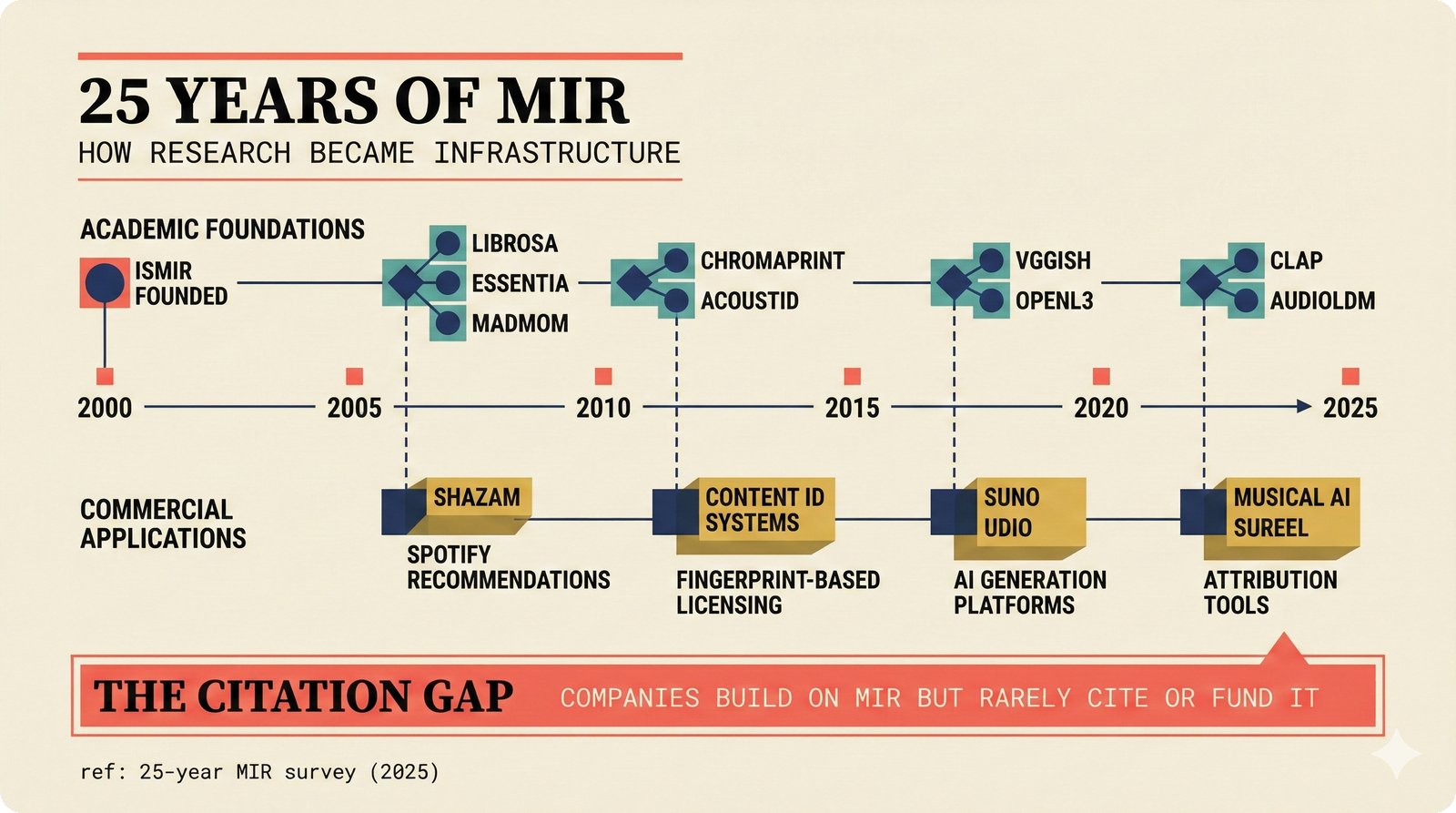 *MIR history: 25-year timeline of research milestones and commercial products with a persistent citation gap.* --- 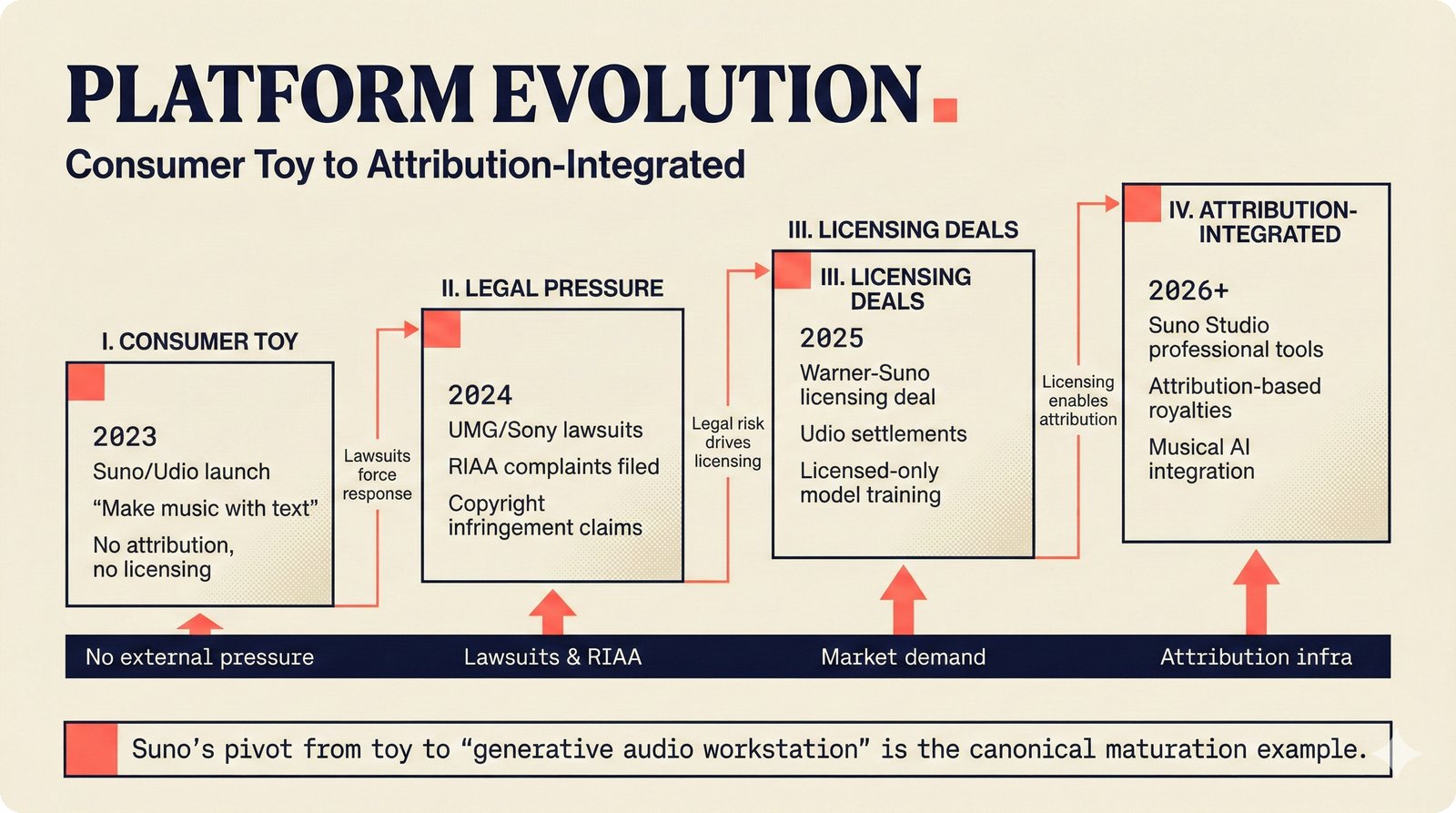 *Platform evolution: consumer toy to prosumer to professional to attribution-integrated -- four maturation stages.* ---  *Build vs buy: 12 components mapped across three team archetypes -- each making different build/buy/partner choices.* --- 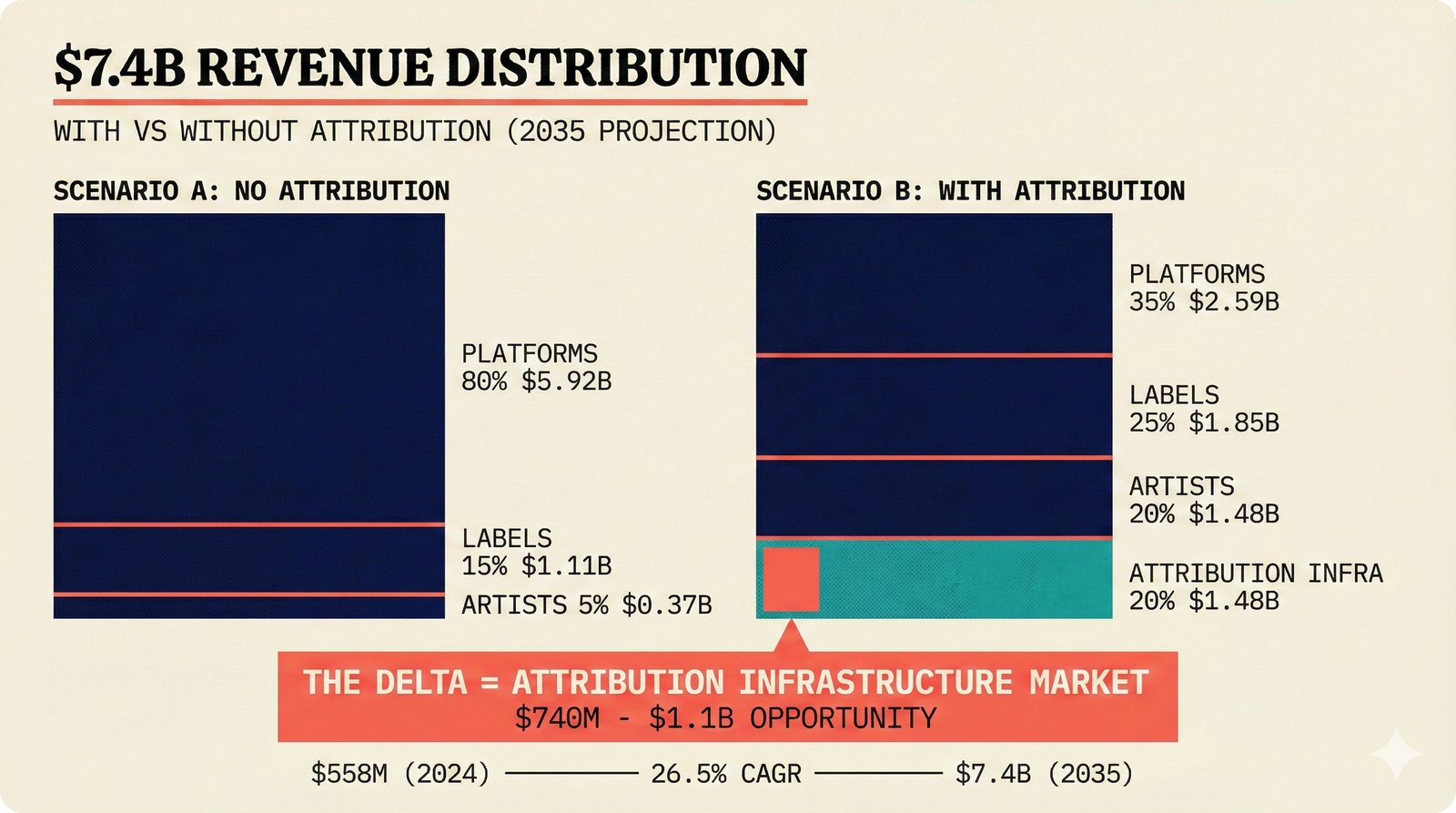 *Revenue distribution: without attribution 80% to platforms, with attribution 20% flows to artists from $7.4B market.* --- 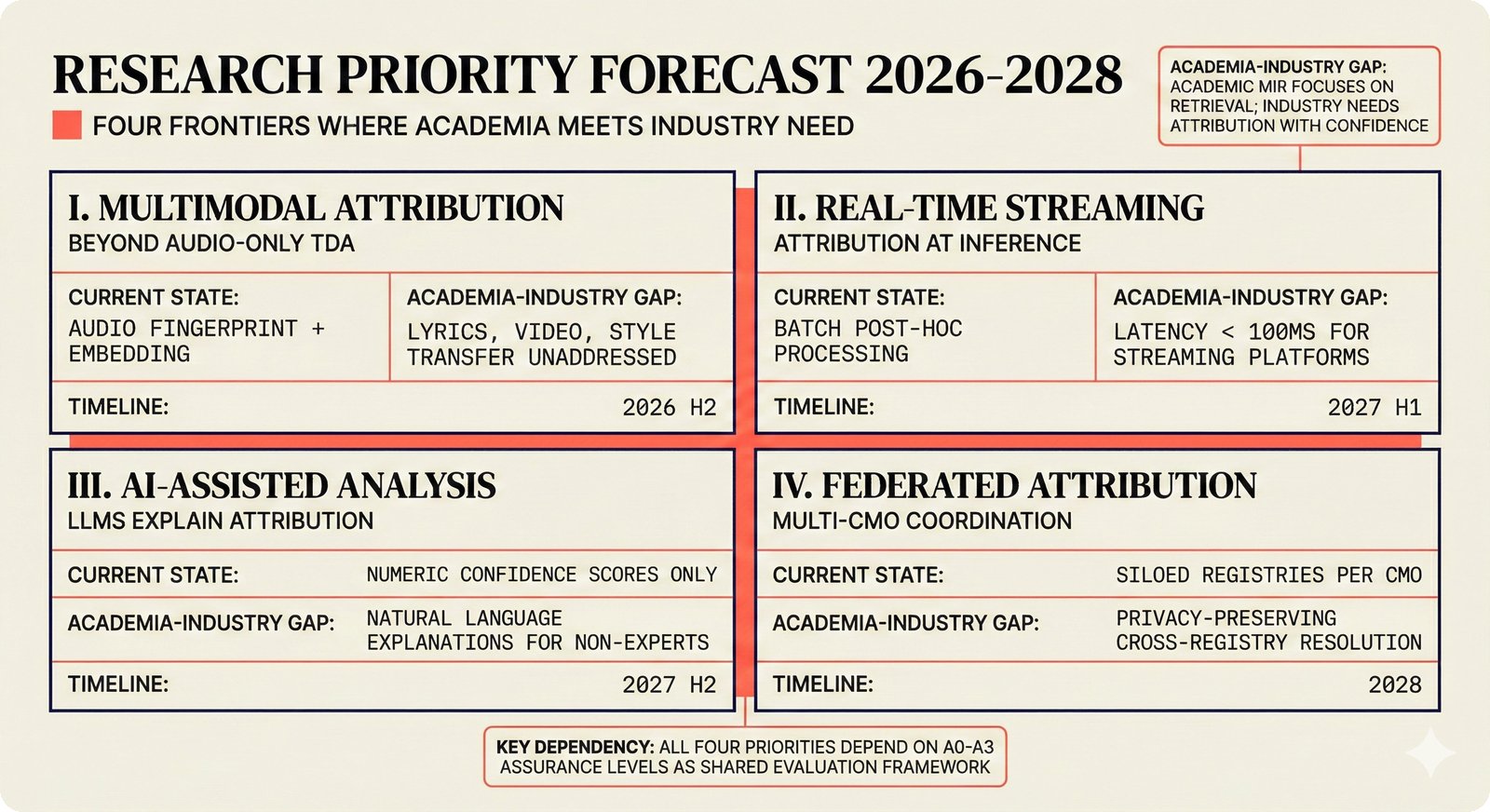 *Research priorities 2026-2028: multimodal, streaming, AI-assisted, and federated attribution as four priority areas.* --- 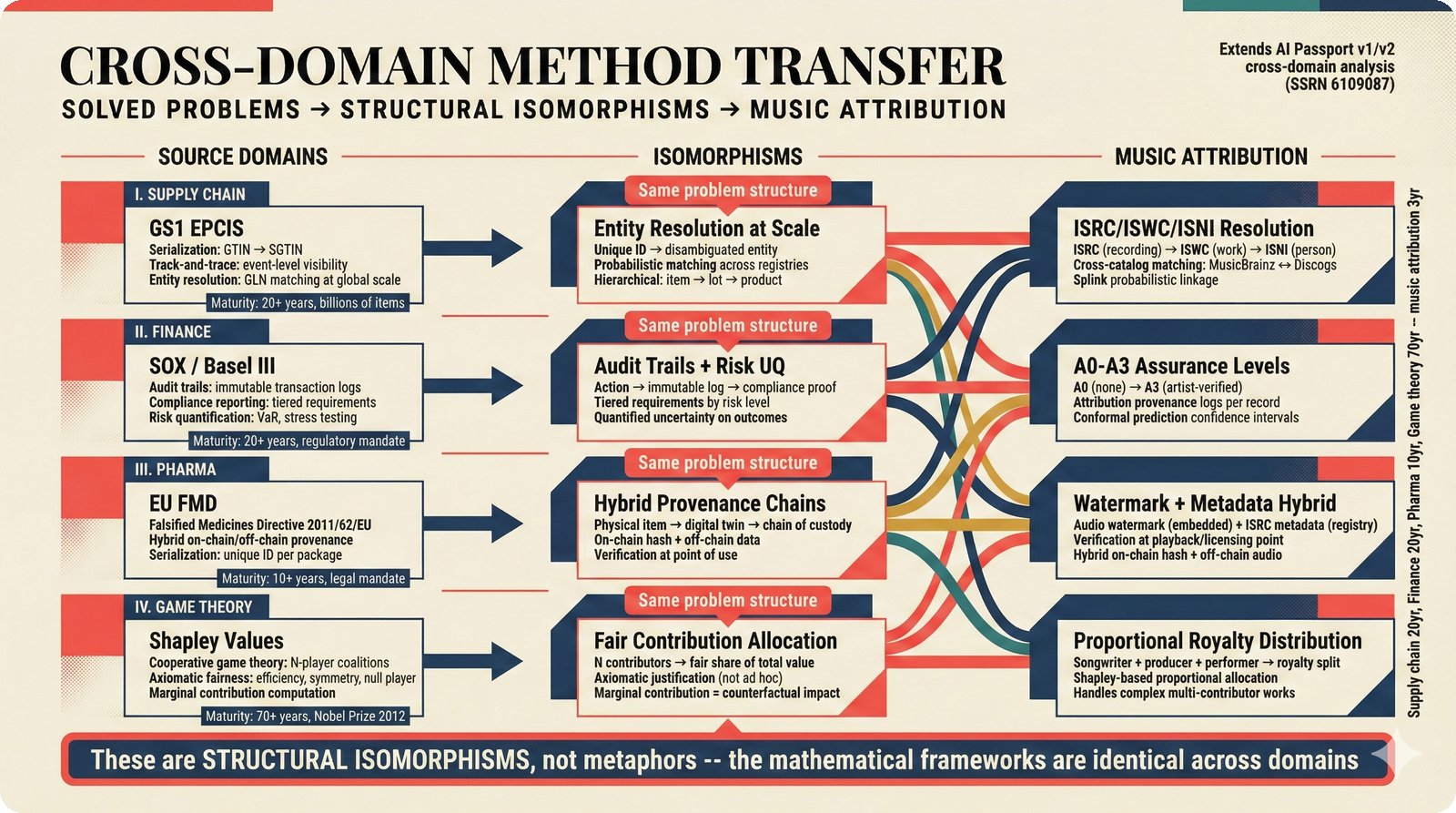 *Cross-domain transfer: supply chain, finance, pharma, and game theory solutions mapped to music attribution targets.* --- 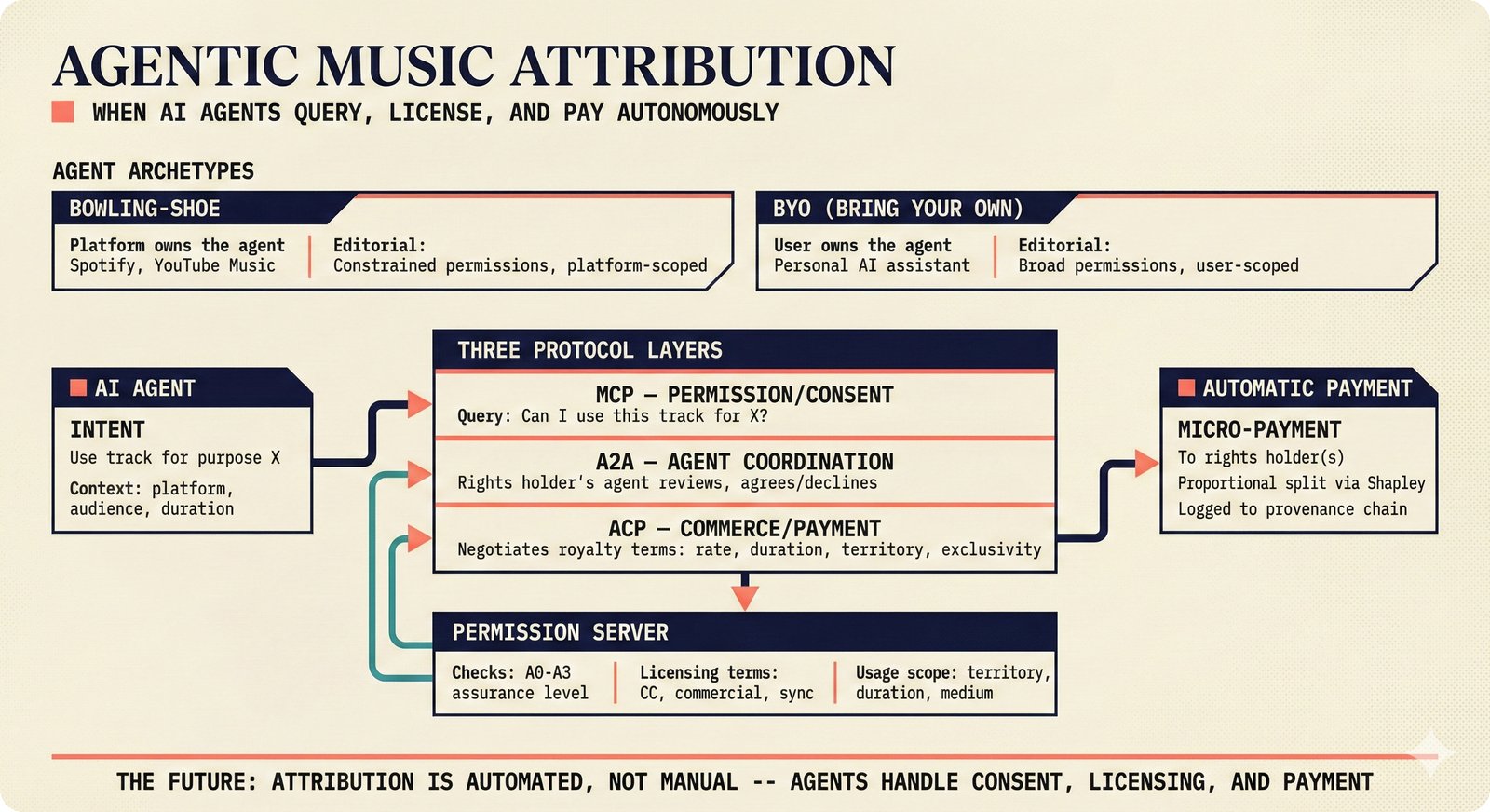 *Agentic attribution: AI agent queries MCP for rights, coordinates via A2A, and pays via ACP -- fully automated.* ---  *Emerging categories: attribution-as-a-service, ethical certification, voice rights, CMO federation, and AI detection.* --- 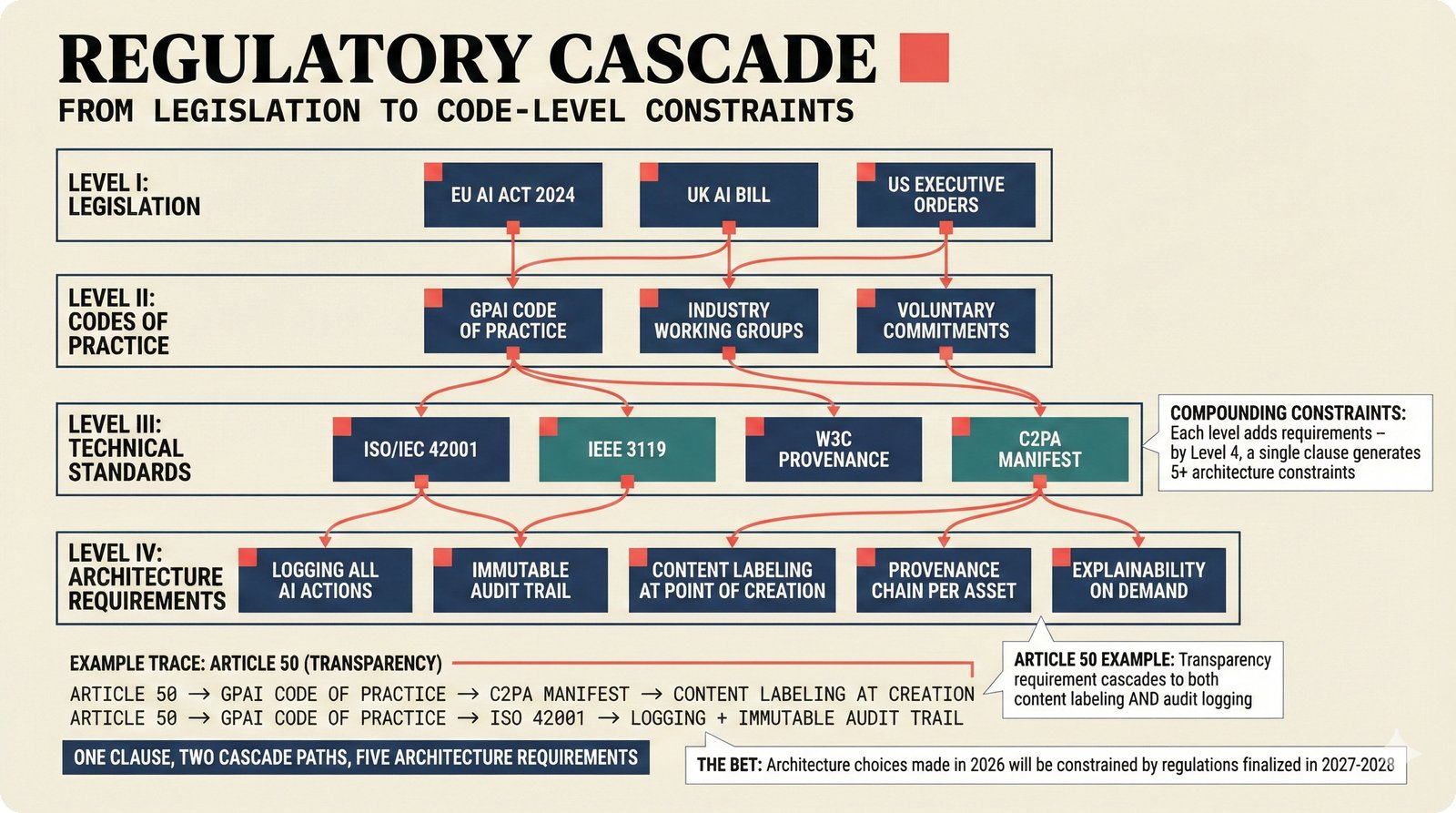 *Regulatory cascade: legislation (EU AI Act) cascades to codes of practice, then standards, then architecture requirements.* --- 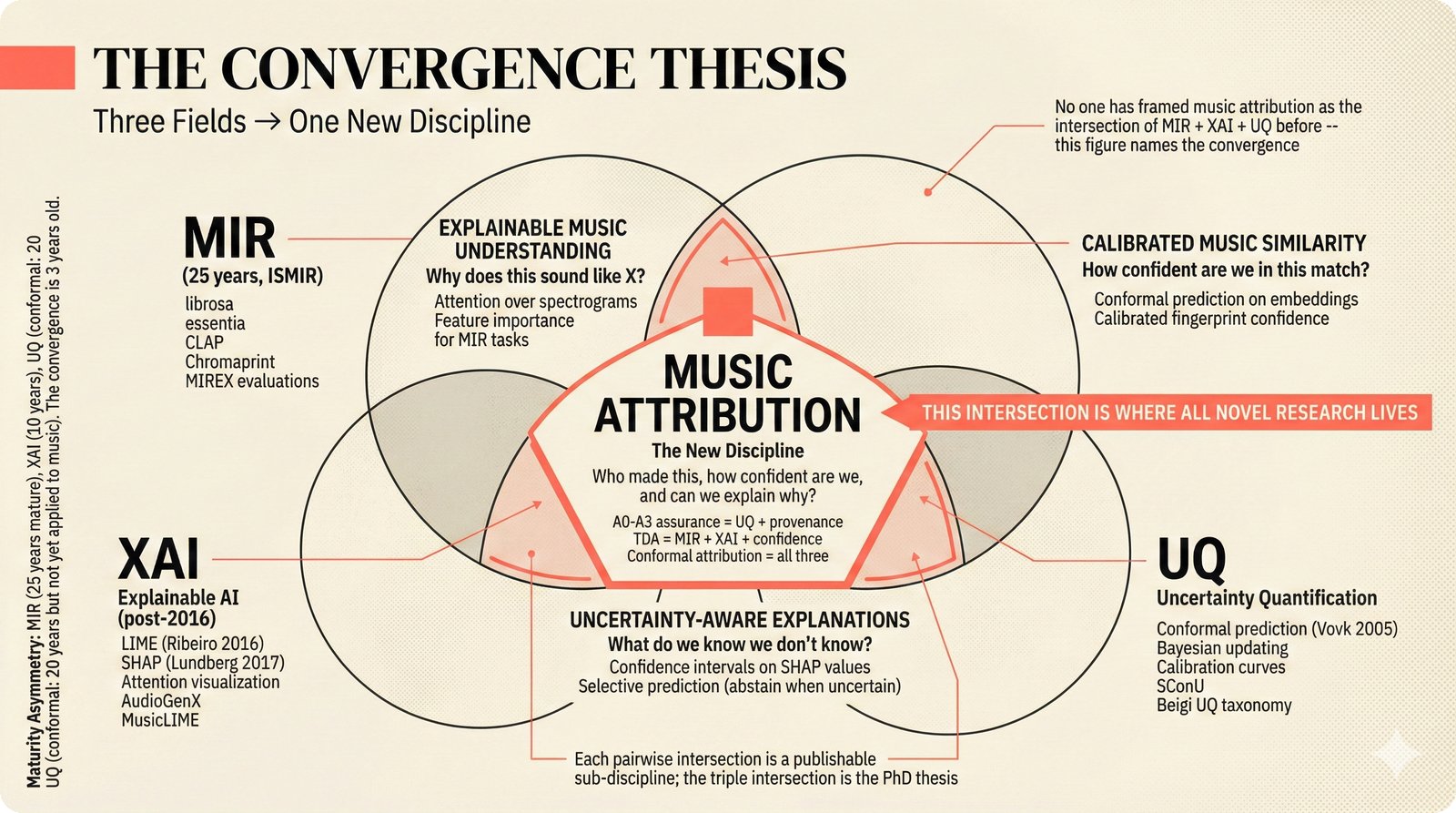 *Convergence thesis: MIR + XAI + UQ converge at the triple intersection -- music attribution as the synthesis field.* ---  *Open problems: solvable in 2 years, hard in 5 years, fundamental in 10+ years -- with funding inversion pattern.* --- 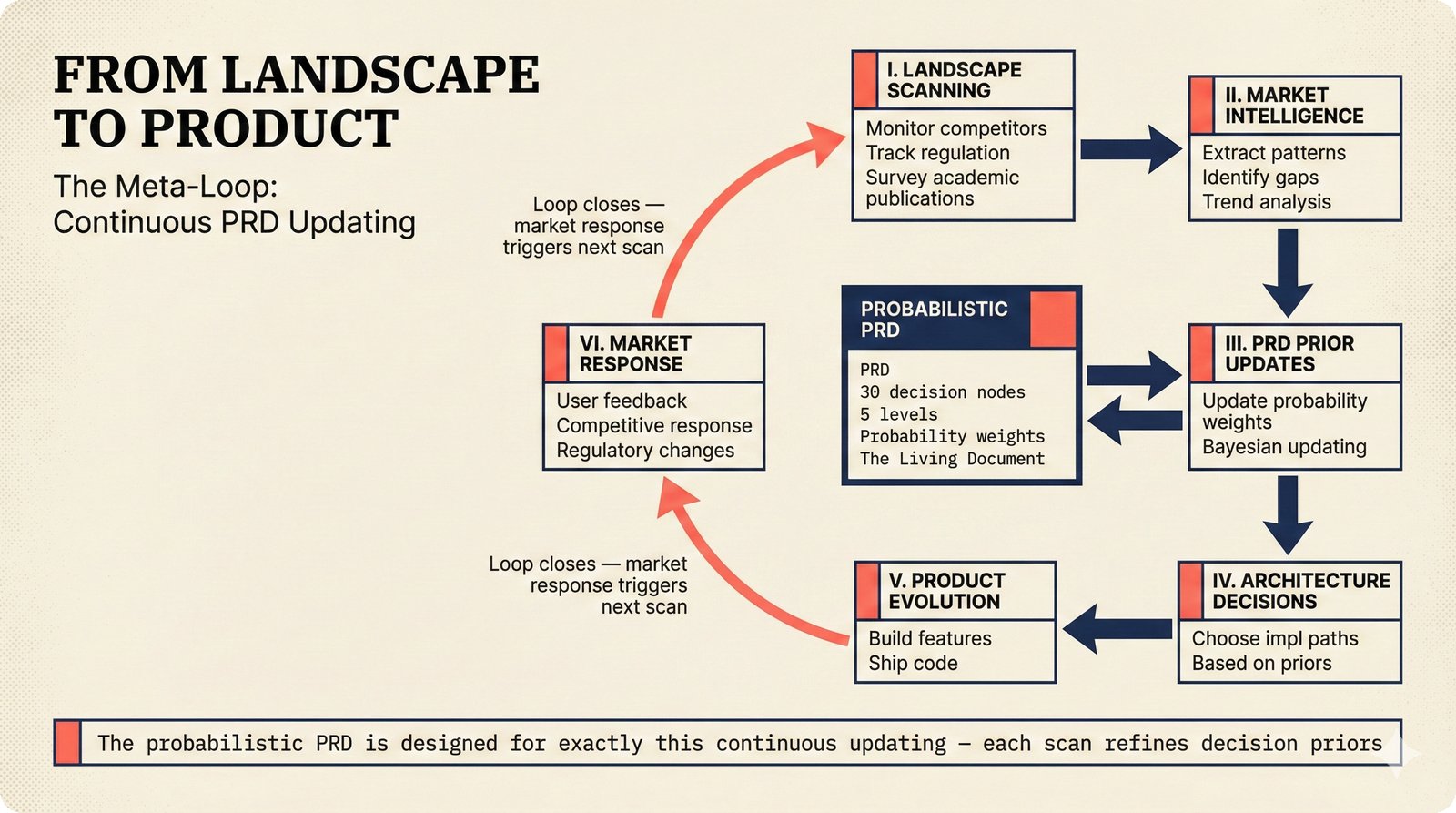 *Meta-loop: landscape scan feeds market intel, updates PRD, shapes architecture, builds product, monitors market response -- repeat.*Theoretical Foundations¶
The theory figures explain the six theoretical pillars from the companion paper: the Oracle Problem, attribution-by-design, deterrence economics, A0-A3 assurance levels, the two-friction taxonomy, confidence and uncertainty, entity resolution, and MCP consent infrastructure. Each concept is presented at both ELI5 and technical depth.
22 figures -- click to expand
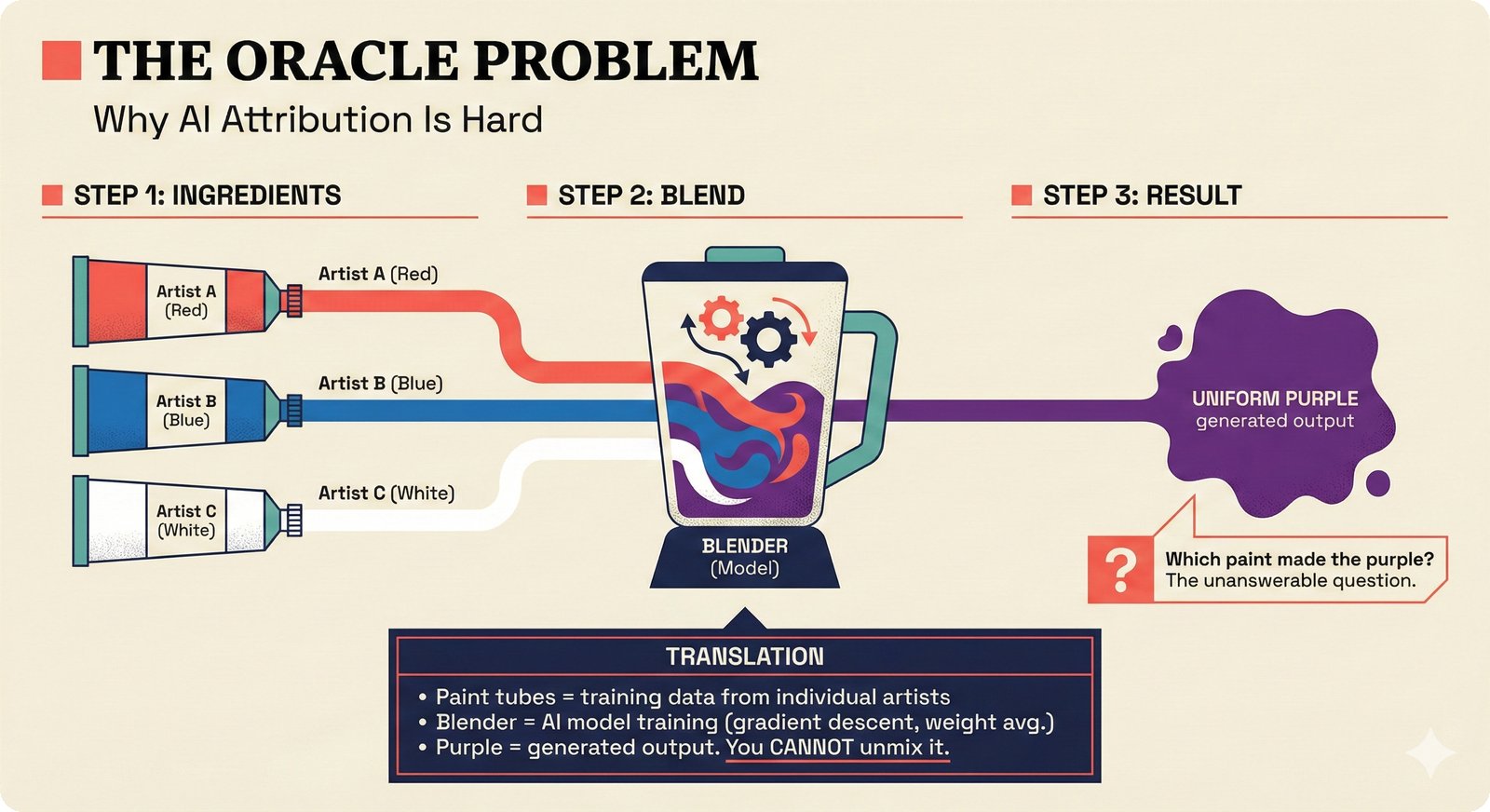 *Oracle Problem ELI5: once creative works are blended in an AI model, separating individual contributions is as impossible as unmixing paint.* --- 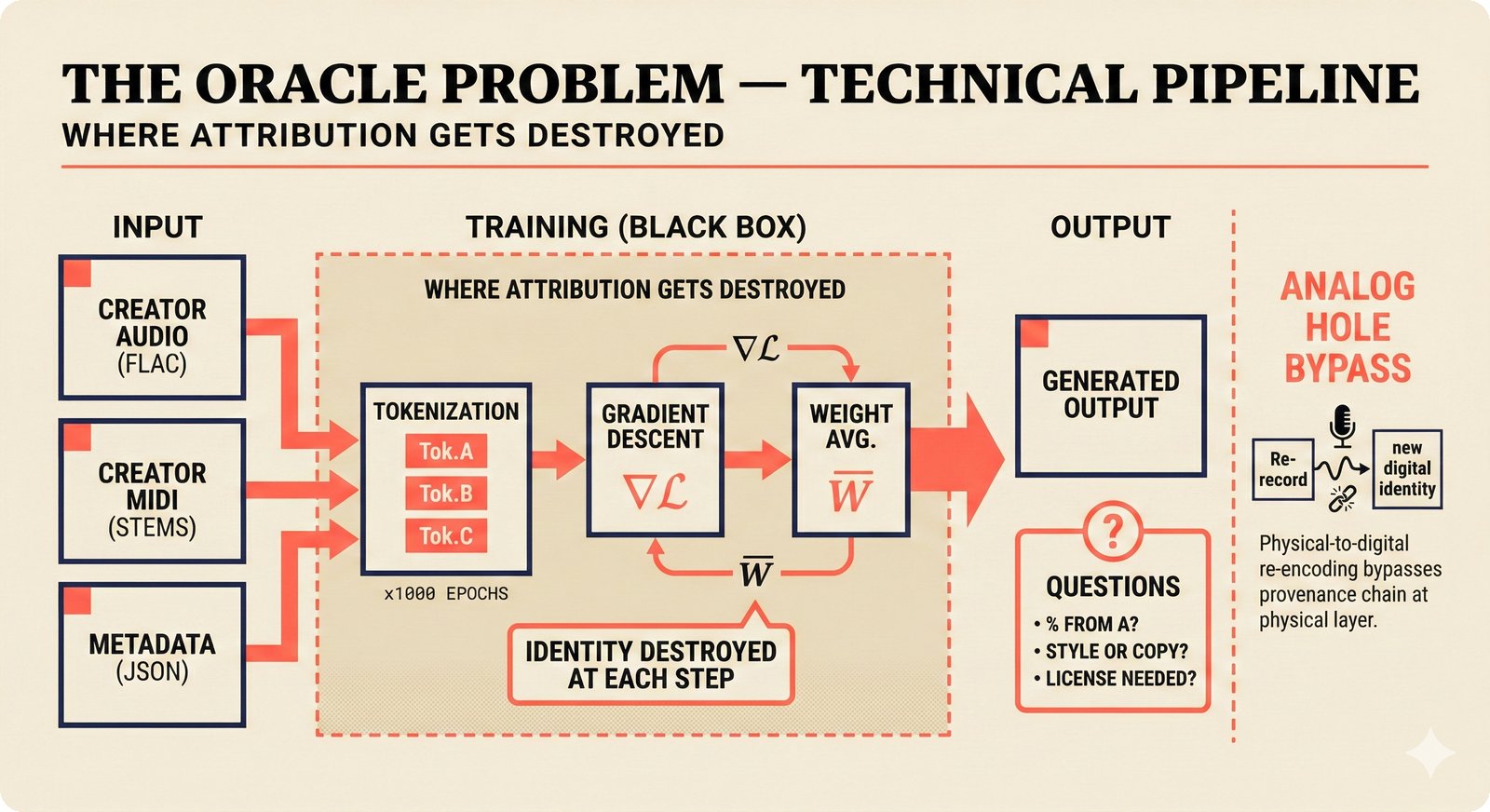 *Oracle Problem technical: tokenization, gradient descent, and weight averaging destroy attribution identity at each training stage.* --- 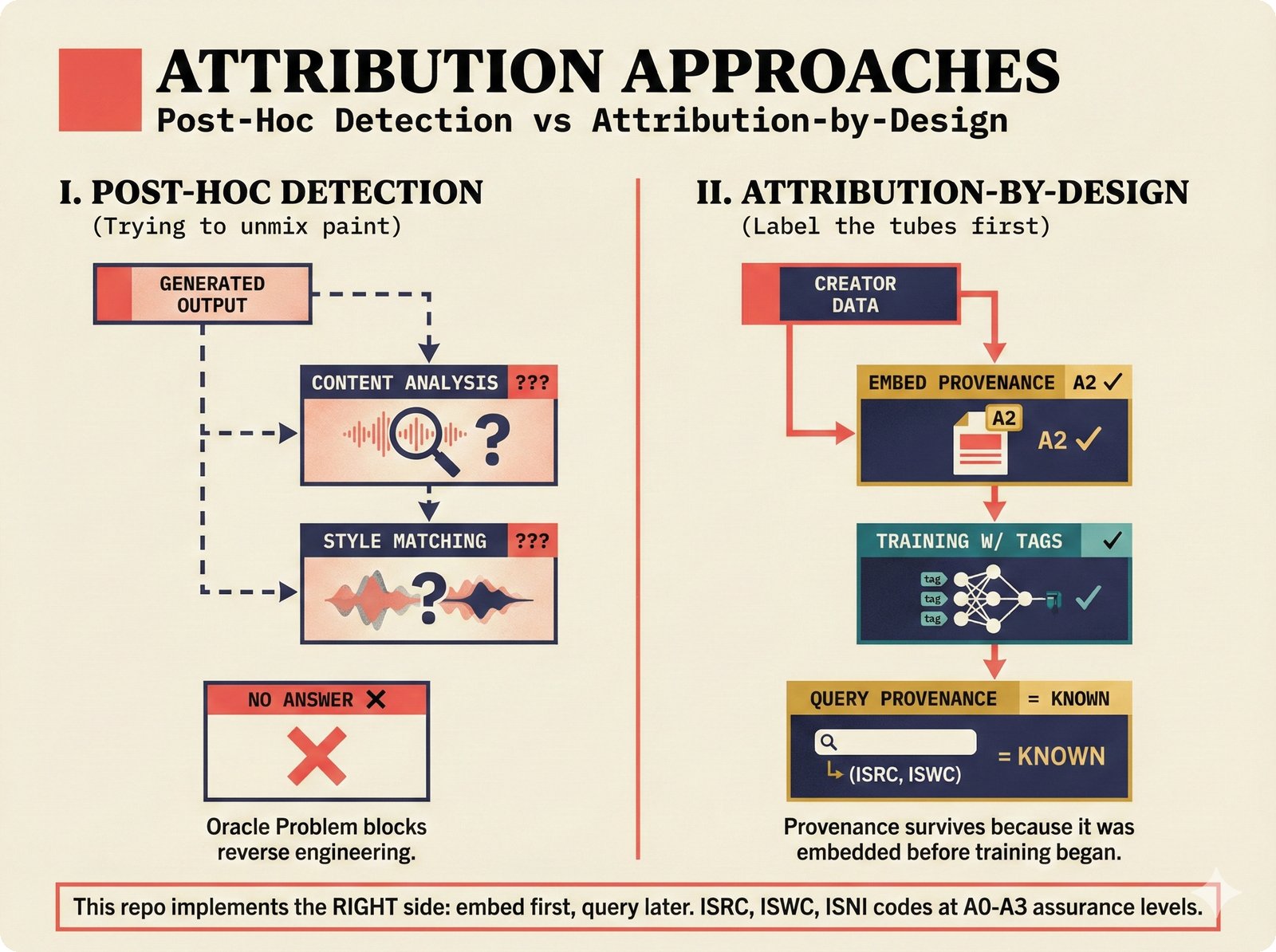 *Attribution-by-design vs post-hoc: embedded provenance at ISRC/ISWC assurance levels versus reverse engineering after the fact.* ---  *Deterrence economics: 3% audit rate deters infringement when penalties are large -- imperfect detection still protects via economic incentives.* --- 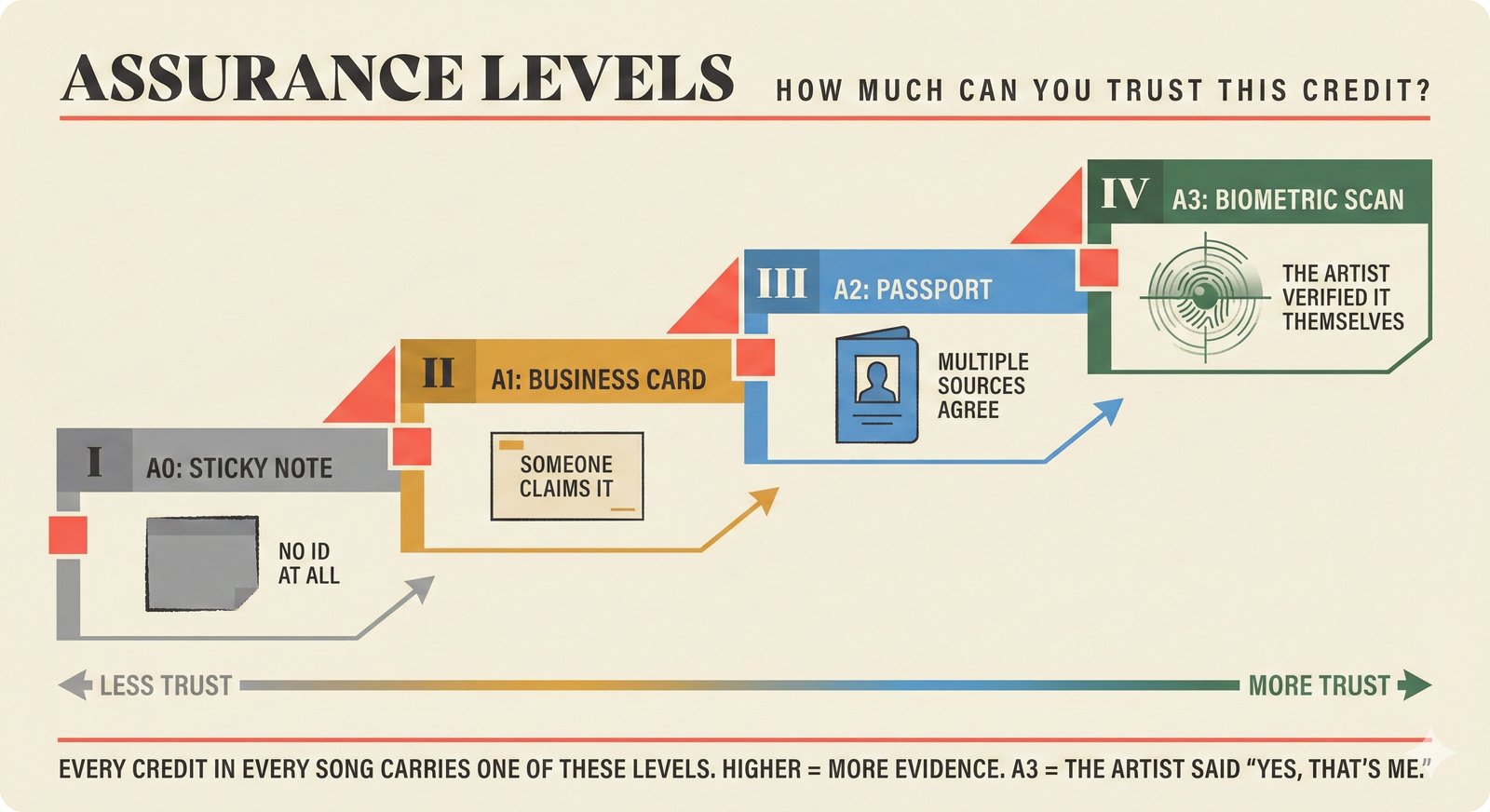 *Assurance levels ELI5: A0 no ID, A1 single claim, A2 multiple sources agree, A3 direct artist verification -- escalating trust.* ---  *Assurance-standards mapping: A0 no identifier, A1 ISRC only, A2 adds ISWC, A3 adds ISNI and IPI -- with analog hole warning.* --- 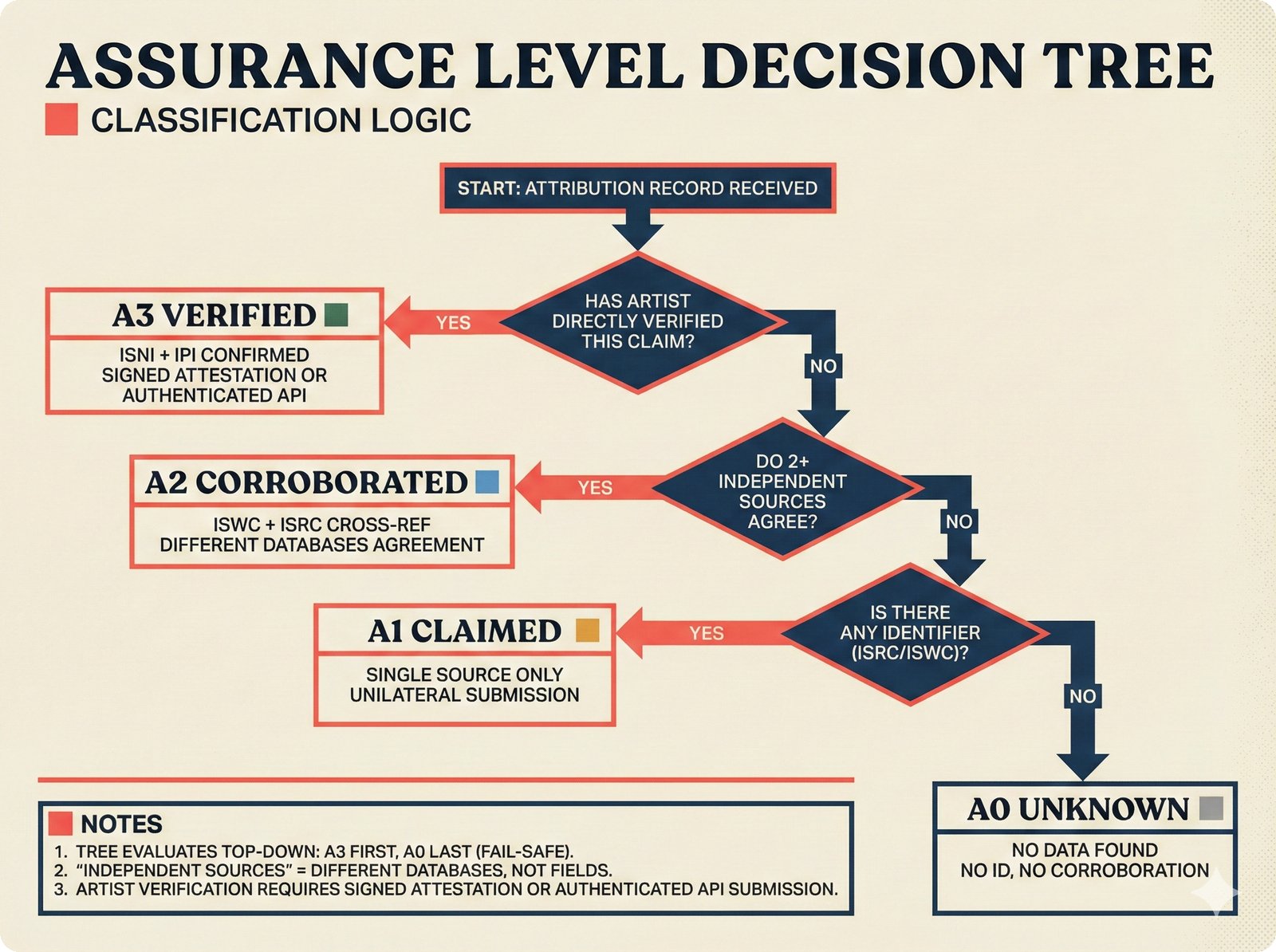 *Assurance decision tree: check artist verification (A3), source agreement (A2), any identifier (A1), default to A0.* ---  *Two-friction ELI5: administrative friction (licensing forms) to automate versus discovery friction (curation) to preserve.* --- 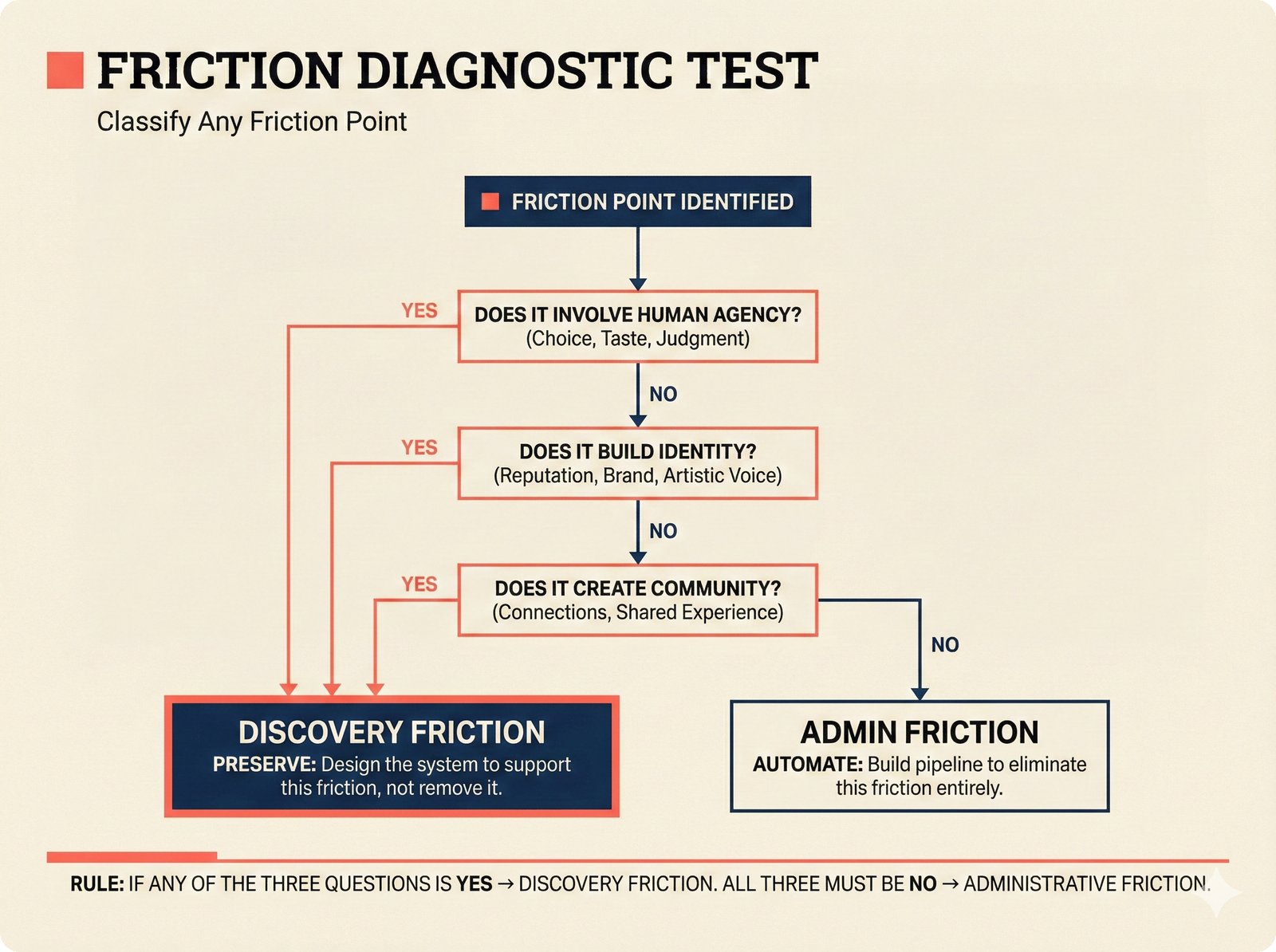 *Friction diagnostic: three questions classify any process as administrative (automate) or discovery (preserve).* --- 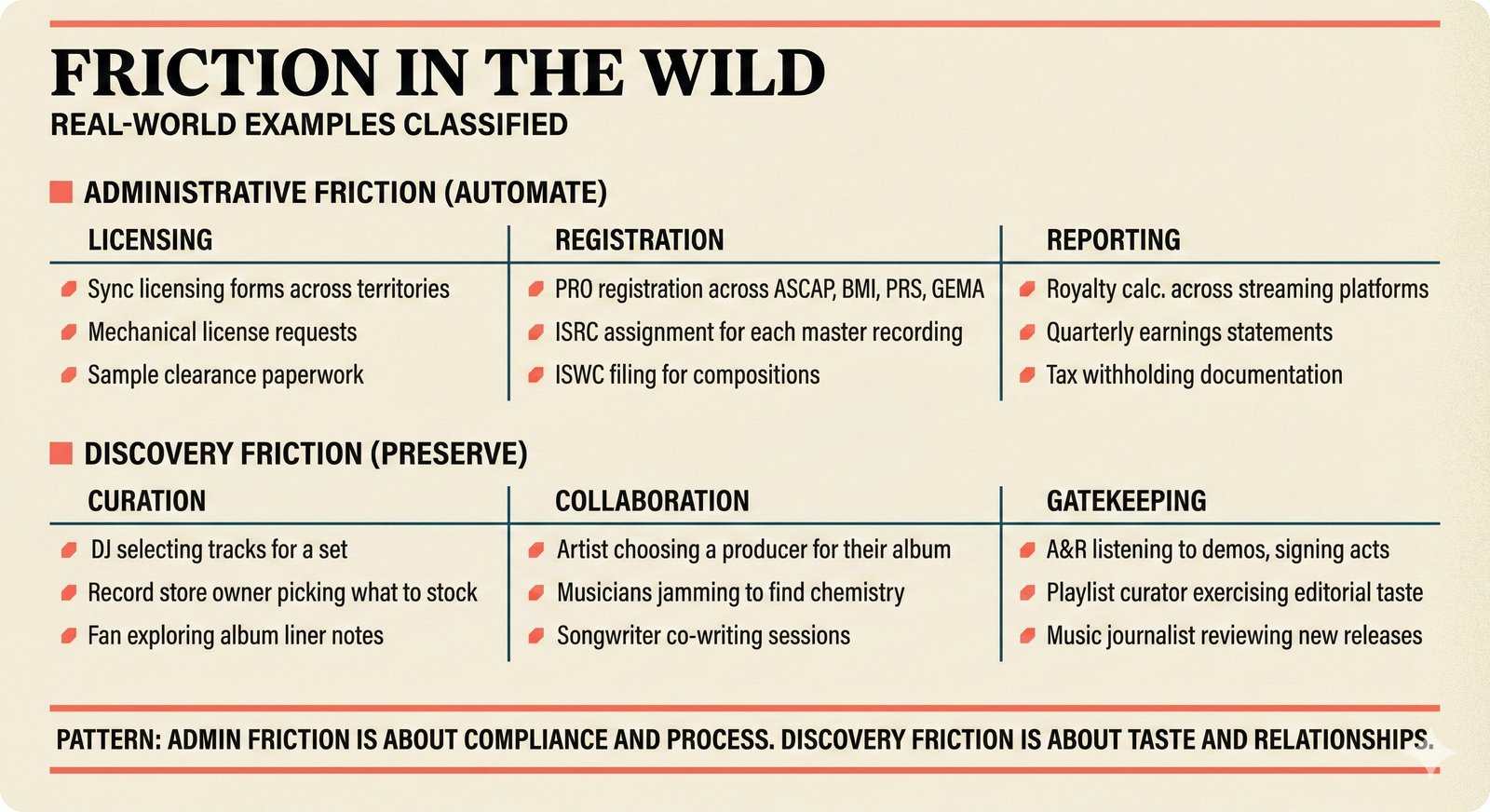 *Friction examples: sync licensing and royalty reporting are administrative; DJ curation and artist collaboration are discovery.* ---  *Confidence vs uncertainty ELI5: point estimate versus interval -- narrow ranges signal certainty, wide ranges signal need for evidence.* --- 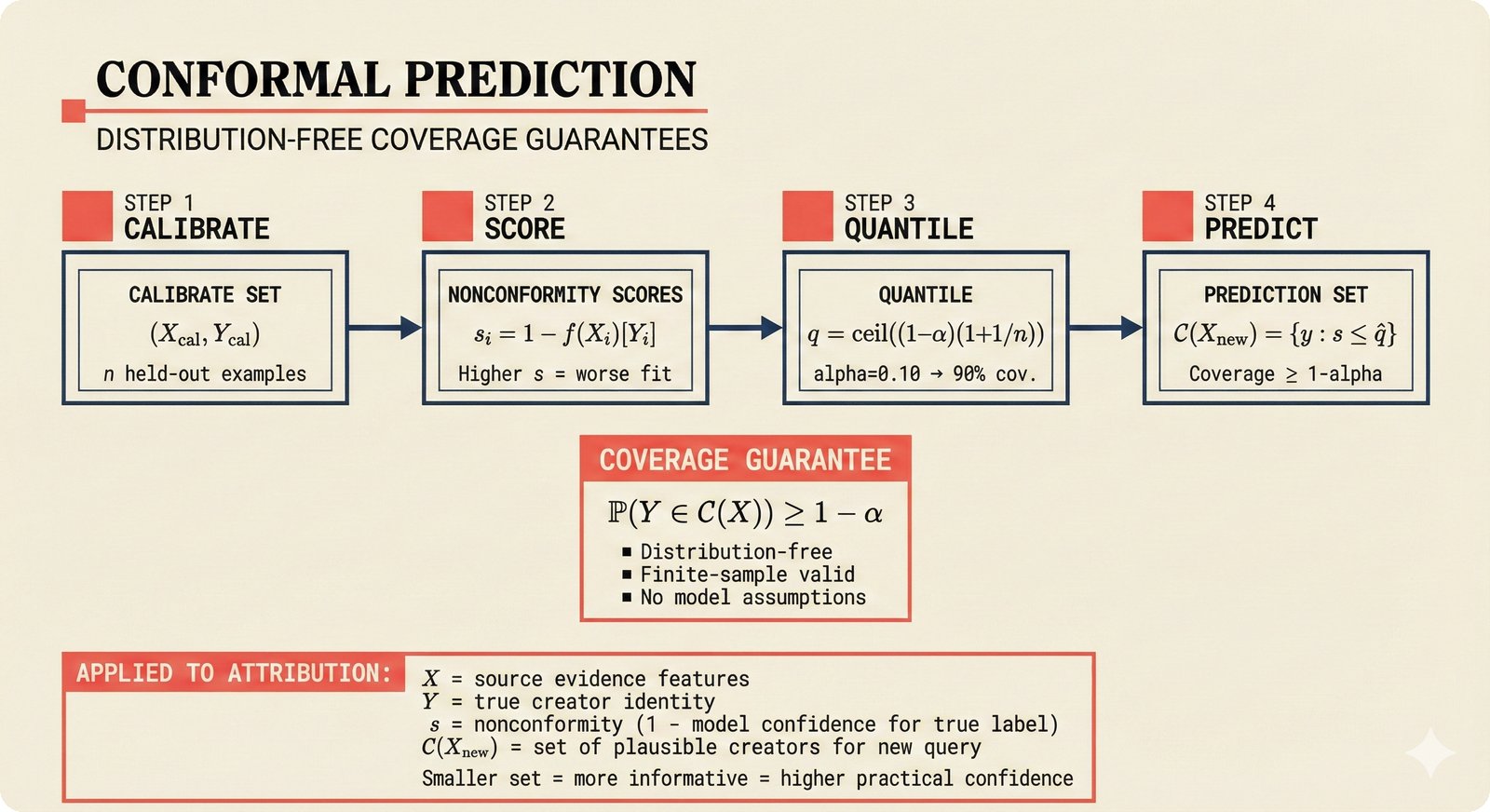 *Conformal prediction: distribution-free, finite-sample valid confidence intervals requiring no model assumptions.* --- 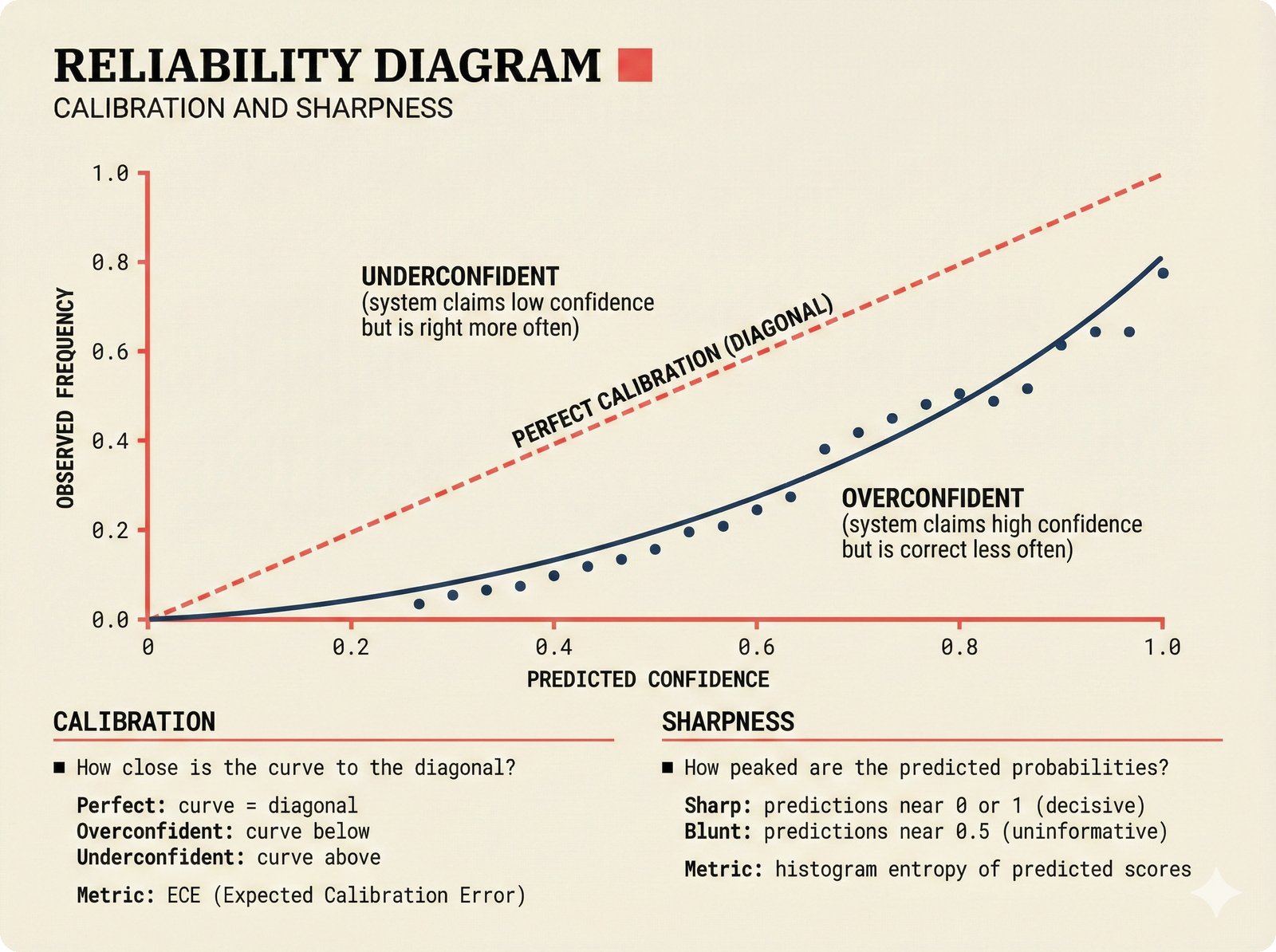 *Reliability diagram: evaluating calibration quality -- perfect diagonal, overconfident below, underconfident above, with ECE metric.* --- 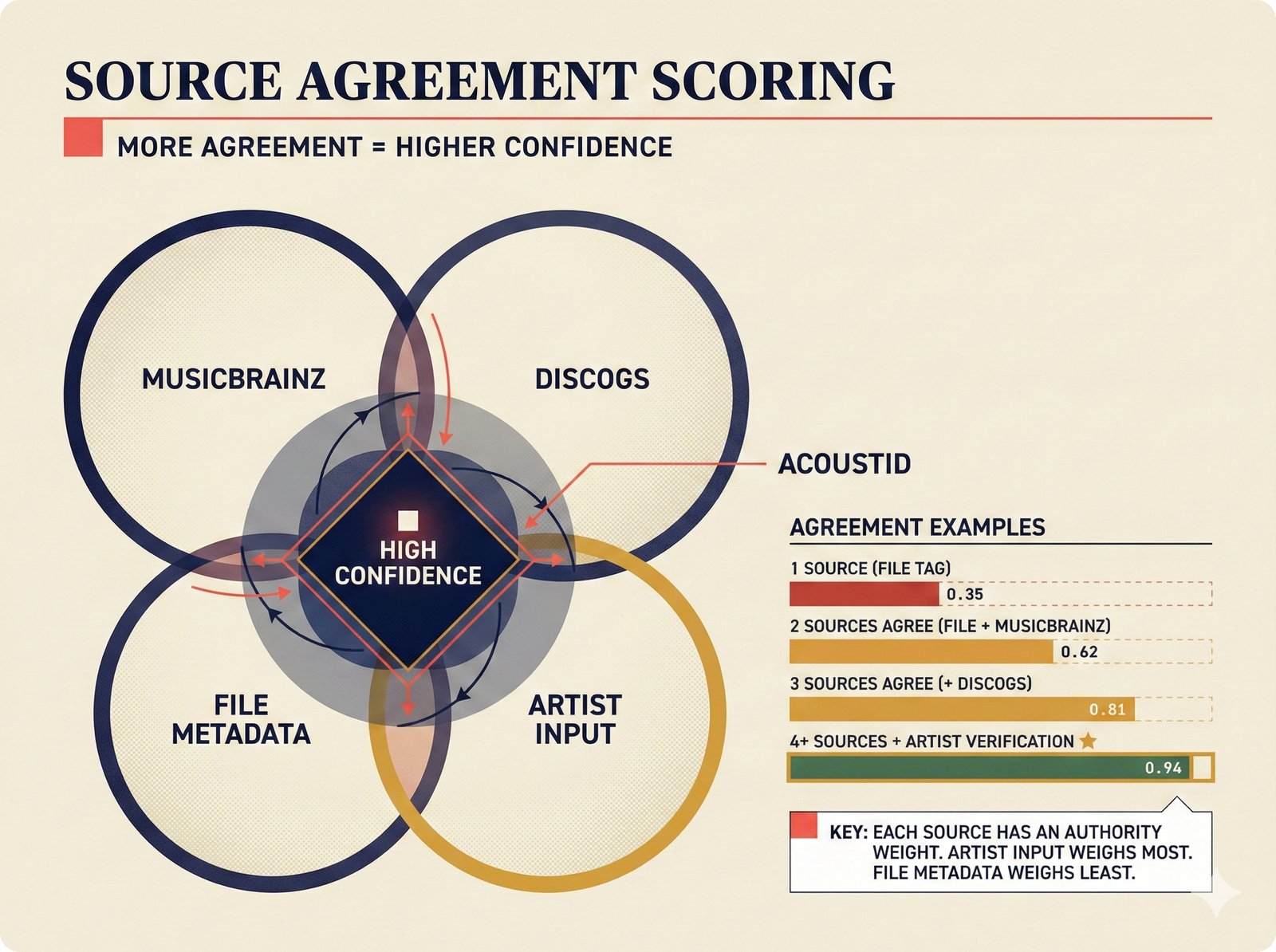 *Source agreement scoring: confidence rises from 0.35 with one source to 0.94 with four sources plus artist verification.* --- 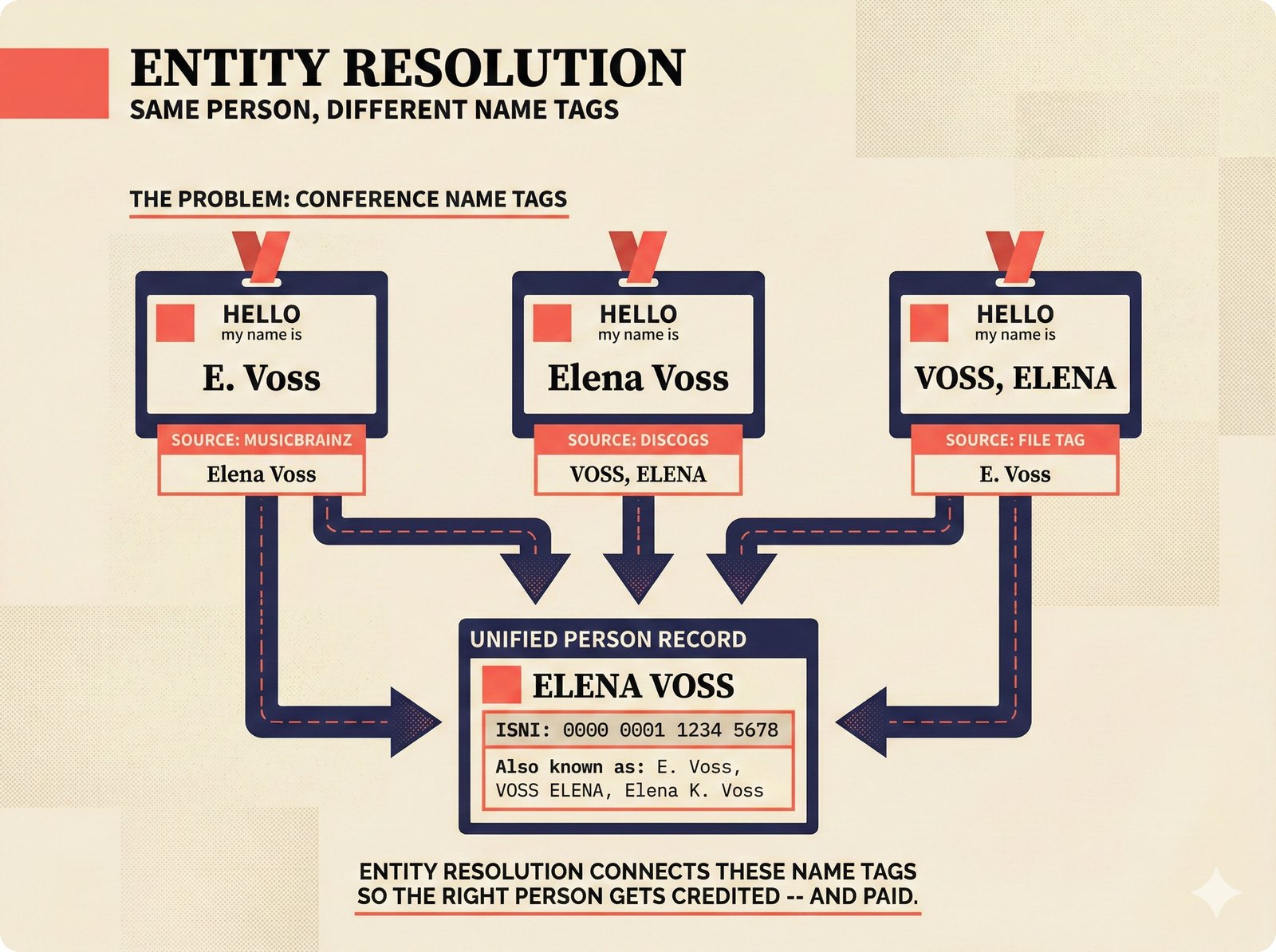 *Entity resolution ELI5: the same artist appears differently across sources -- resolution unifies variants into one identity with ISNI.* ---  *Resolution cascade: five steps from free identifier match to expensive LLM judgment -- each fires only when prior is inconclusive.* --- 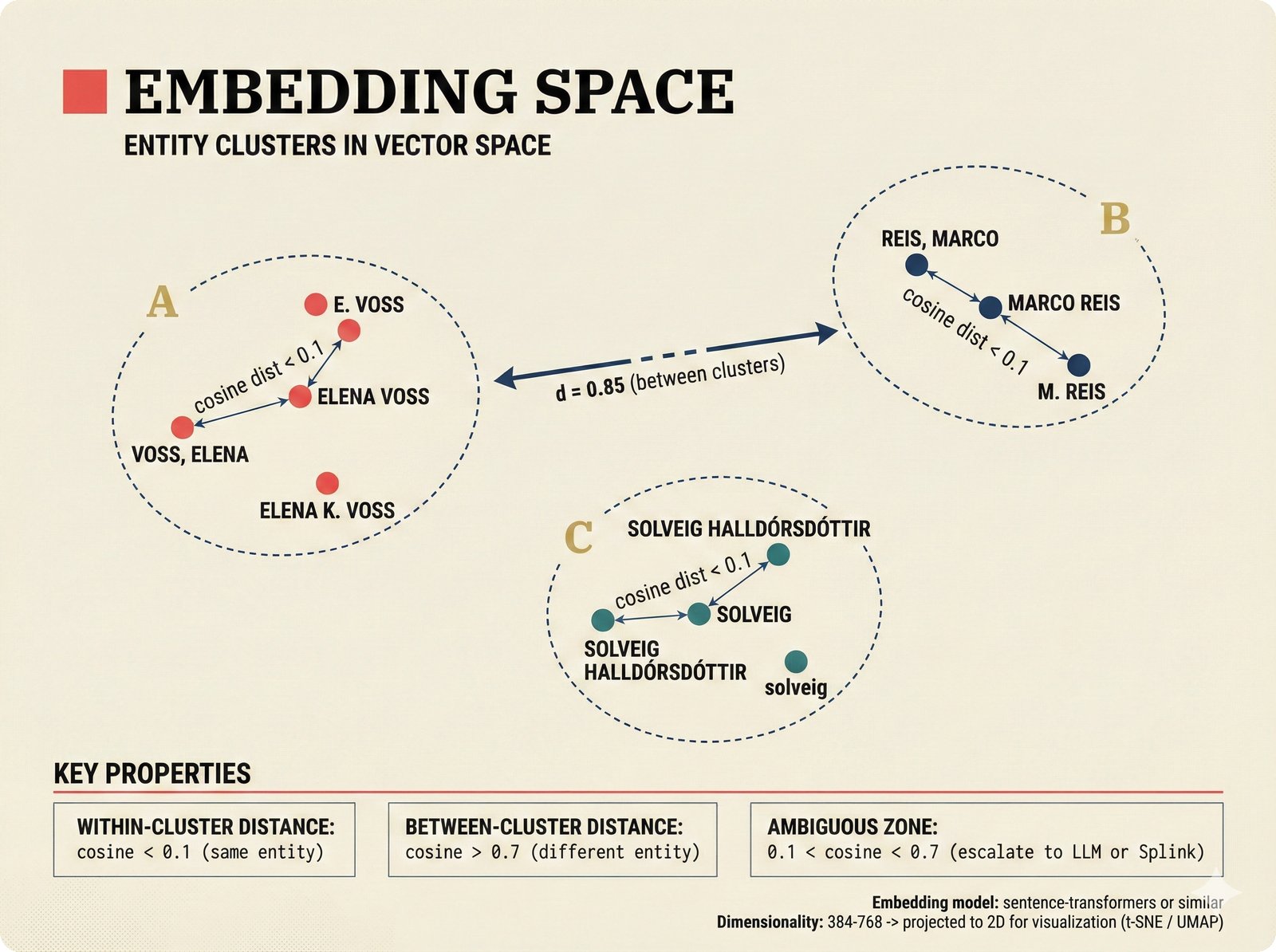 *Embedding space: three artist clusters with within-cluster distance below 0.1, between-cluster above 0.7, and ambiguous zone.* --- 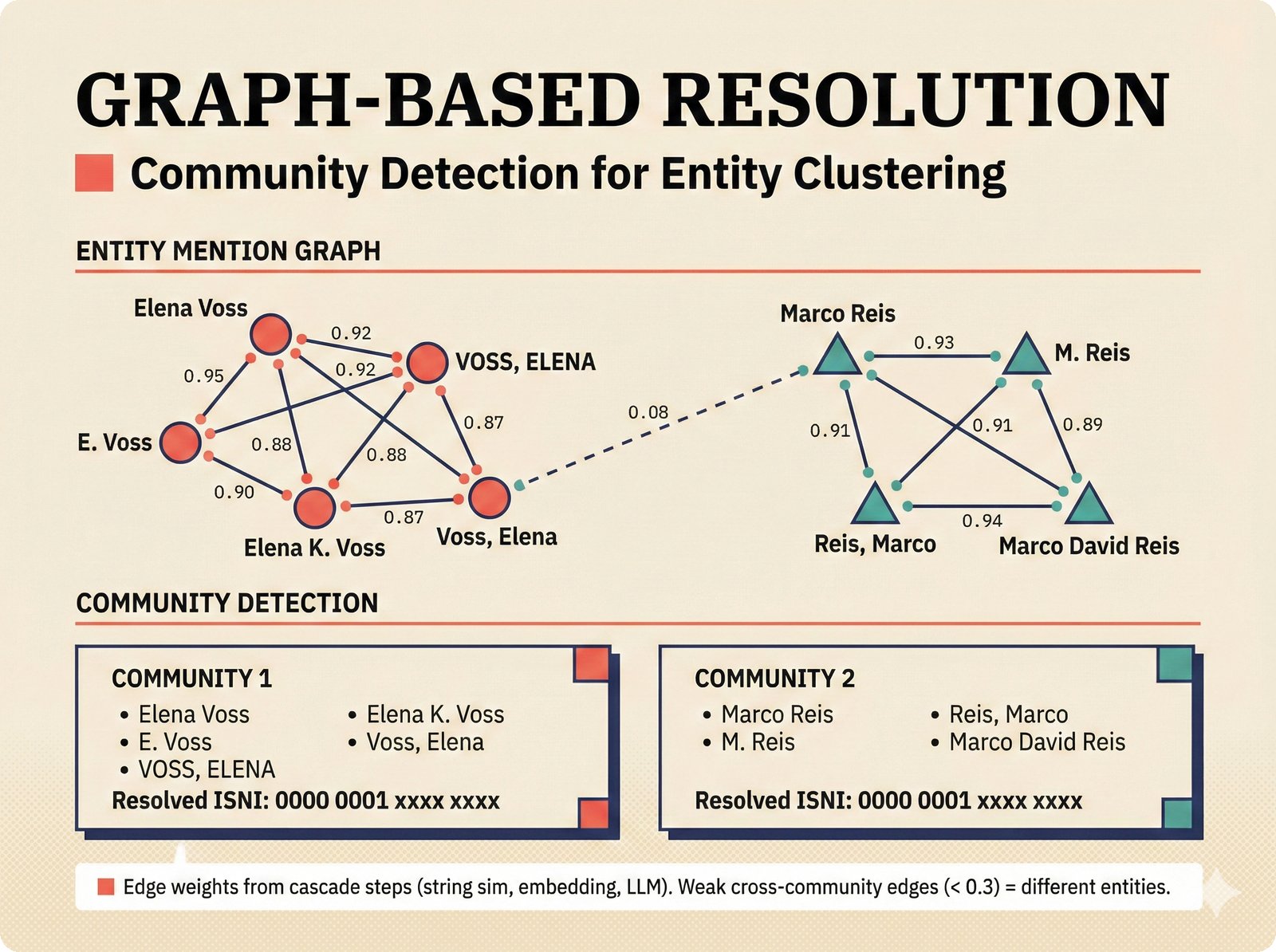 *Graph resolution: weighted edges from cascade scoring, community detection resolves mention nodes into distinct ISNI entities.* --- 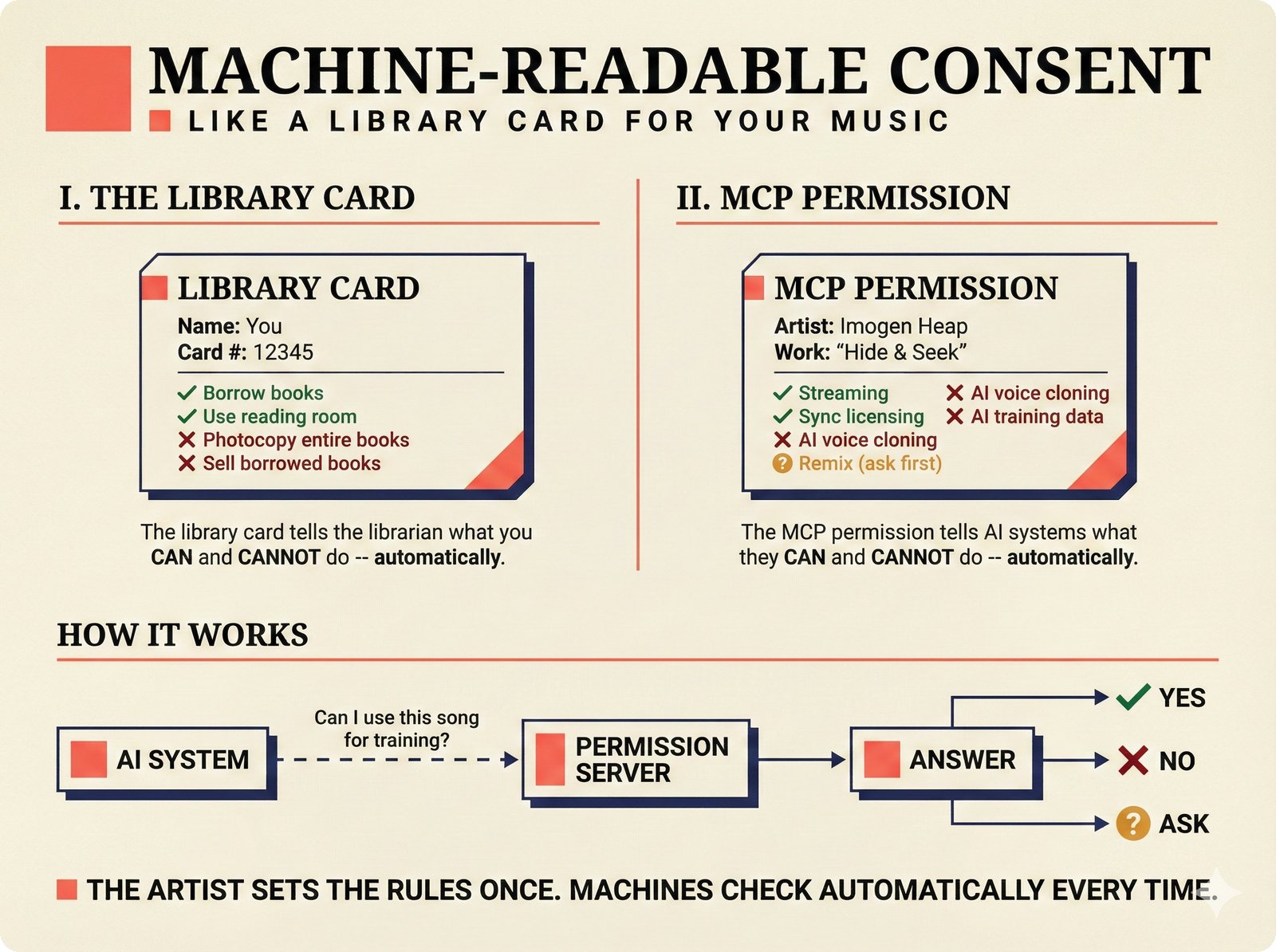 *MCP consent ELI5: library permissions map to music permissions -- streaming yes, AI voice cloning no, remix ask first.* --- 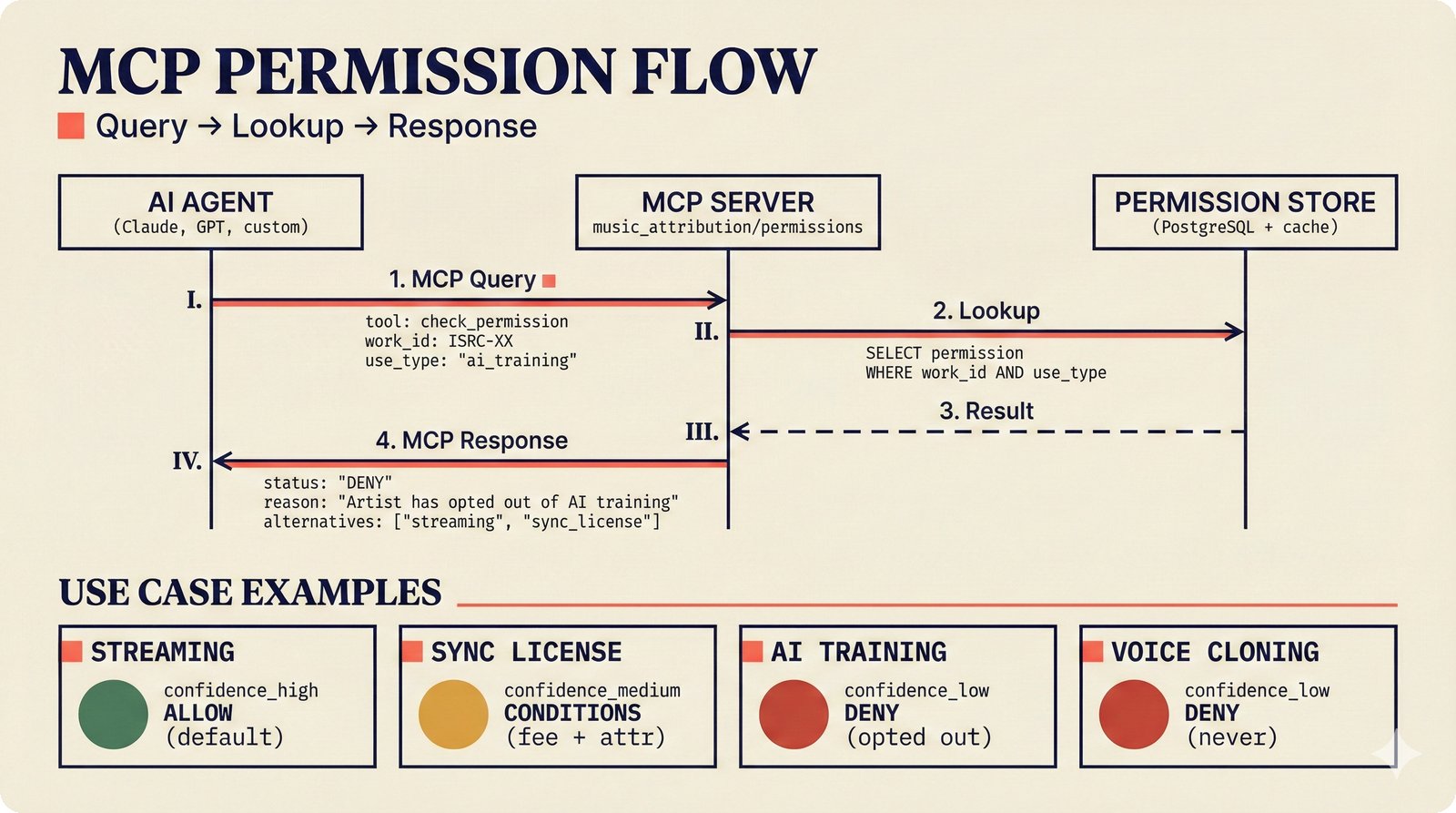 *MCP permission flow: structured ISRC query, PostgreSQL lookup, DENY response with machine-readable reason and allowed alternatives.* --- 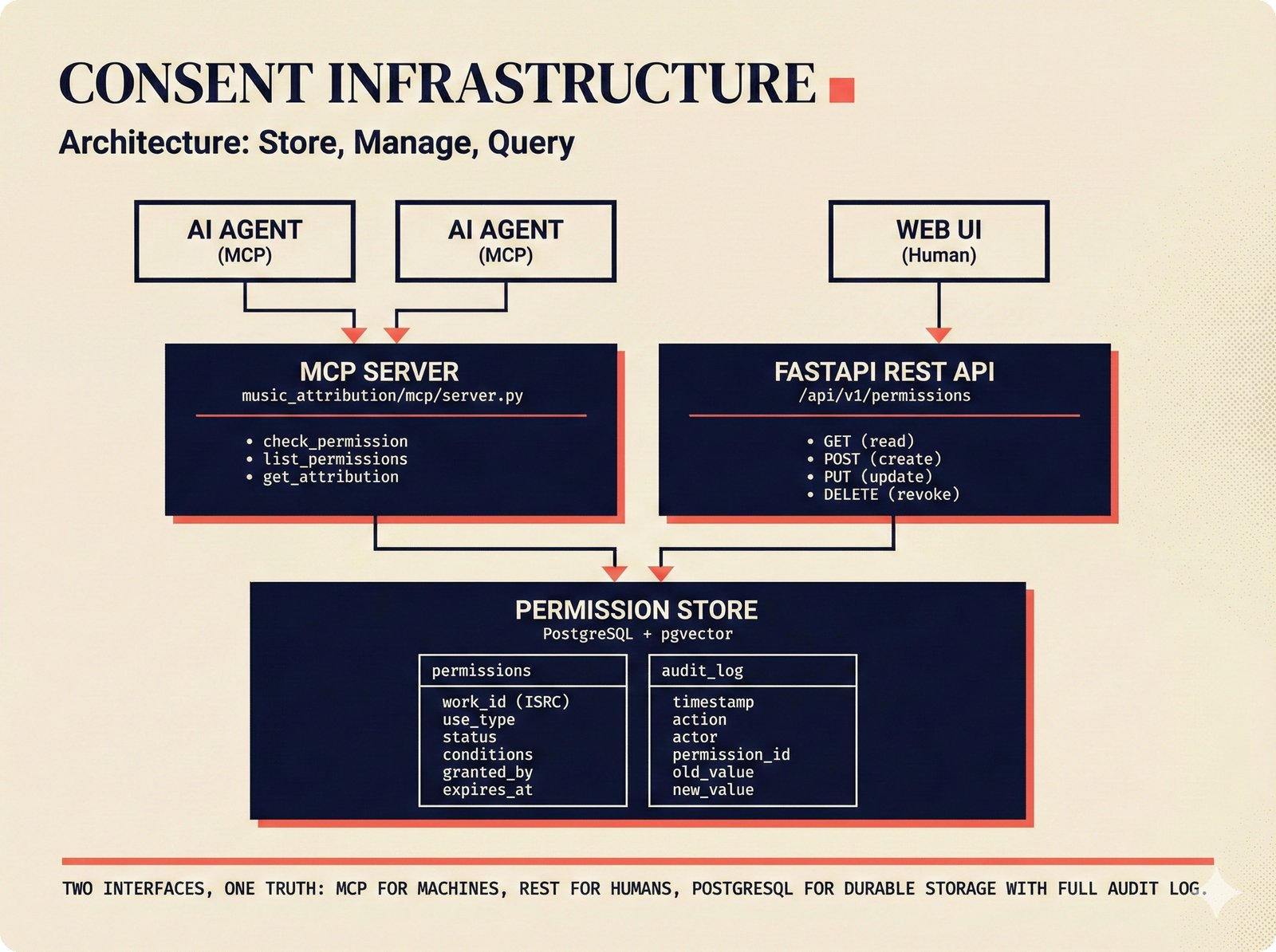 *Consent infrastructure: dual interfaces -- MCP for machines and REST for humans -- sharing permission store with audit log.* ---  *Permission matrix: granular per-work, per-use-type consent -- streaming, sync, download, AI training, voice cloning.*Scenarios¶
Scenario figures illustrate how different teams and strategies activate different subsets of the 78-node PRD network, including MVP activation paths, archetype comparisons, build-versus-buy cascades, volatility patterns, network growth, ecosystem dependencies, component clustering, and strategic ambiguity encoding.

MVP scenario: 23 nodes activated as the highest-probability path through the 78-node PRD network.

Four-archetype comparison: each team type activates different PRD subsets with varying ecosystem sensitivity.

Build vs buy cascade: the highest-influence node with 27 downstream edges -- every decision ripples from this posture.

Volatility heatmap: core infrastructure nodes are stable; ecosystem integration nodes show high volatility.

Network growth: 15 to 78 nodes across ten PRD versions maintaining a disciplined edge-to-node ratio.

Ecosystem dependencies: partnership_model node gates which company nodes activate in downstream chains.

L3 component clustering: 24 nodes grouped into TDA/ID, licensing, platform, infrastructure, and company clusters.

Strategic ambiguity: committed core selections versus ecosystem nodes deliberately preserving 0.40-0.55 optionality.
How-To Guides¶
Step-by-step visual guides for common tasks: adding data sources, reproducing paper claims, querying the API, using the agent sidebar, checking MCP permissions, running tests, deploying to production, creating figures, and contributing to the project.
9 figures -- click to expand
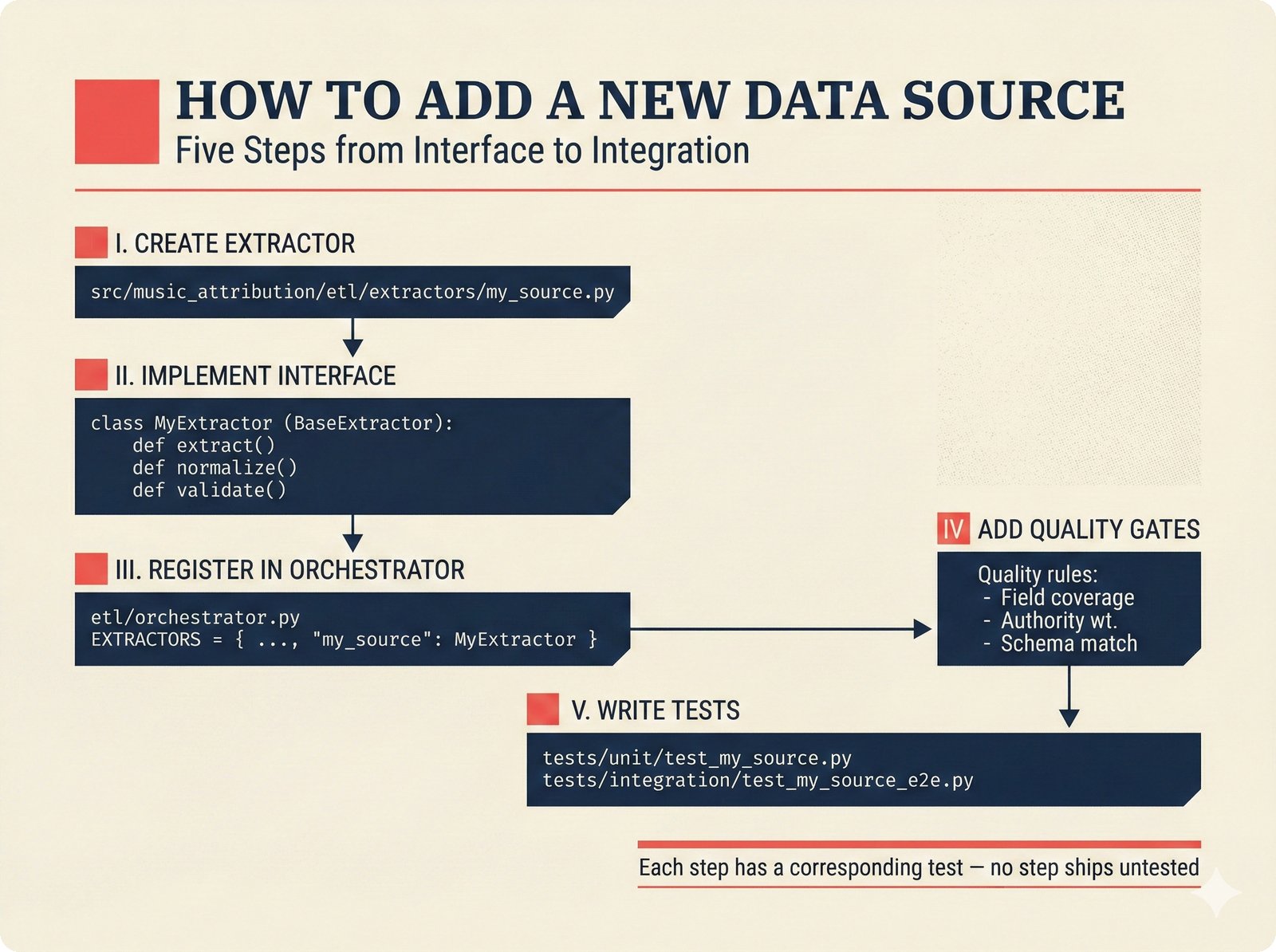 *How to add a data source: five steps from extractor creation through BaseExtractor interface to quality gate configuration and tests.* ---  *How to reproduce paper claims: paper sections map to code modules map to test commands -- every claim verifiable via make test.* --- 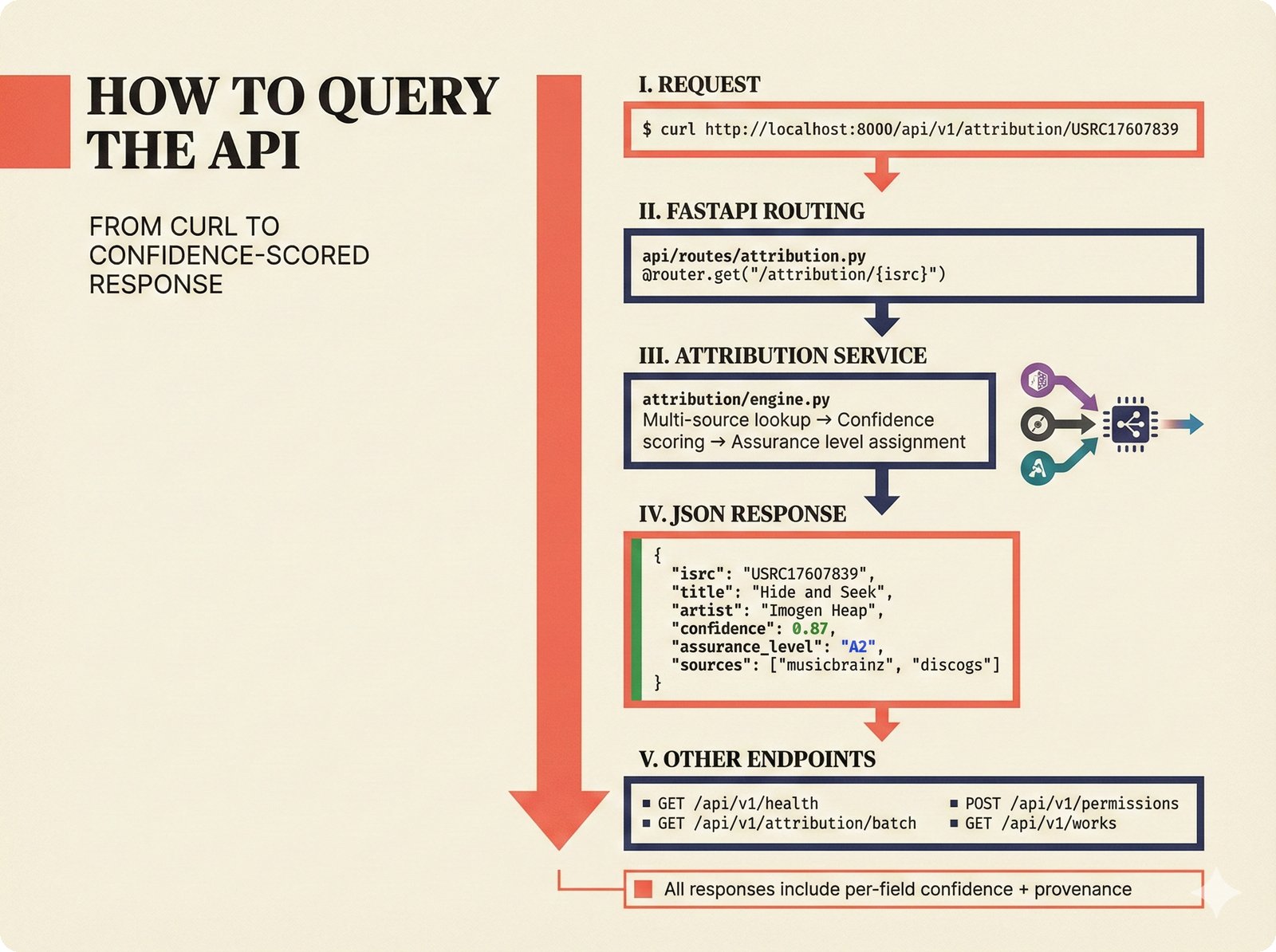 *How to query the API: curl to FastAPI to attribution engine to JSON response with per-field confidence and A0-A3 assurance.* ---  *How to use the agent sidebar: natural-language query, tool invocation, transparent confidence-scored answer with provenance.* --- 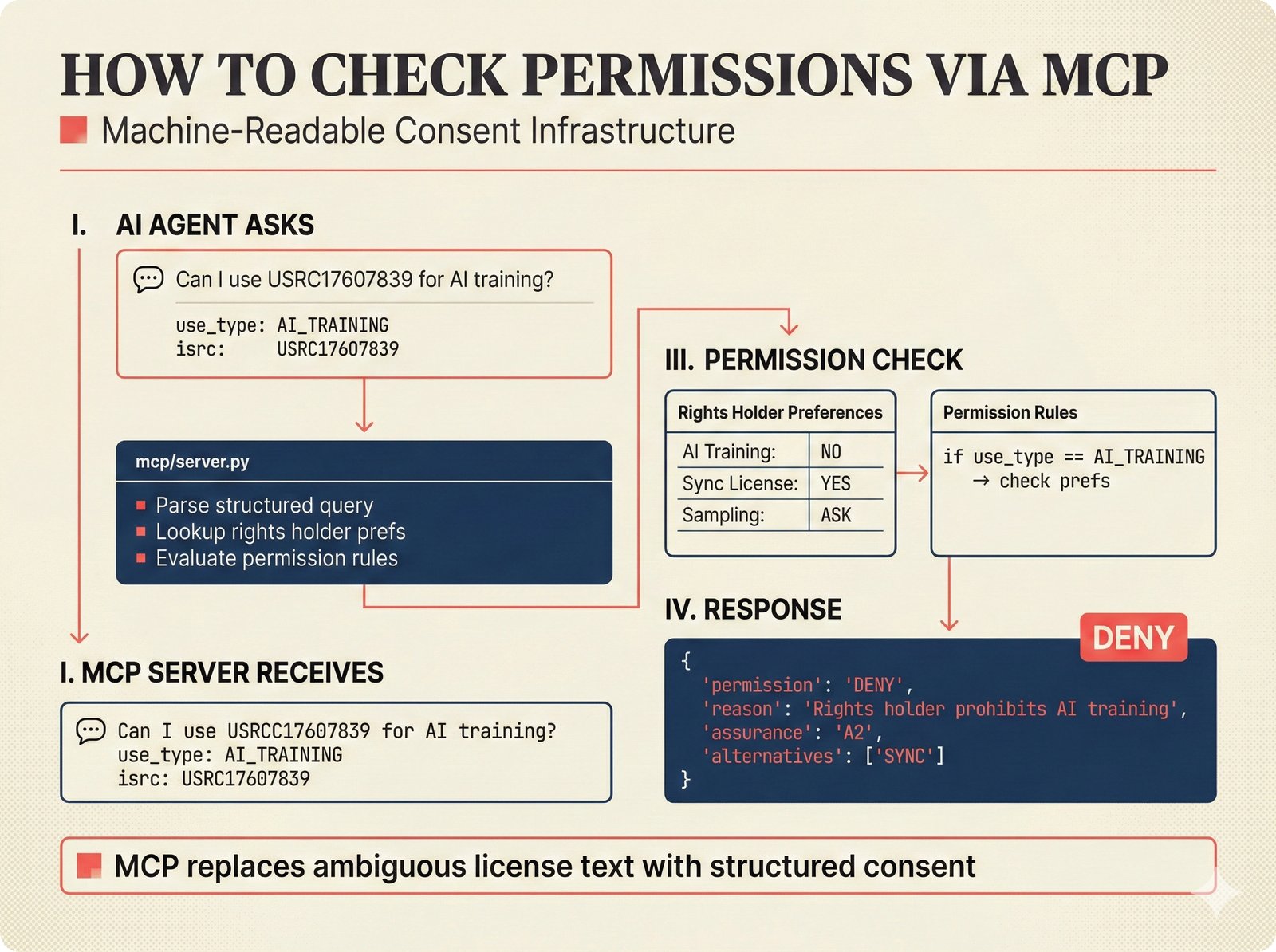 *How to check MCP permissions: query training rights, server evaluates, returns structured ALLOW/DENY with assurance level.* --- 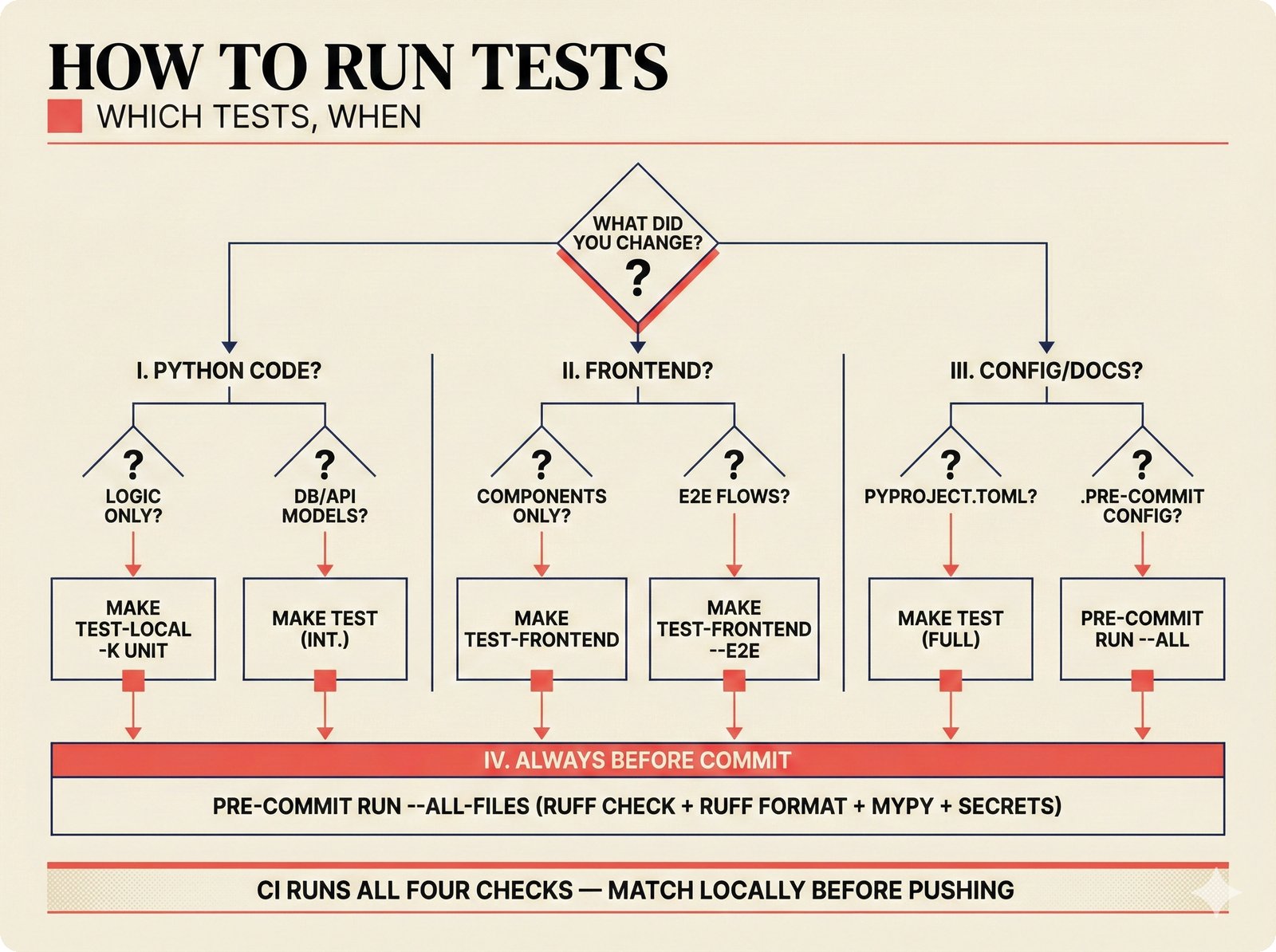 *How to run tests: decision tree branching from Python backend, frontend, or config change to the correct make command.* --- 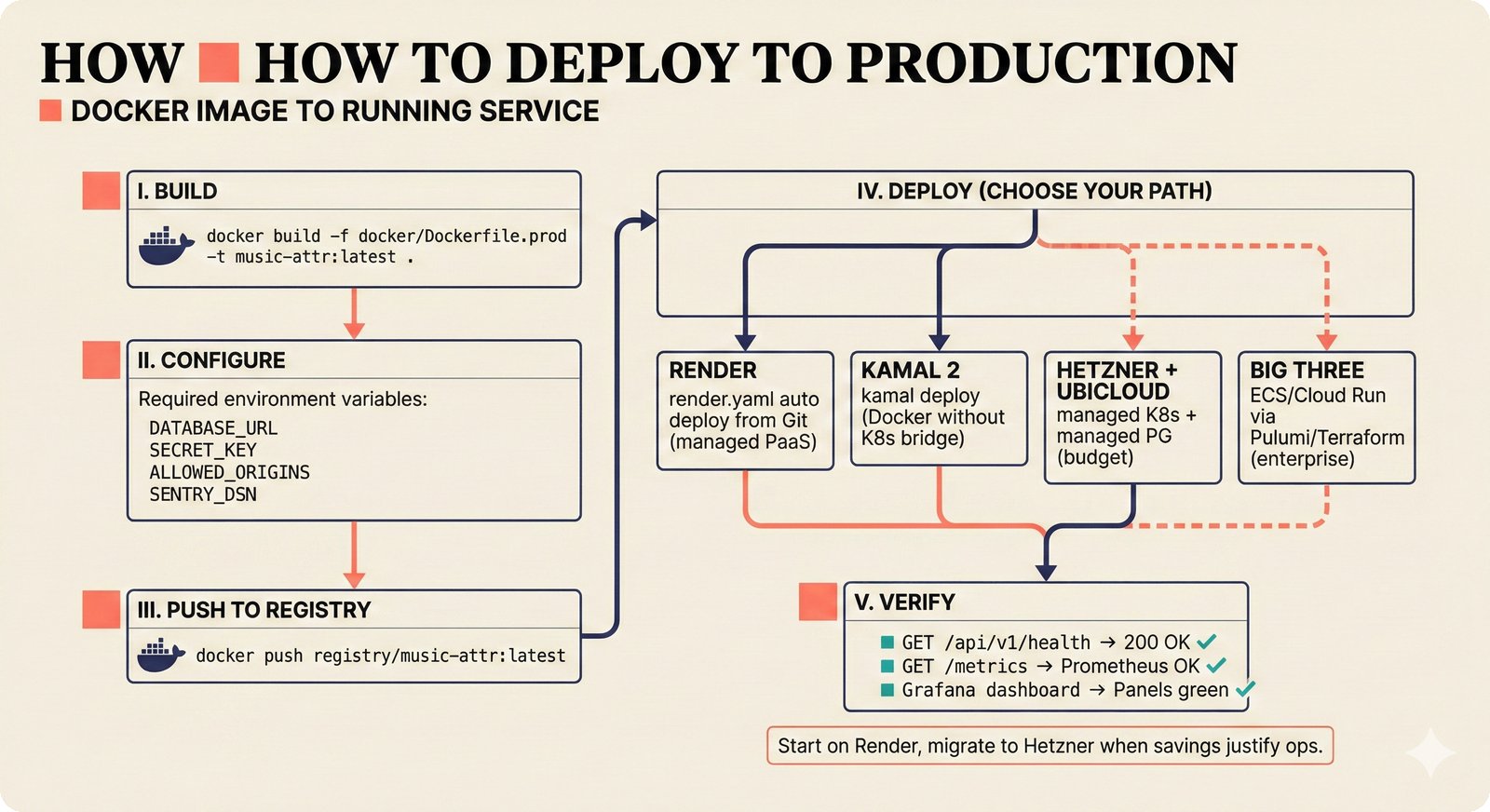 *How to deploy: Docker build, configure, push, then branch to Render, Kamal 2, Hetzner+Ubicloud, or Big Three -- health check last.* --- 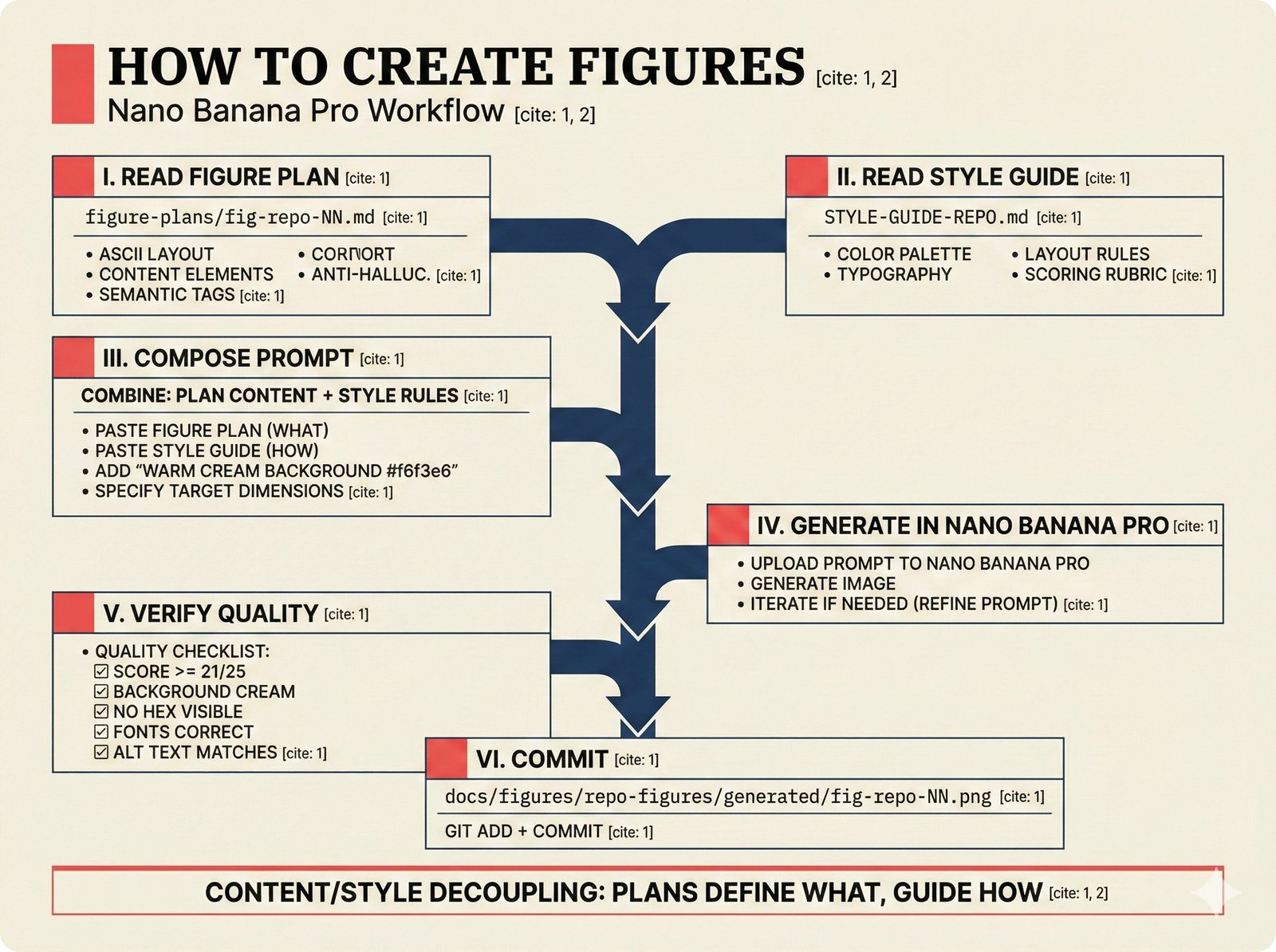 *How to create figures: read plan, compose prompt, generate via Nano Banana Pro, verify quality, commit -- content-style decoupling.* ---  *How to contribute: fork, branch, code under CLAUDE.md rules, pre-commit hooks, pytest, and PR -- quality gates non-negotiable.*Technology Trends¶
Trend figures track the fast-moving technology landscape that influences PRD node selections -- agent framework consolidation, pgvector performance, OpenTelemetry GenAI stack, evaluation frameworks, edge AI platforms, graph knowledge bases, STIM revenue flows, and the trend-to-scaffold implication matrix.

Agent framework consolidation: PydanticAI (typed, Pydantic-native), LangGraph (graph orchestration), CrewAI/AG2 (multi-agent).

pgvector performance: 471 QPS at 99% recall -- validates the PostgreSQL Unified architecture decision.

OpenTelemetry GenAI: PydanticAI instrumented via Logfire to any OTel-compatible observability backend.

Eval framework maturity: PydanticAI mocks (fast), Promptfoo CI regression (automated), Braintrust golden datasets (comprehensive).

Edge AI platforms: Cloudflare Workers AI, Deno Deploy, and Supabase Edge Functions -- latency versus ecosystem trade-offs.

Graph knowledge bases: Neo4j Aura managed versus Apache AGE co-located with PostgreSQL plus LightRAG hybrid.

STIM revenue flow: AI-generated output triggers confidence scoring, per-output royalty calculation, and rights holder distribution.

Trend-to-scaffold matrix: ten technology trends mapped to specific PRD node impacts and option reclassifications.
Voice Agent¶
The voice agent figures cover the complete real-time voice pipeline for music attribution -- from full-stack architecture and latency budgets through STT/TTS/LLM component selection, evaluation benchmarks, cost economics, compliance, and the implementation-level module architecture including config anatomy, pipeline assembly, persona layers, drift detection, tool bridging, guardrails, memory integration, protocols, frontend components, testing, and extension points.
48 figures -- click to expand
### Infrastructure & Frameworks (fig-voice-01 to 06) 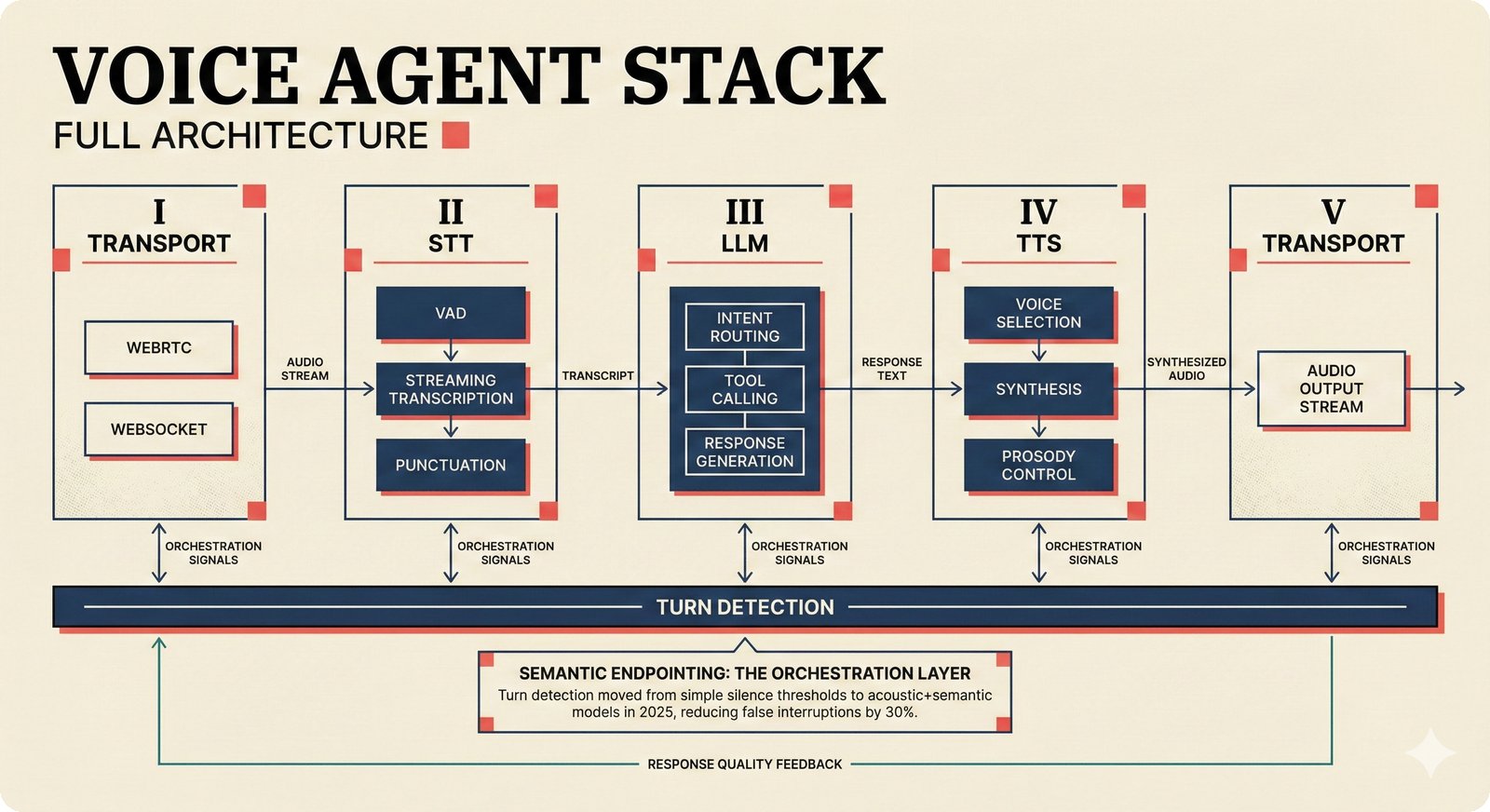 *Five-panel architecture diagram showing the complete voice agent pipeline from transport input through STT, LLM, TTS, and back to transport output, with semantic endpointing as the critical orchestration layer.* --- 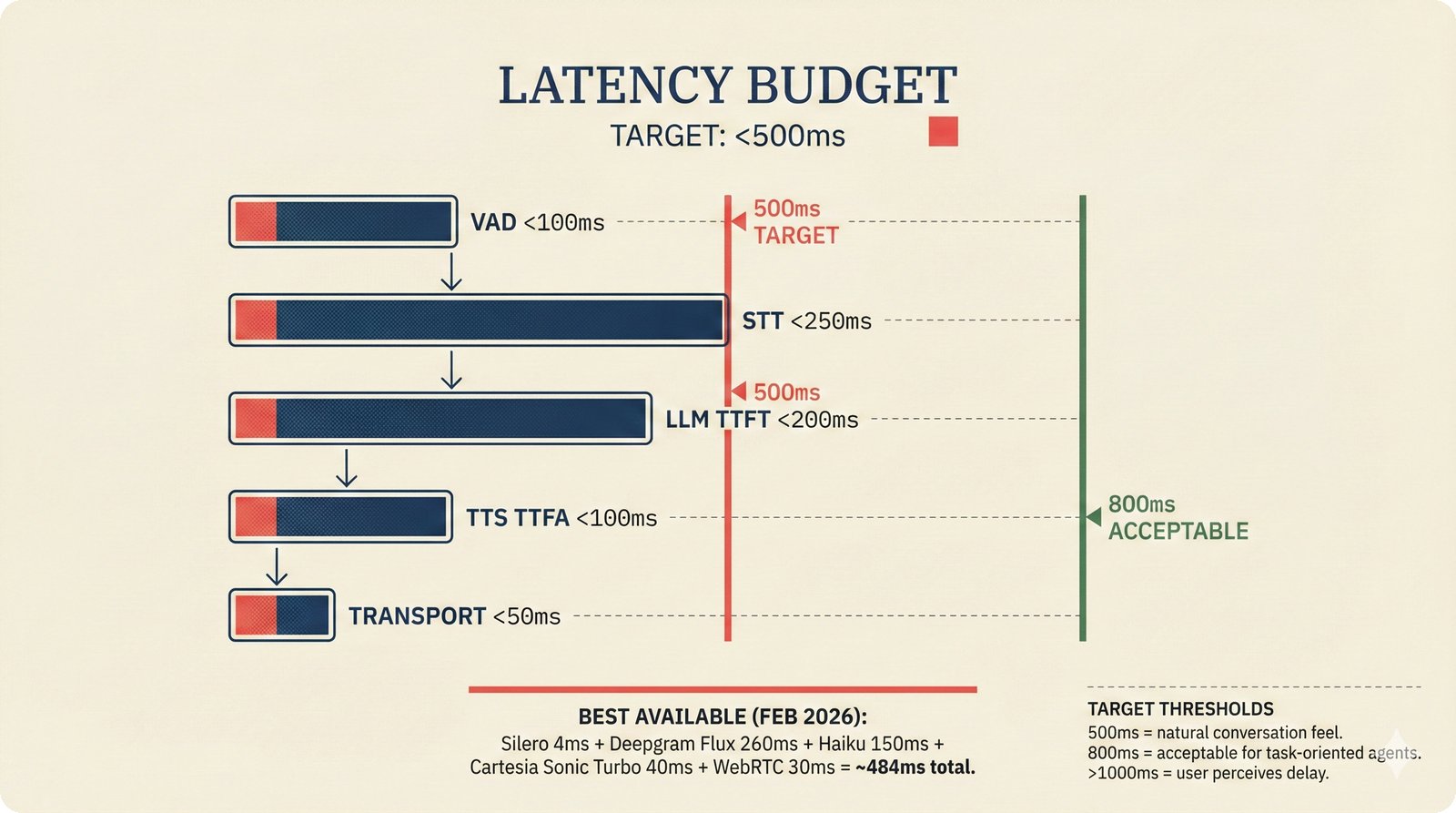 *Vertical timeline showing the voice agent latency budget across five pipeline stages, targeting under 500 milliseconds total with concrete Feb 2026 best-available stack achieving ~484ms.* --- 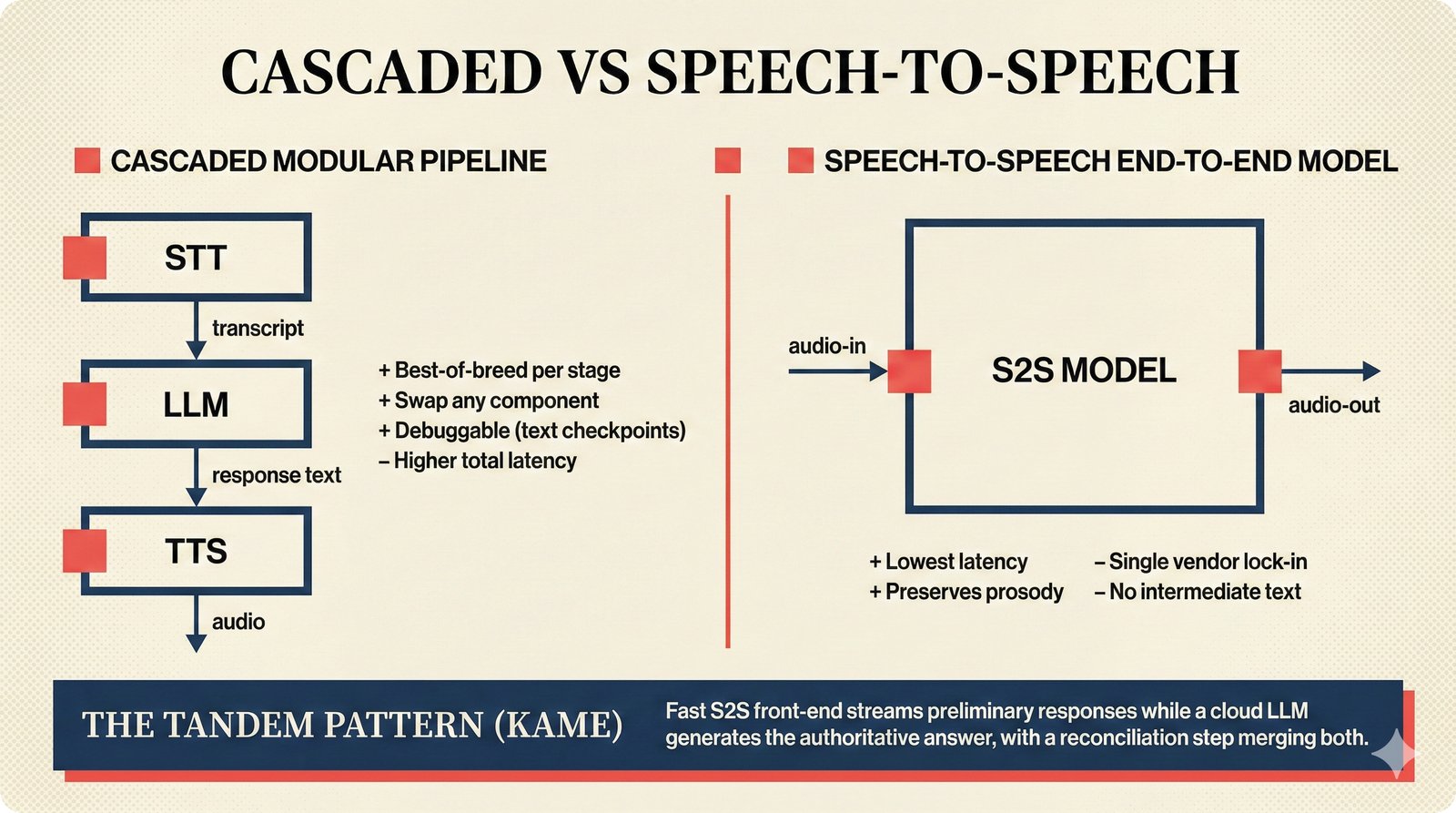 *Split-panel comparison of cascaded modular pipeline versus speech-to-speech end-to-end architecture, with the tandem pattern combining both approaches for optimal latency and reasoning depth.* --- 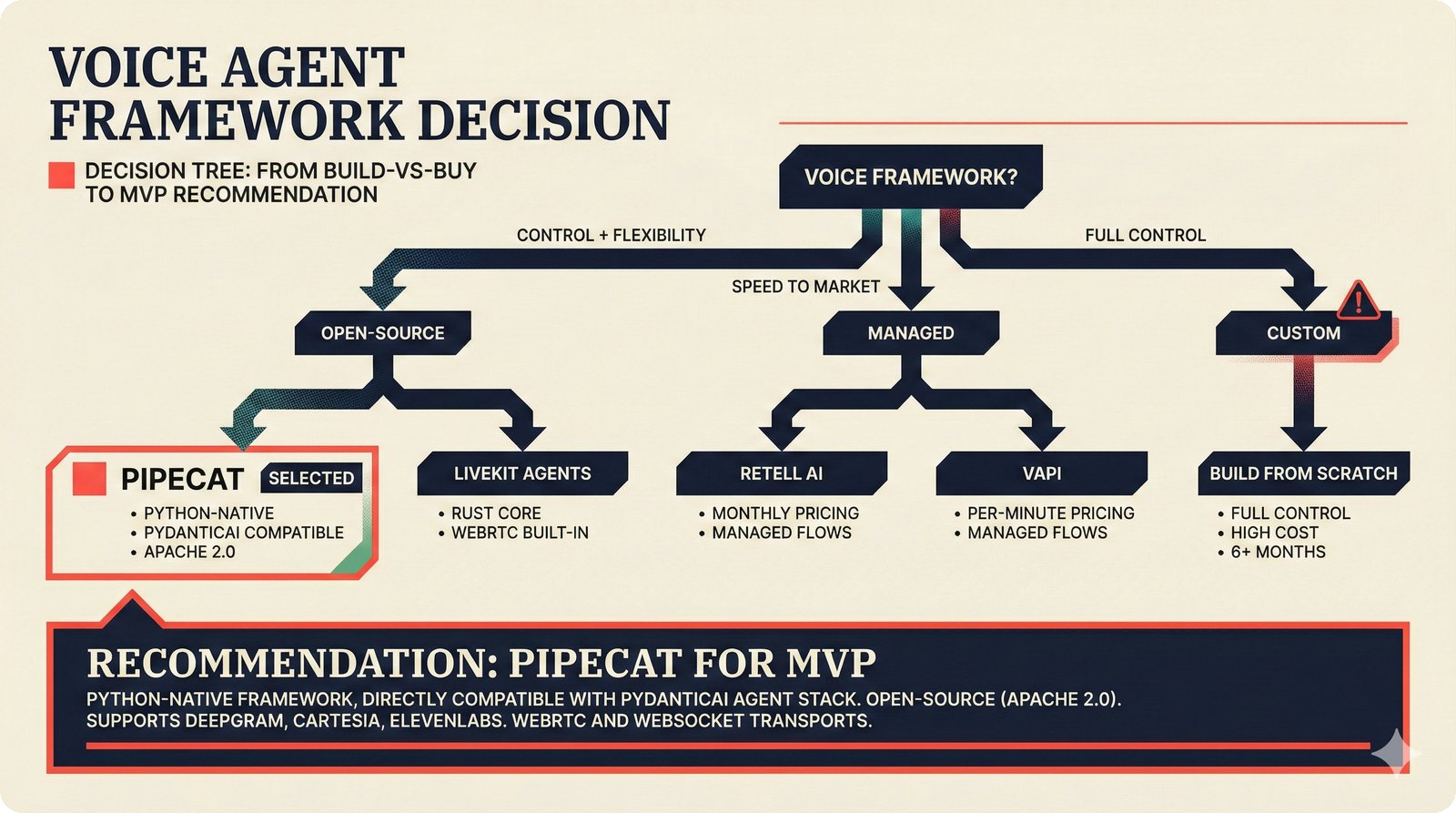 *Decision tree mapping the voice agent framework choice from build-vs-buy through open-source and managed options, with Pipecat selected as the recommended MVP framework for Python-native PydanticAI compatibility.* --- 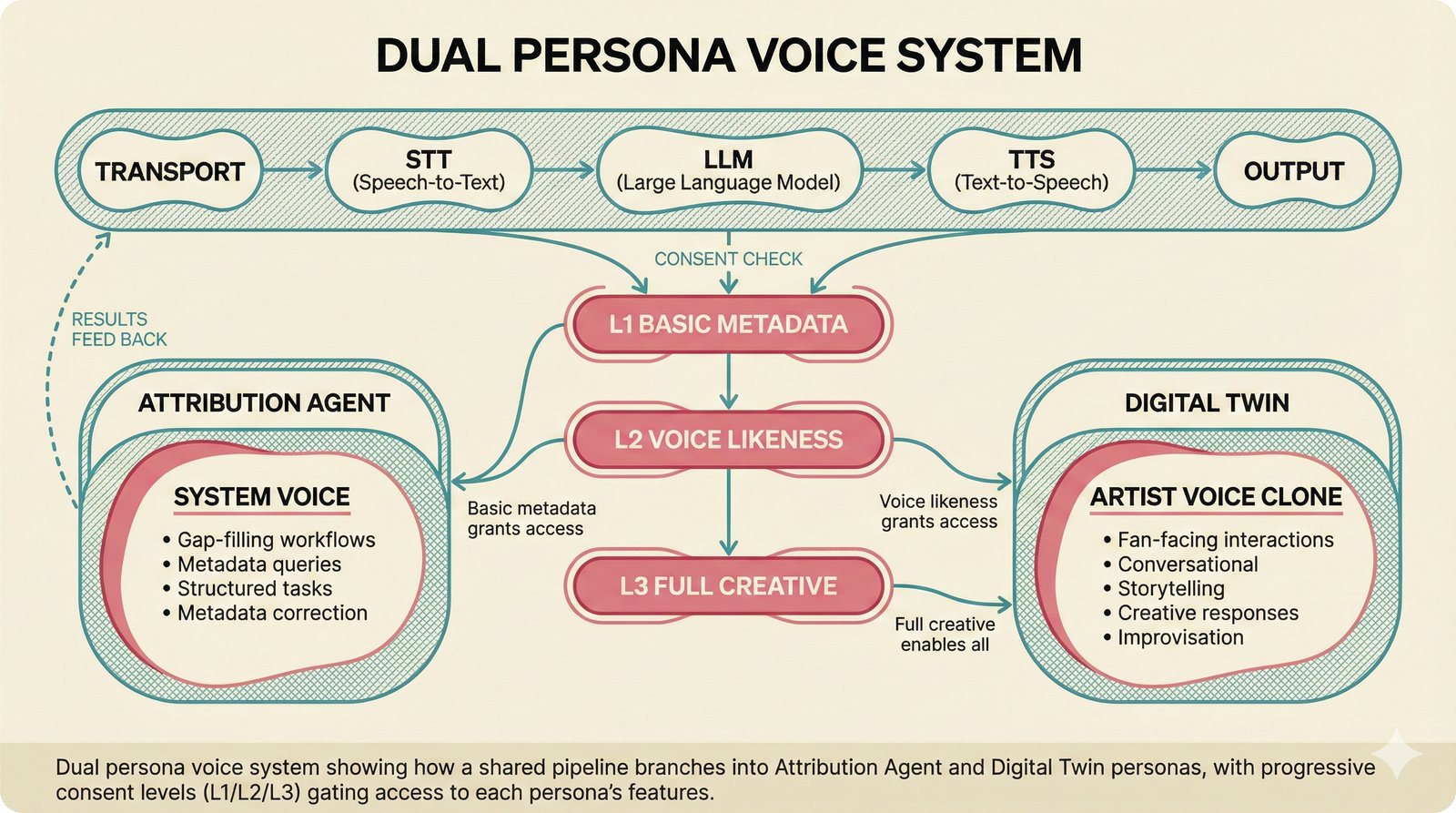 *Dual persona voice system showing how a shared pipeline branches into Attribution Agent and Digital Twin personas, with progressive consent levels (L1/L2/L3) gating access to each persona's features.* --- 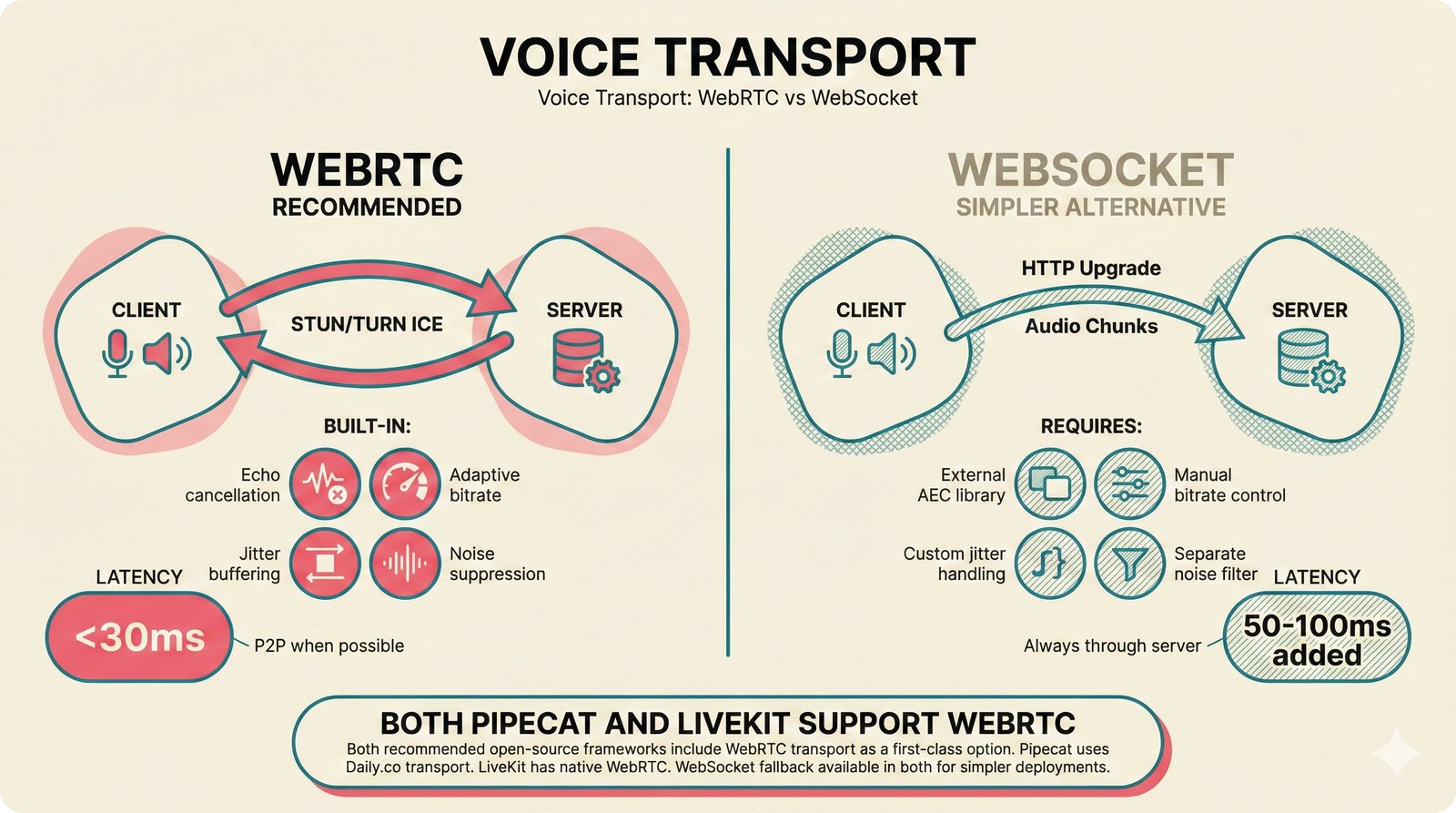 *Split-panel comparison of WebRTC and WebSocket voice transport protocols, with WebRTC recommended for its sub-30ms latency and built-in audio processing capabilities.* --- ### STT / TTS / LLM Components (fig-voice-07 to 21)  *Four-quadrant STT model positioning chart showing accuracy versus cost for Feb 2026, with category leaders identified for production, self-hosted, accuracy-optimized, and edge deployment scenarios.* ---  *Scatter plot showing STT models positioned by accuracy versus latency, with a coral Pareto frontier line connecting models where no alternative dominates on both axes simultaneously.* --- 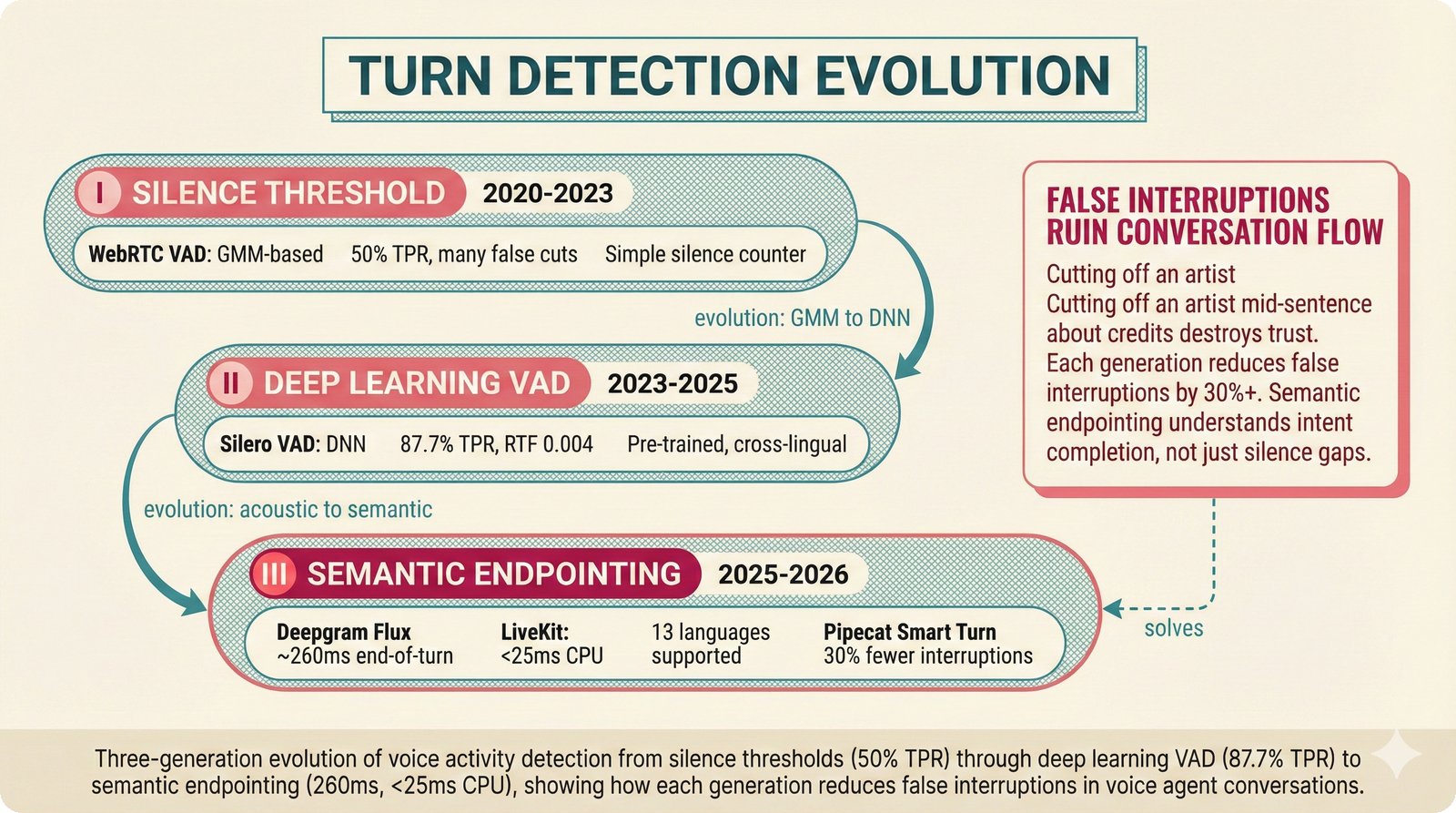 *Three-generation evolution of voice activity detection from silence thresholds through deep learning VAD to semantic endpointing, showing how each generation reduces false interruptions.* --- 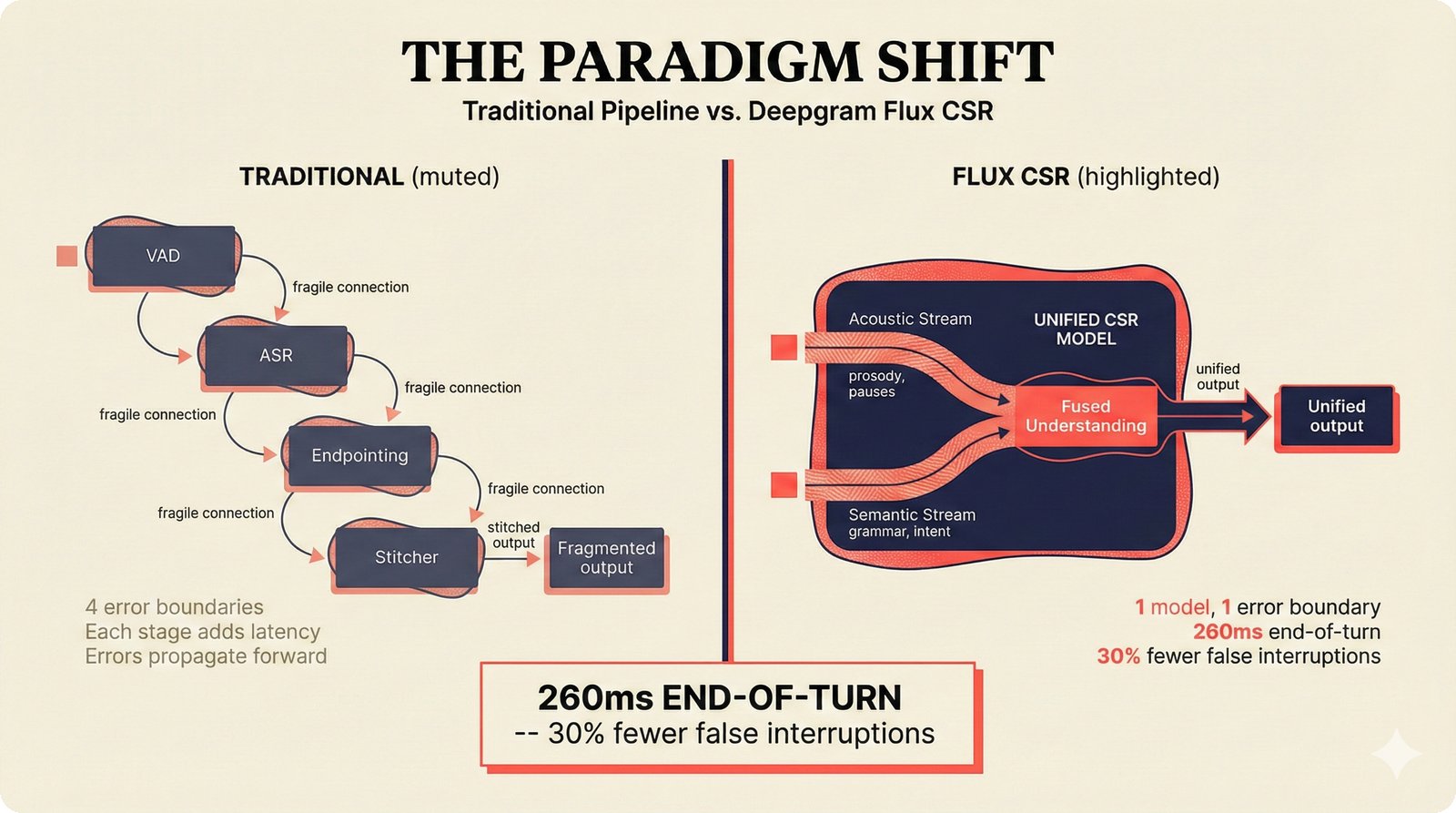 *Split-panel comparison of traditional fragmented speech recognition pipeline versus Deepgram Flux CSR unified model with acoustic and semantic stream fusion achieving 260ms end-of-turn latency.* ---  *Two-row landscape of TTS models as of February 2026: commercial providers versus open-source models with parameter counts, latency, cost, and license for each.* --- 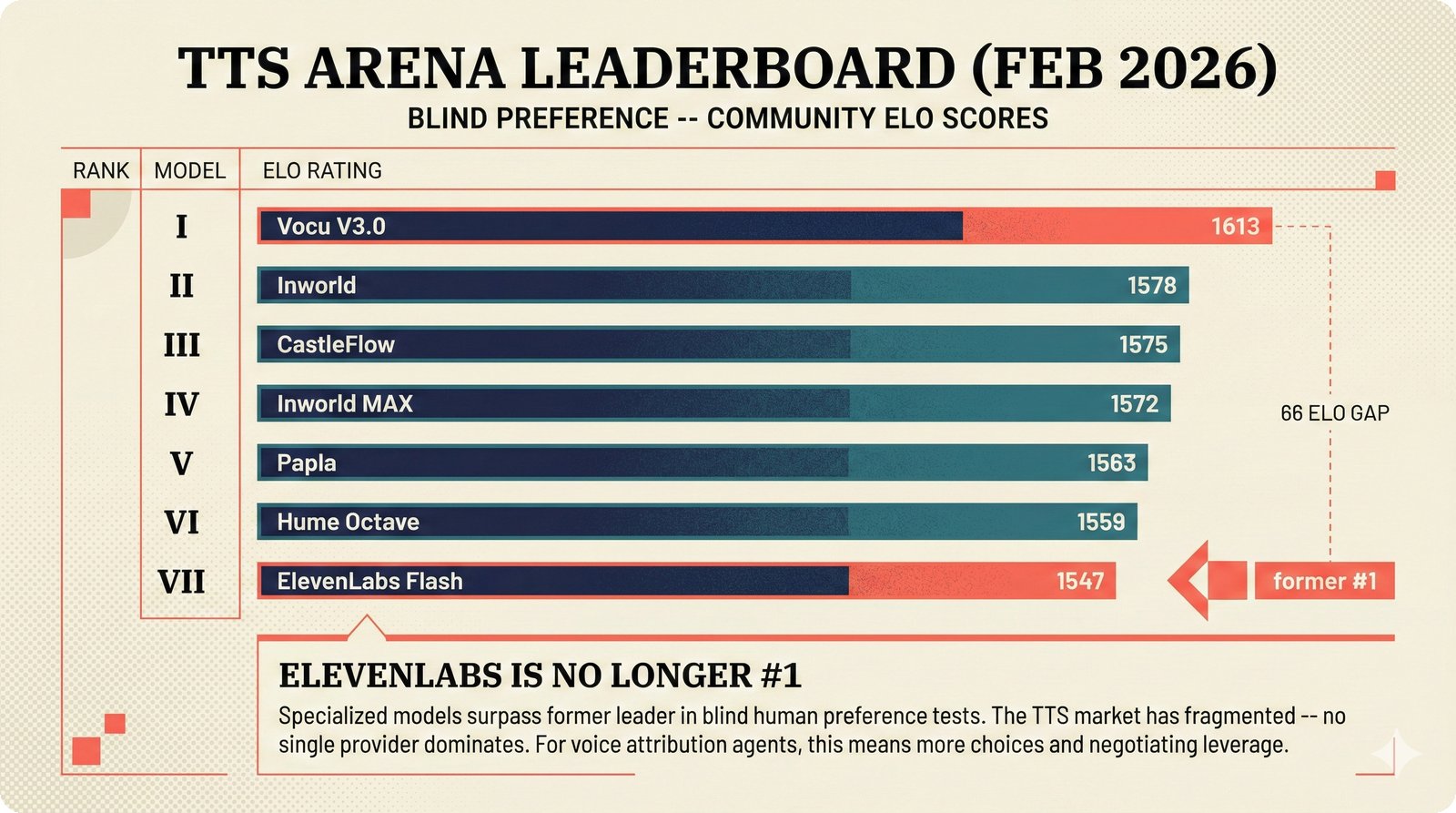 *Horizontal bar chart of TTS Arena blind preference leaderboard as of February 2026, showing Vocu V3.0 at #1 and ElevenLabs Flash displaced to #7 by specialized competitors.* ---  *Three-panel showcase of the open-source TTS revolution: Chatterbox, Orpheus, and Kokoro reducing TTS cost by 100x through self-hosting.* --- 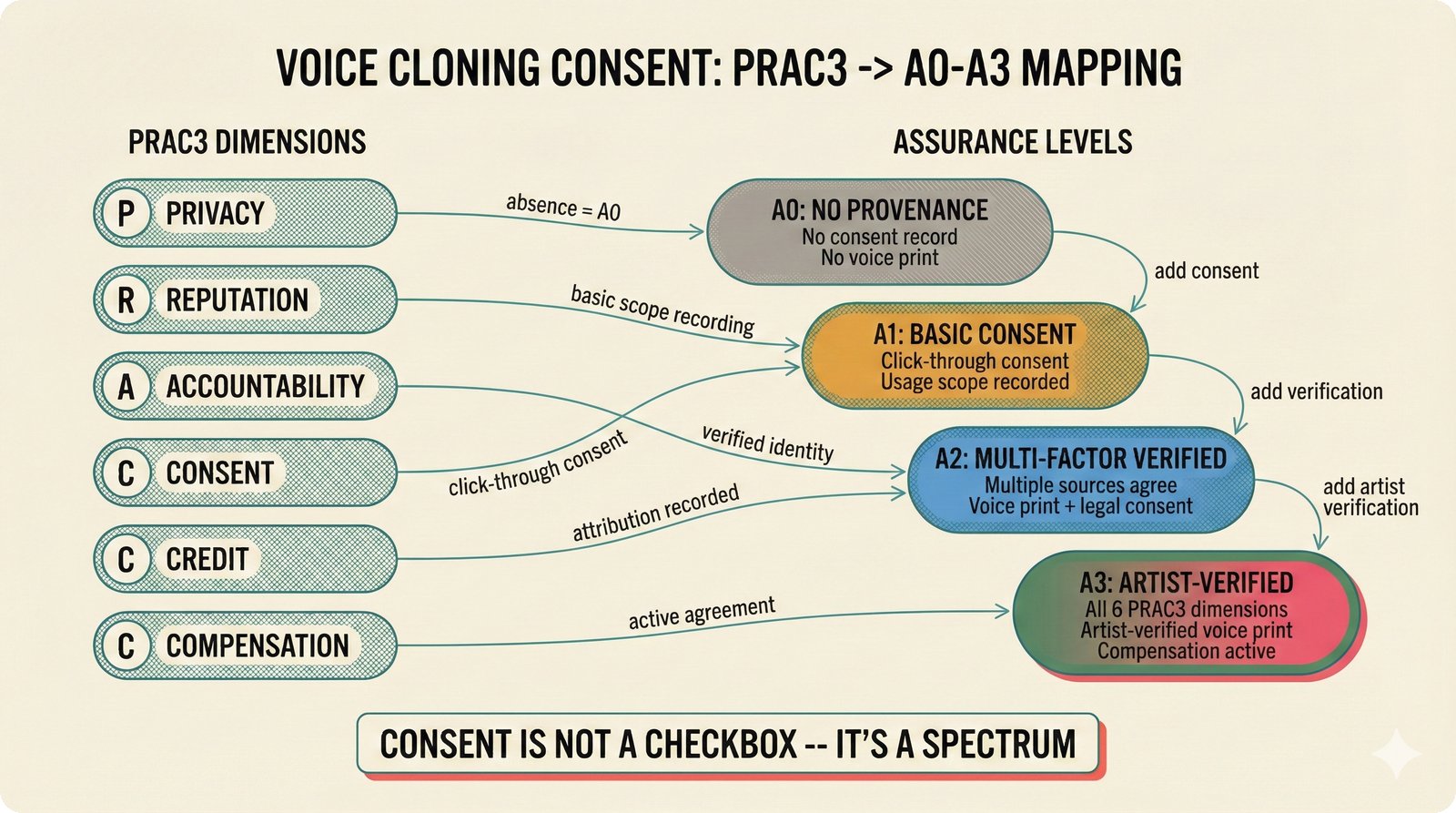 *Flowchart mapping PRAC3 voice cloning consent dimensions to A0-A3 assurance levels, showing consent as a spectrum from no provenance to artist-verified voice prints.* --- 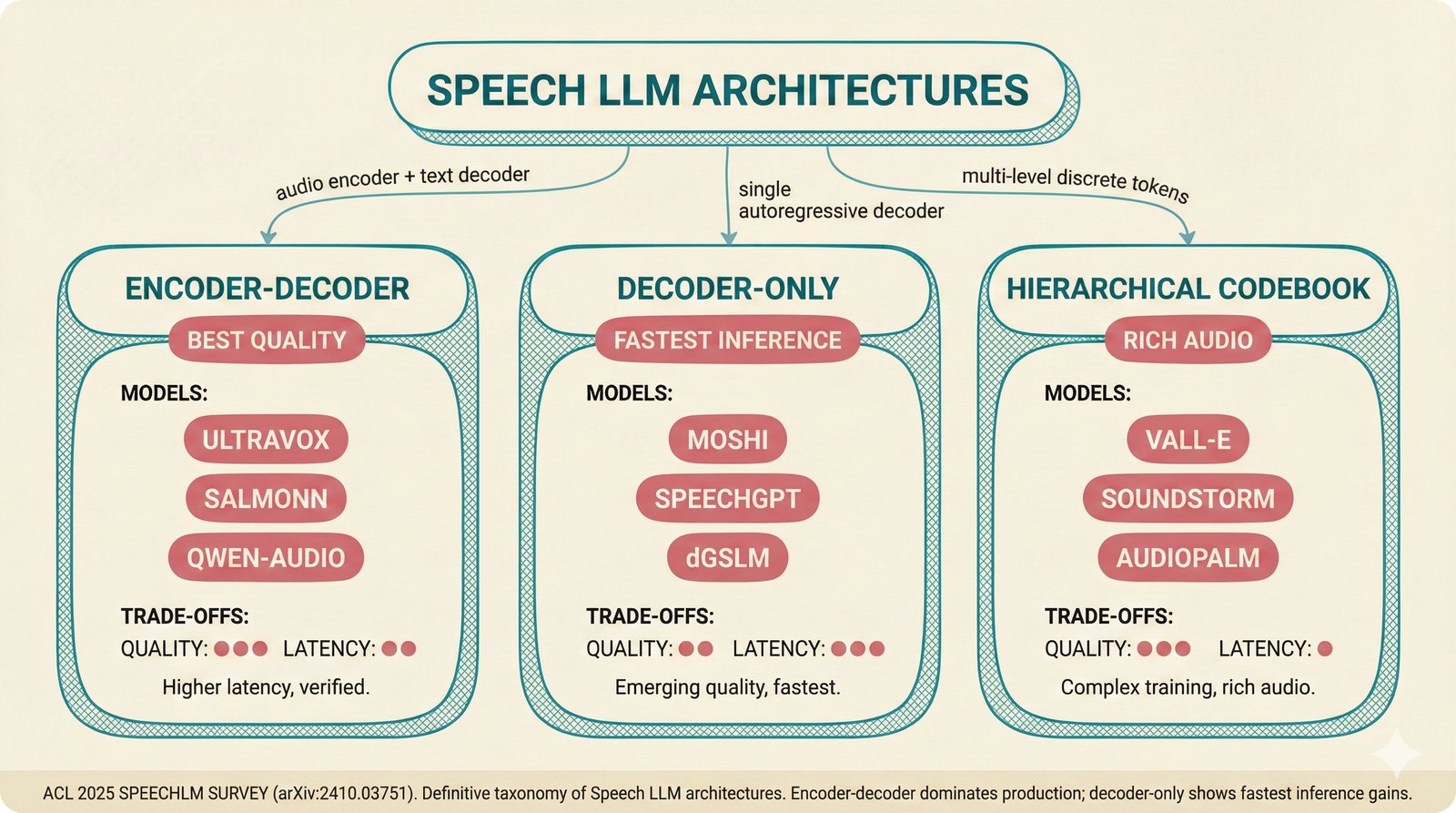 *Three-family taxonomy of Speech LLM architectures from the ACL 2025 survey with quality and latency indicators.* ---  *Hero figure showing Ultravox v0.7 achieving 97.7% versus GPT Realtime (86.7%) and Gemini Live (86.0%), with simplified architecture diagram.* --- 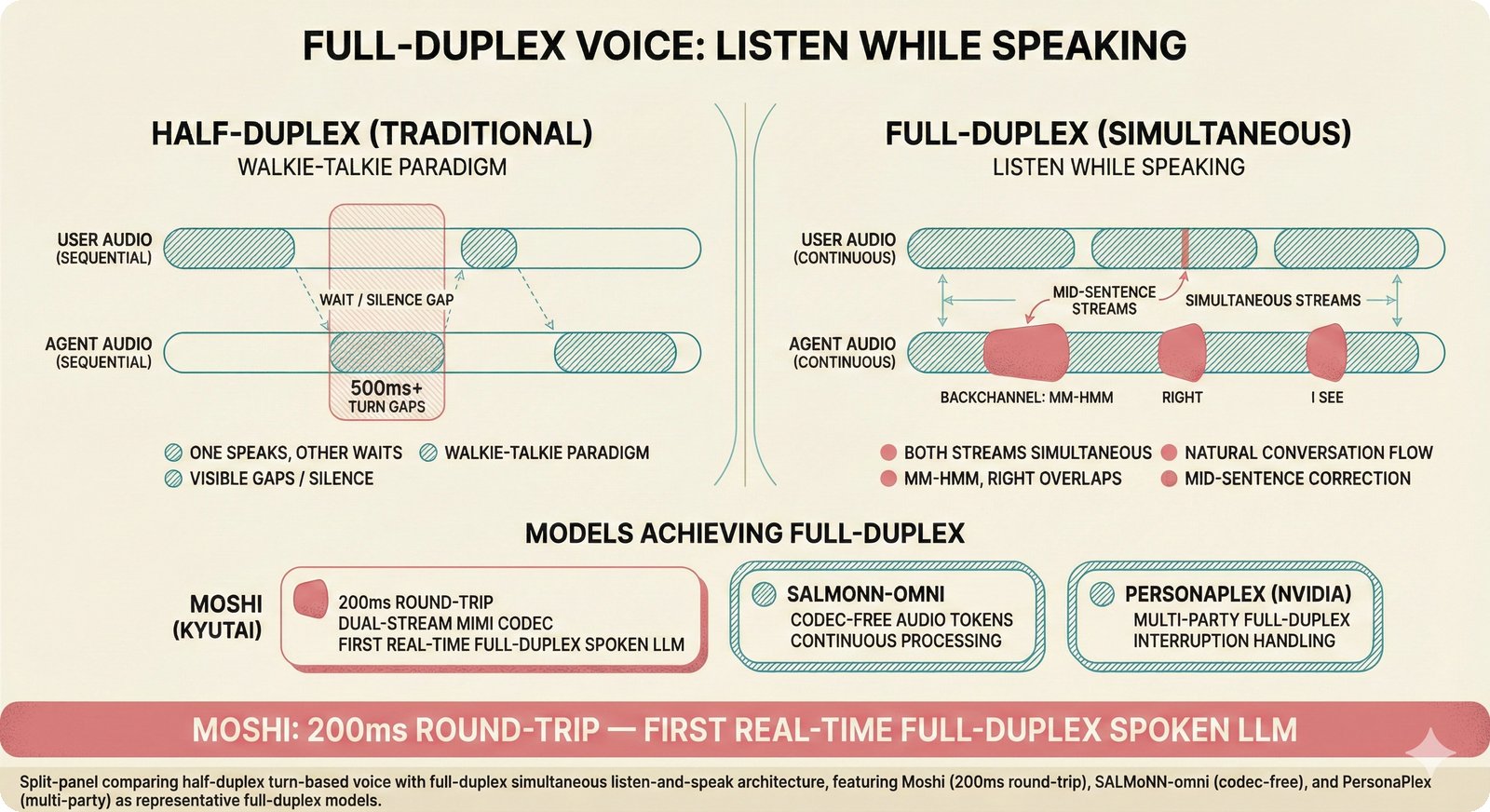 *Split-panel comparing half-duplex turn-based voice interaction with full-duplex simultaneous listen-and-speak architecture.* --- 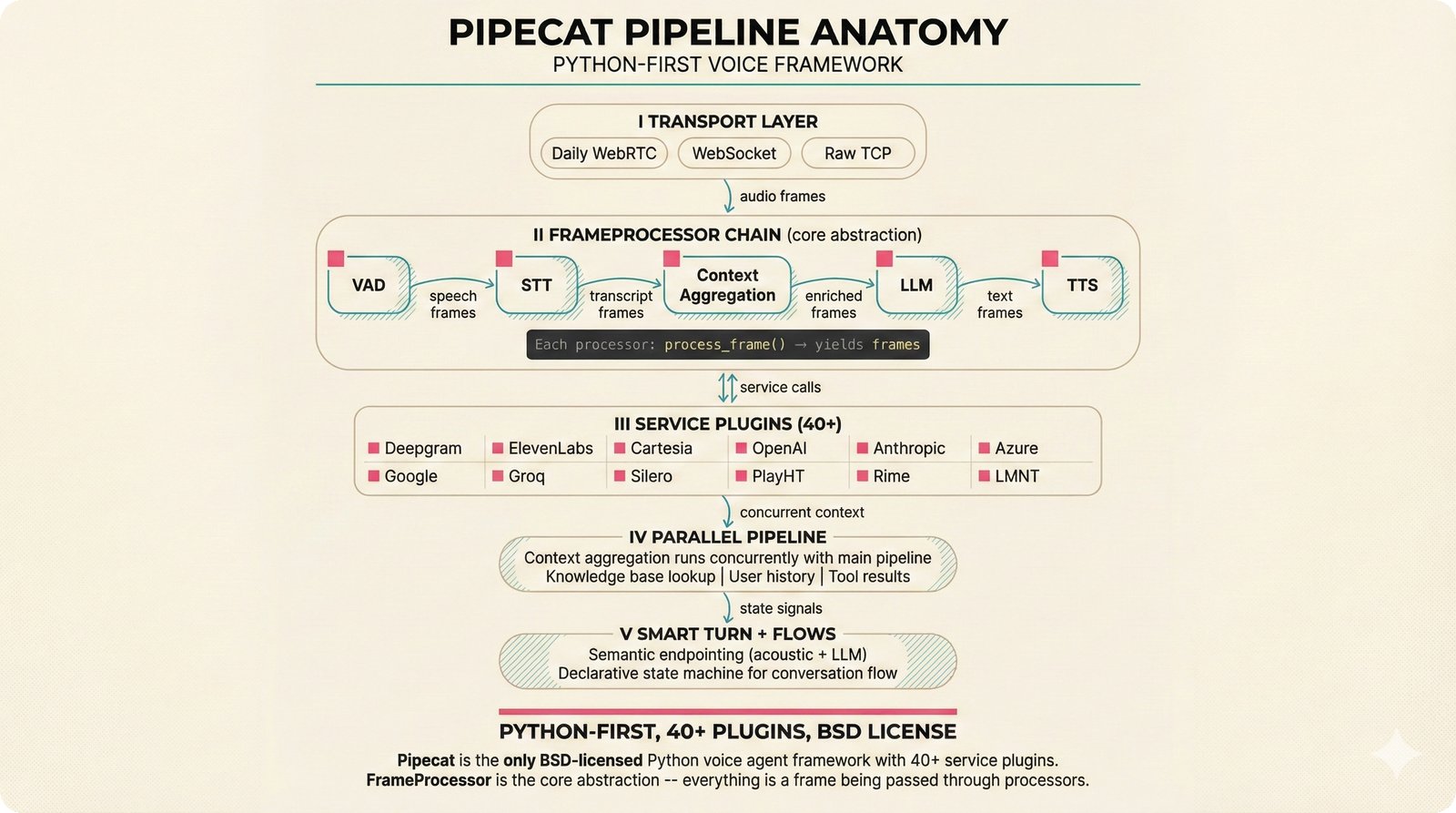 *Step-by-step anatomy of a Pipecat voice agent pipeline showing transport, FrameProcessor chain, 40+ service plugins, parallel pipeline, and Smart Turn with Flows.* --- 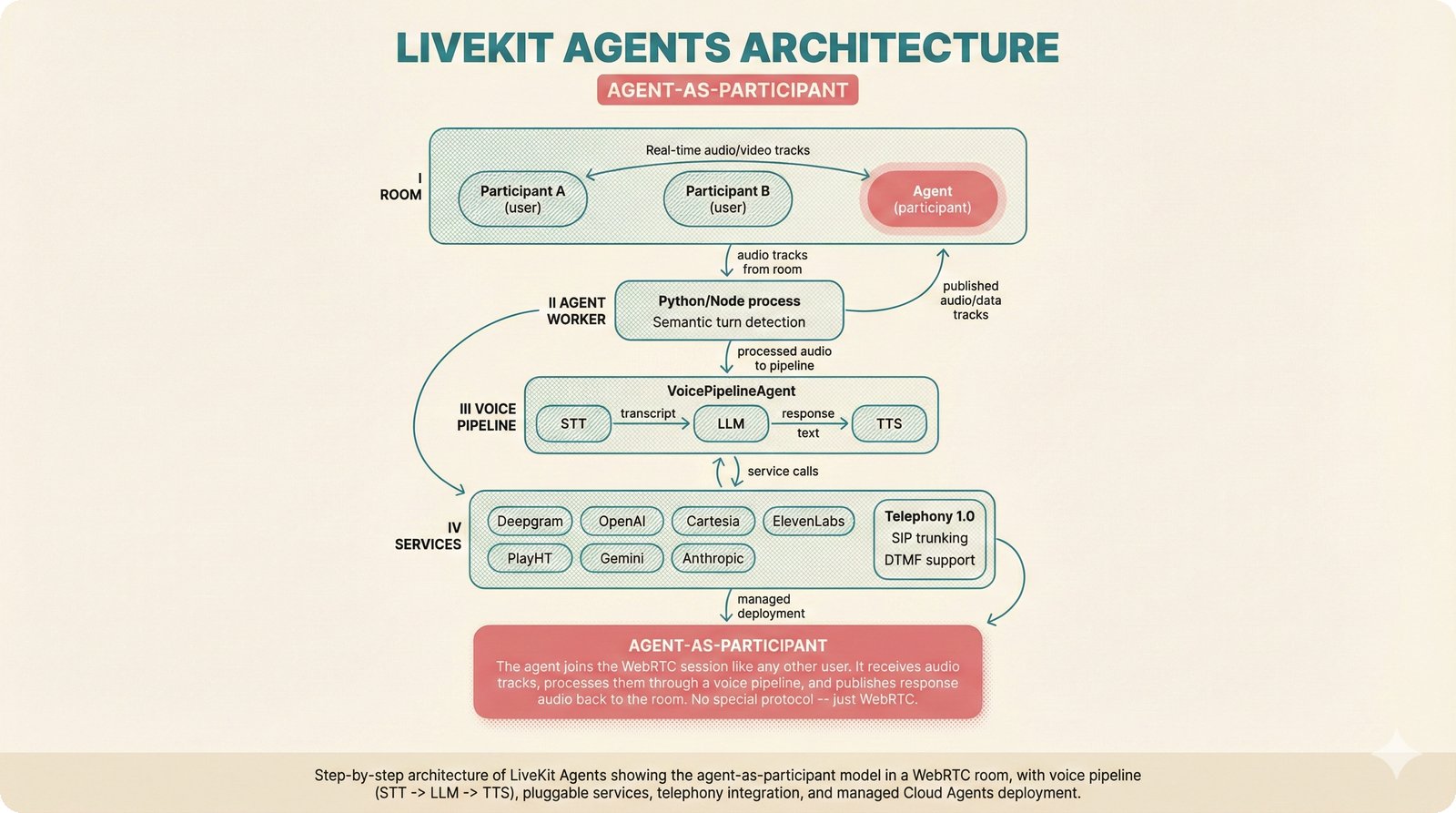 *LiveKit Agents architecture showing the agent-as-participant model in a WebRTC room with voice pipeline, pluggable services, and Cloud Agents deployment.* --- 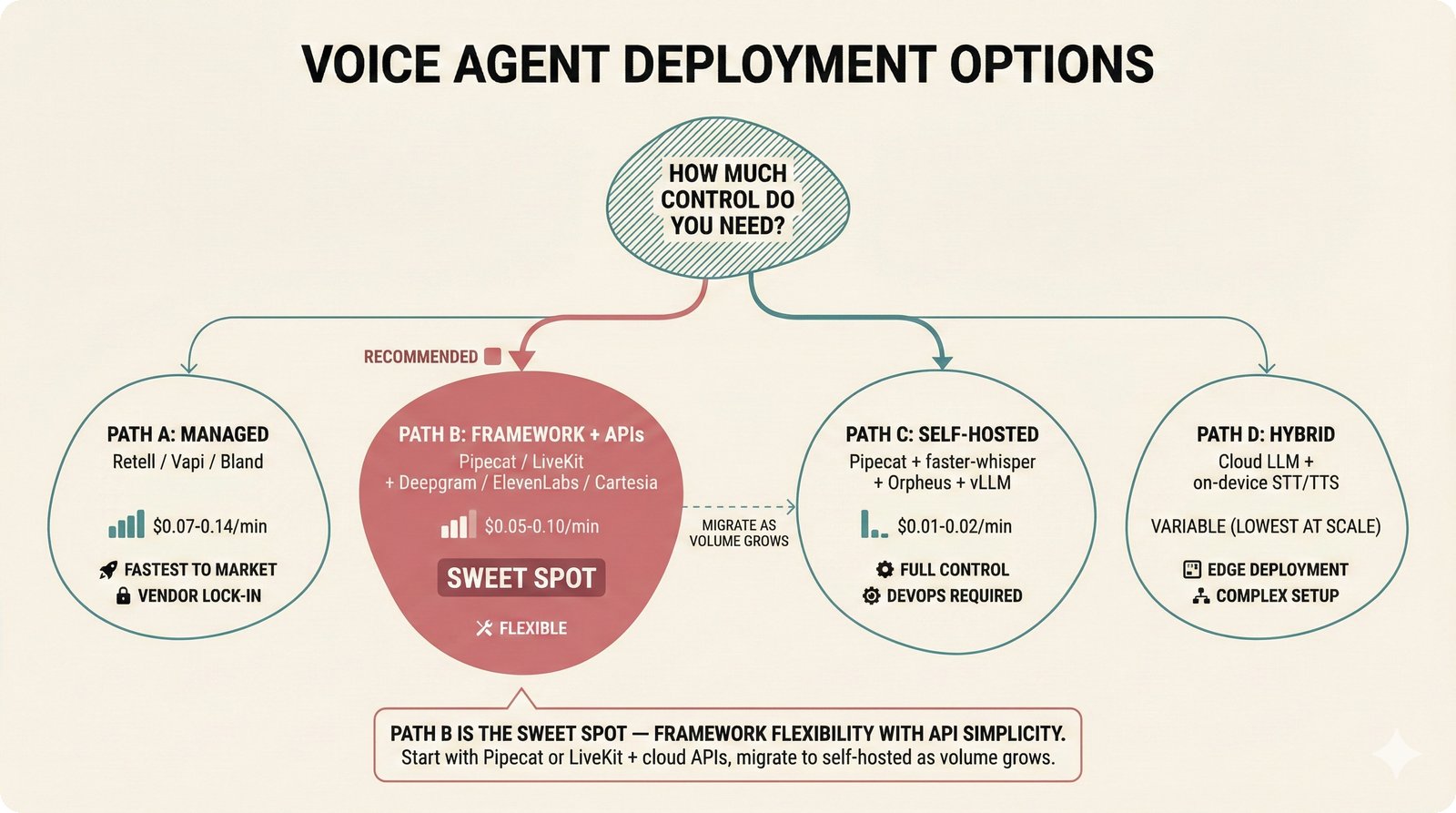 *Decision tree for voice agent deployment showing four paths from fully managed through framework + APIs to self-hosted and hybrid approaches.* --- 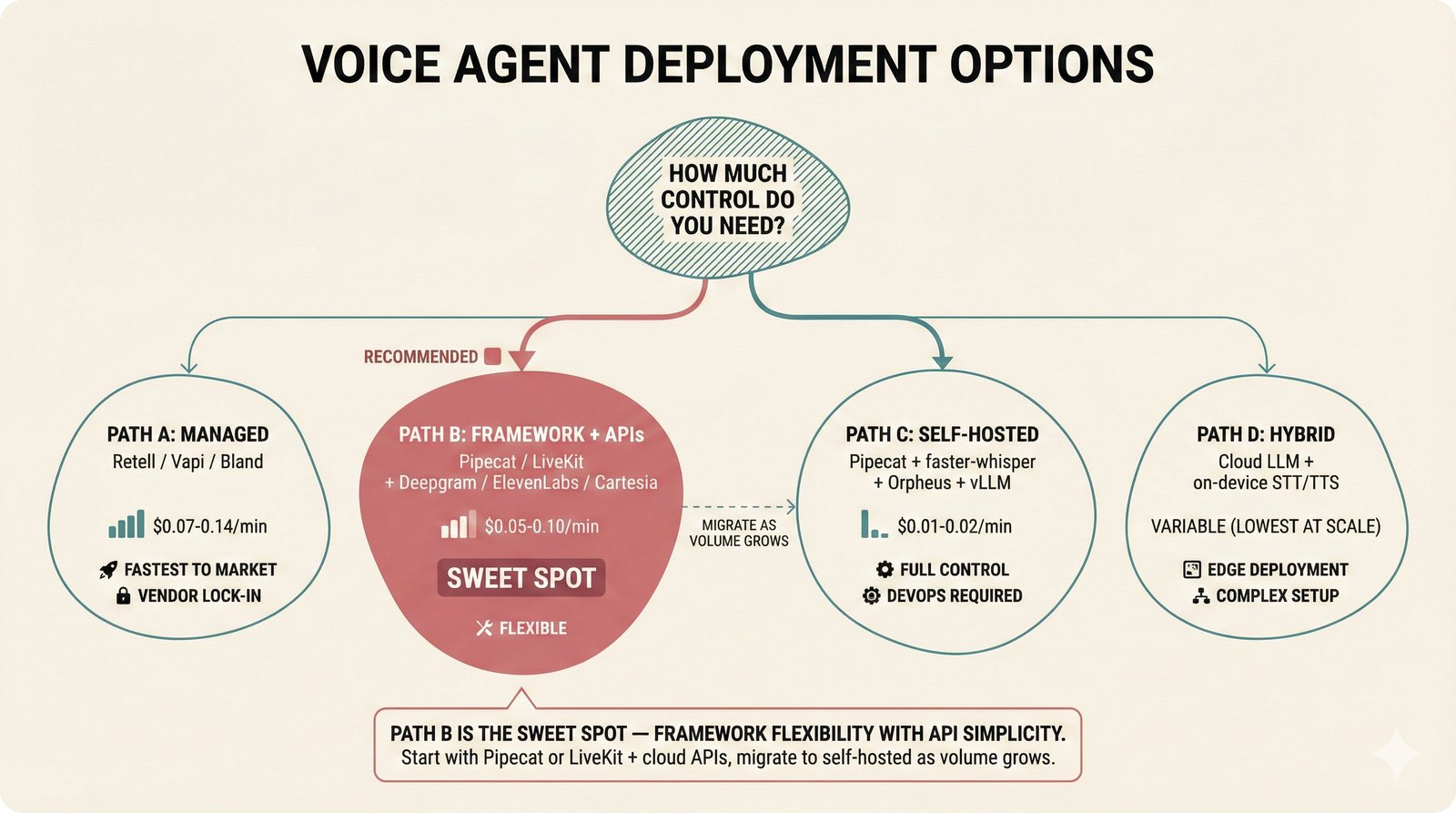 *Four-column decision matrix comparing managed platforms, framework + APIs (sweet spot), self-hosted, and hybrid deployment approaches.* --- ### Evaluation, Economics & Compliance (fig-voice-22 to 32) 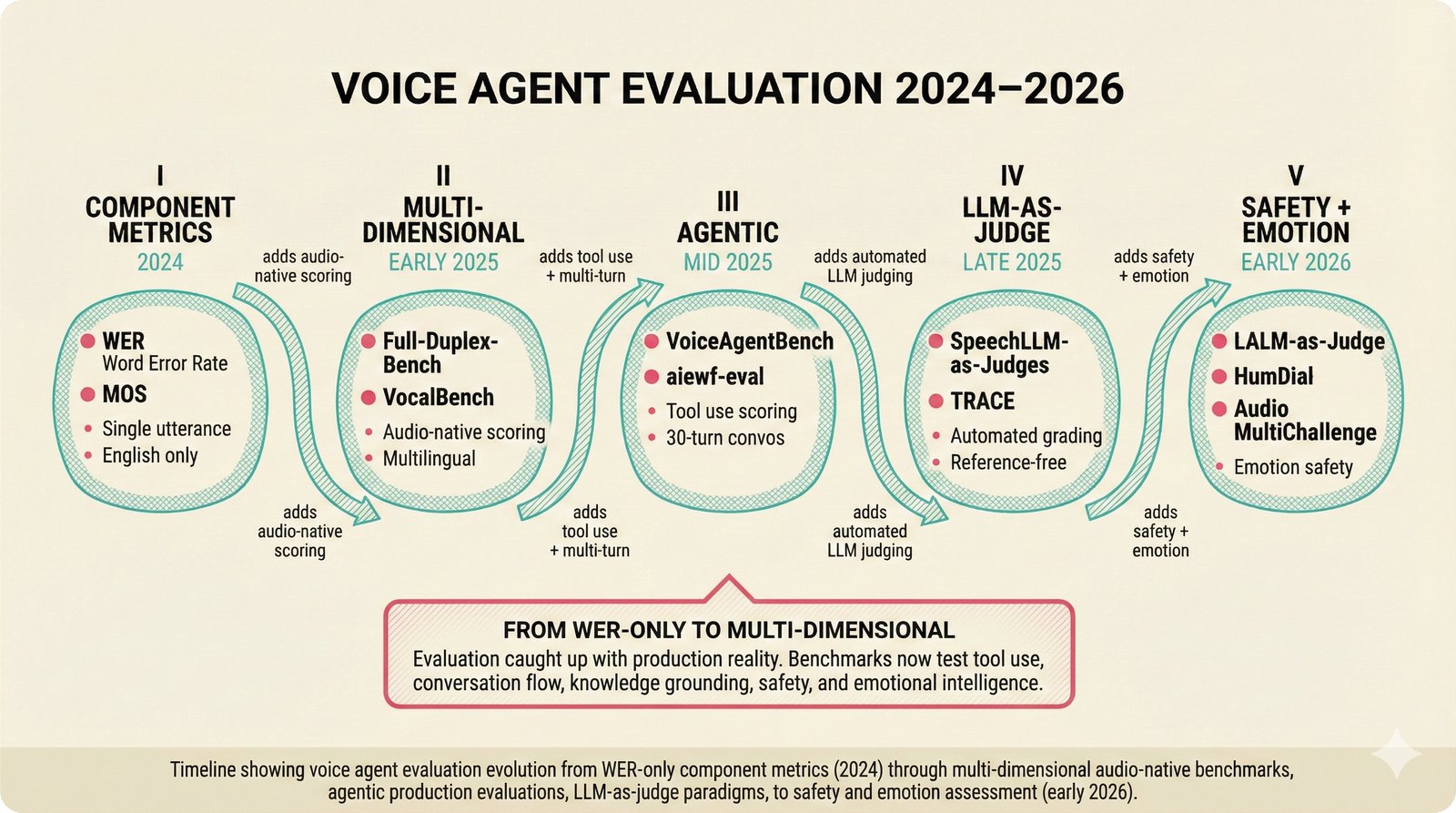 *Timeline showing voice agent evaluation evolution from WER-only component metrics (2024) through multi-dimensional benchmarks to safety and emotion assessment (early 2026).* --- 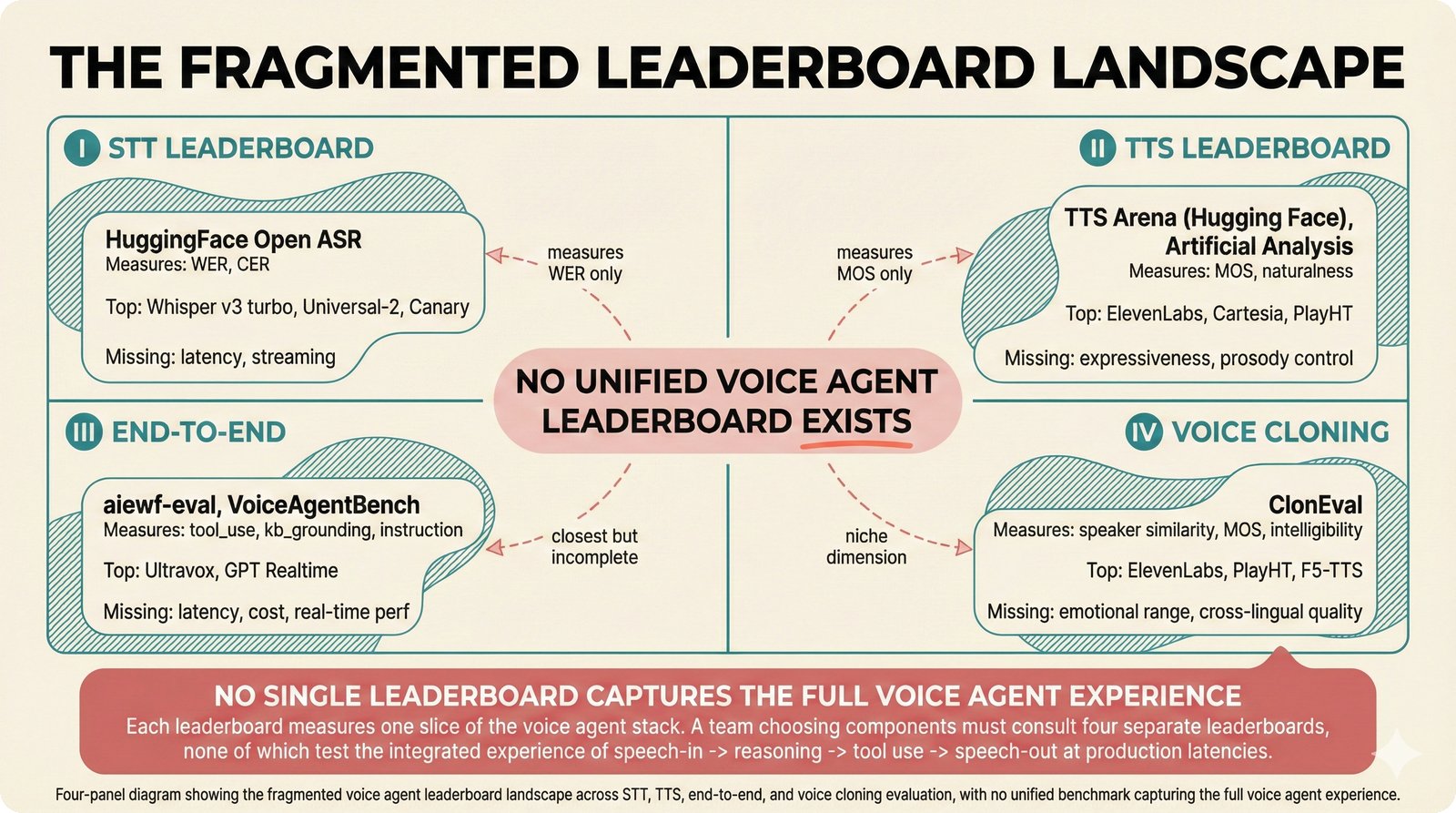 *Four-panel diagram showing the fragmented voice agent leaderboard landscape with no unified benchmark capturing the full voice agent experience.* --- 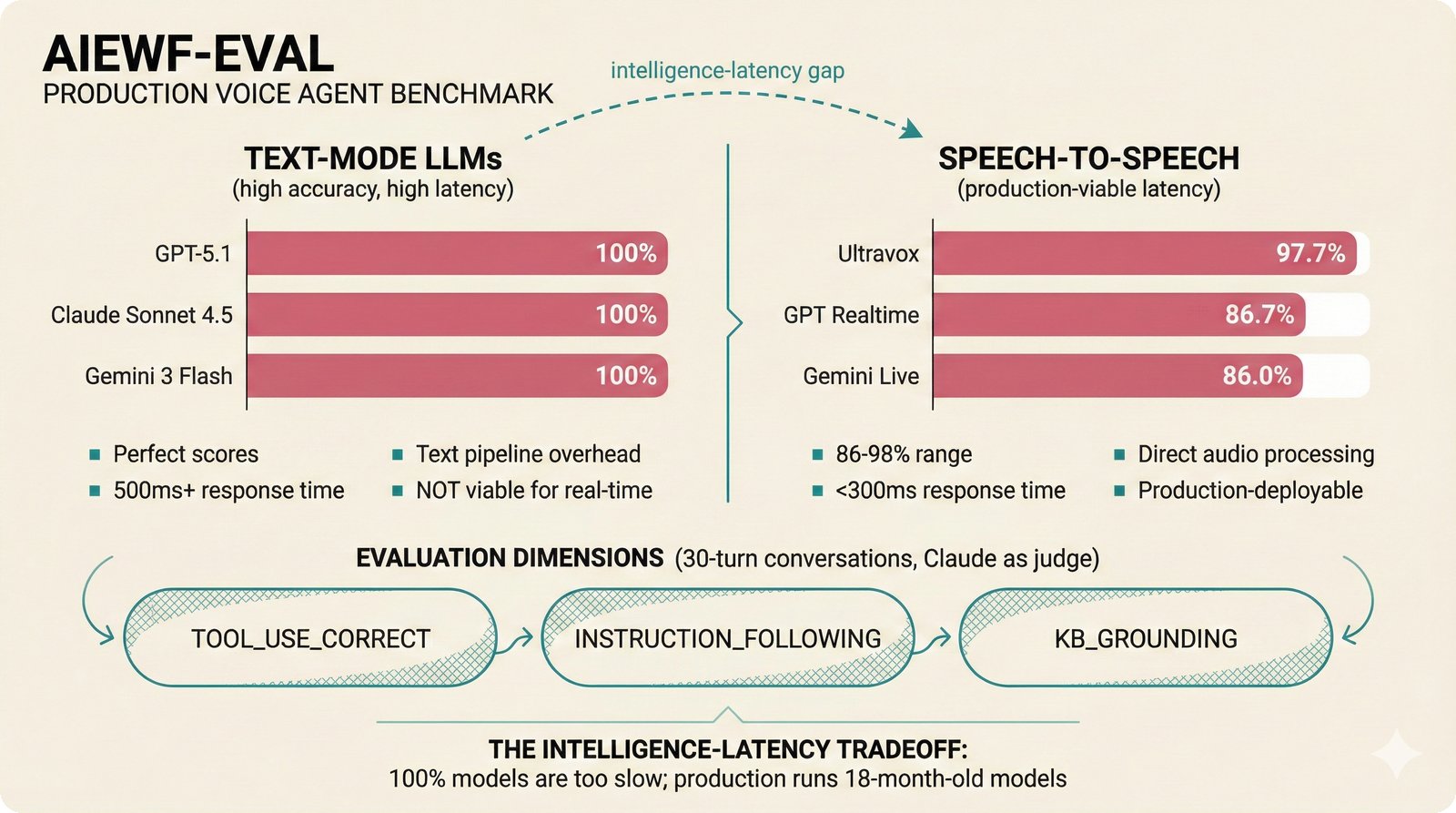 *Two-panel comparison of aiewf-eval benchmark results showing text-mode LLMs versus speech-to-speech models evaluated on tool use, instruction following, and knowledge grounding.* --- 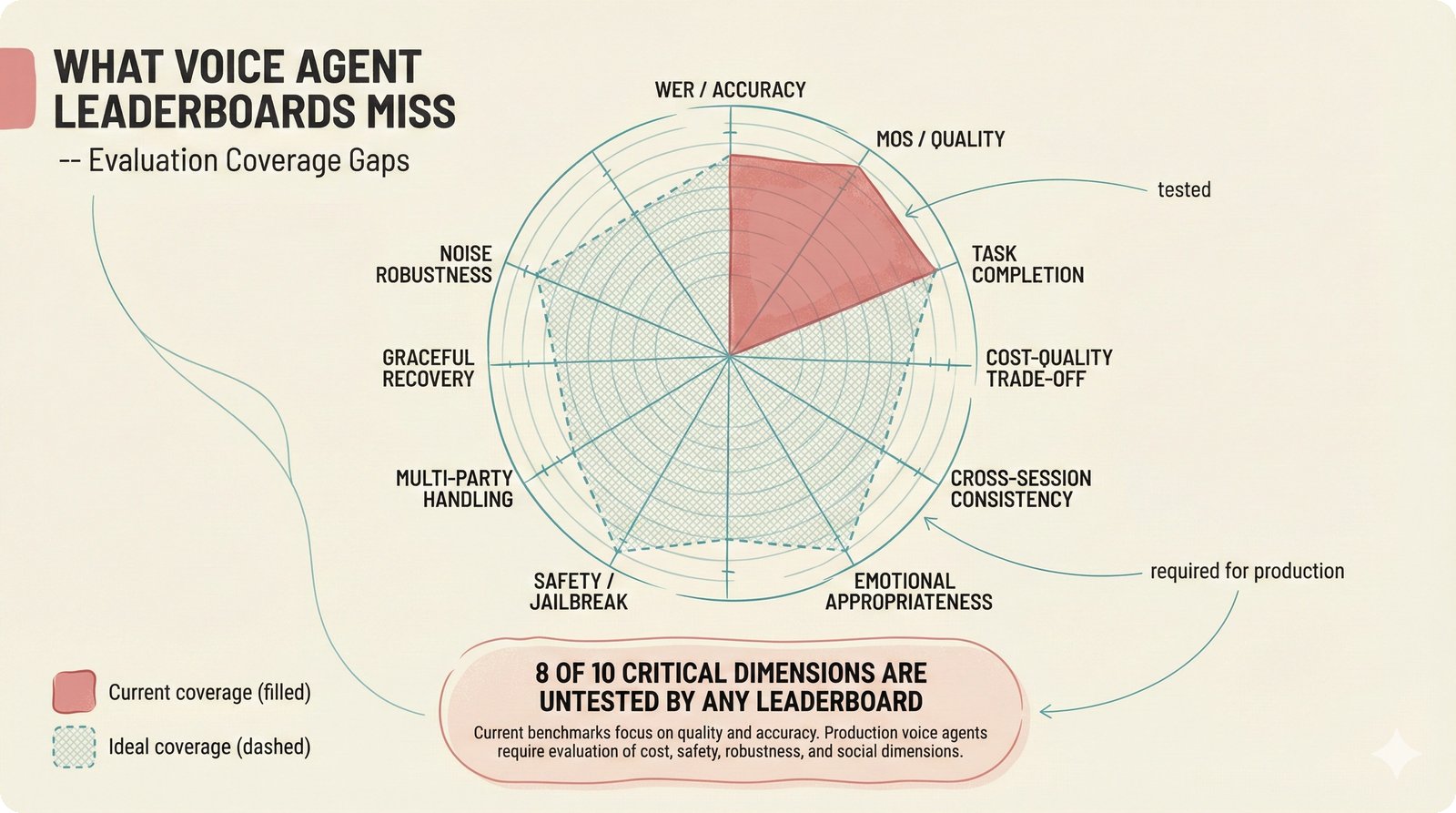 *Radar chart showing 10 critical evaluation dimensions for voice agents, revealing that current leaderboards cover only 3 while 8 remain untested.* --- 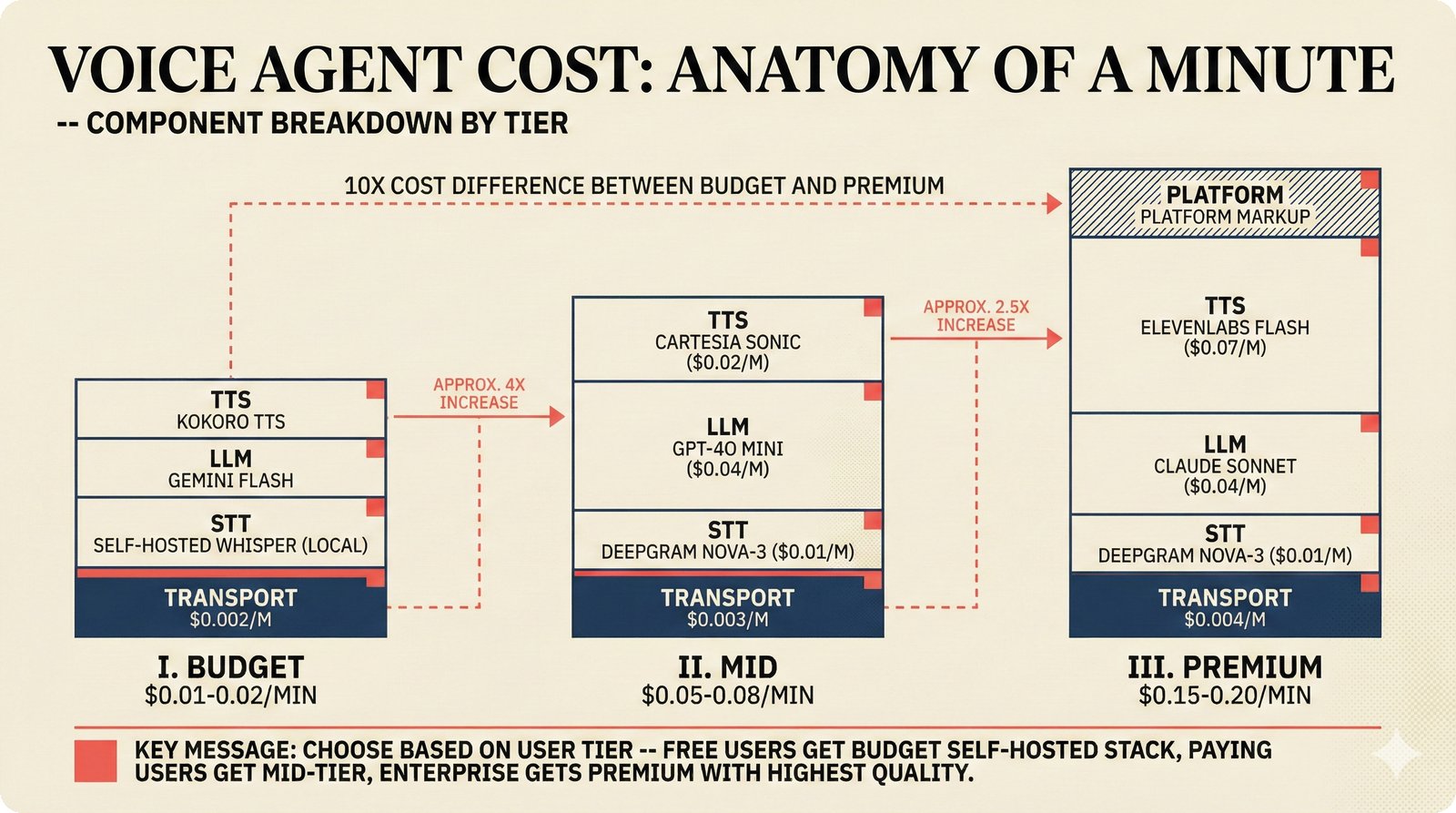 *Stacked cost breakdown across three tiers showing a 10x cost difference driven primarily by LLM and TTS choices.* --- 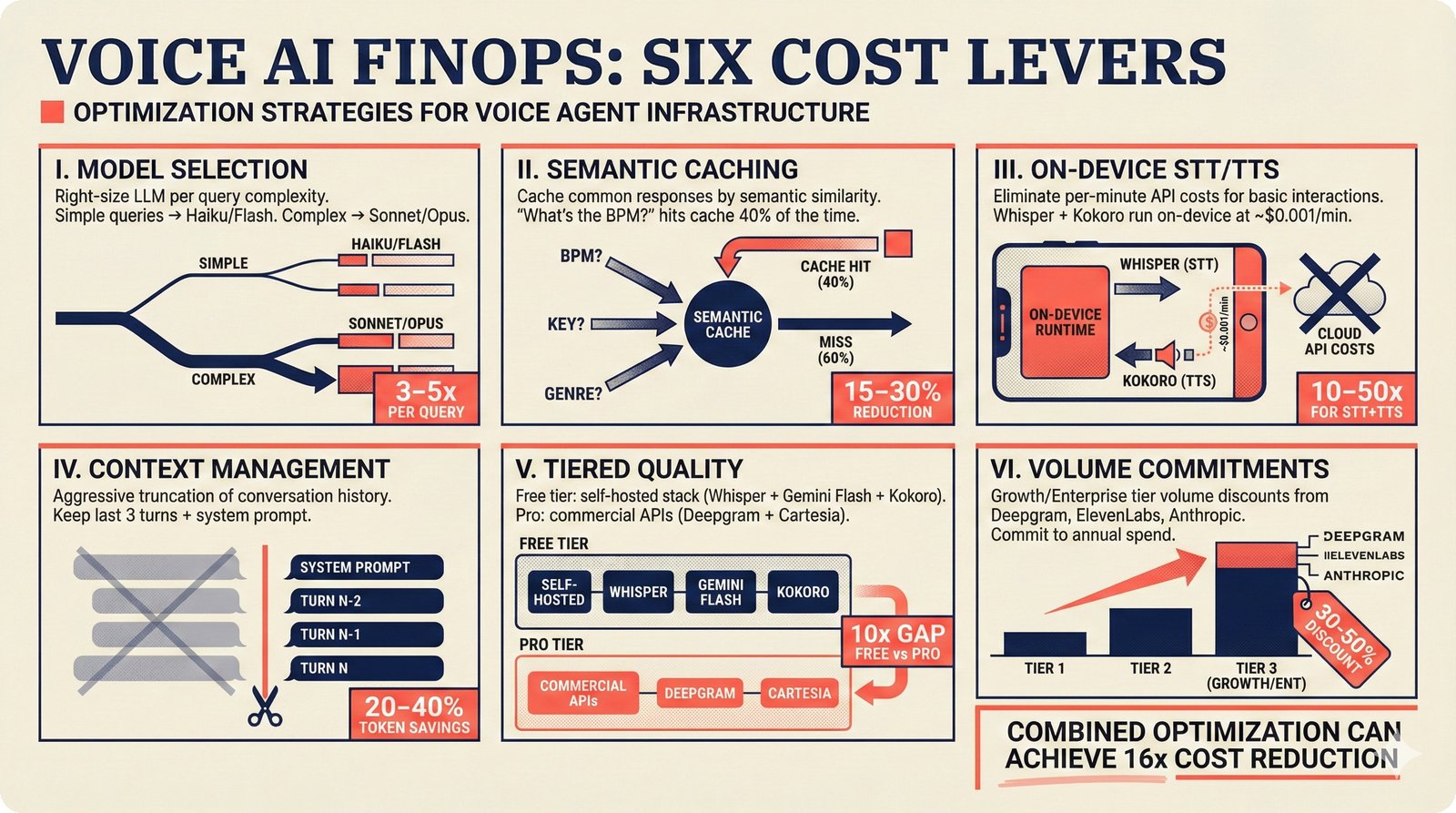 *Six cost optimization levers for voice AI infrastructure, each independently quantified and combinable for up to 16x total cost reduction.* --- 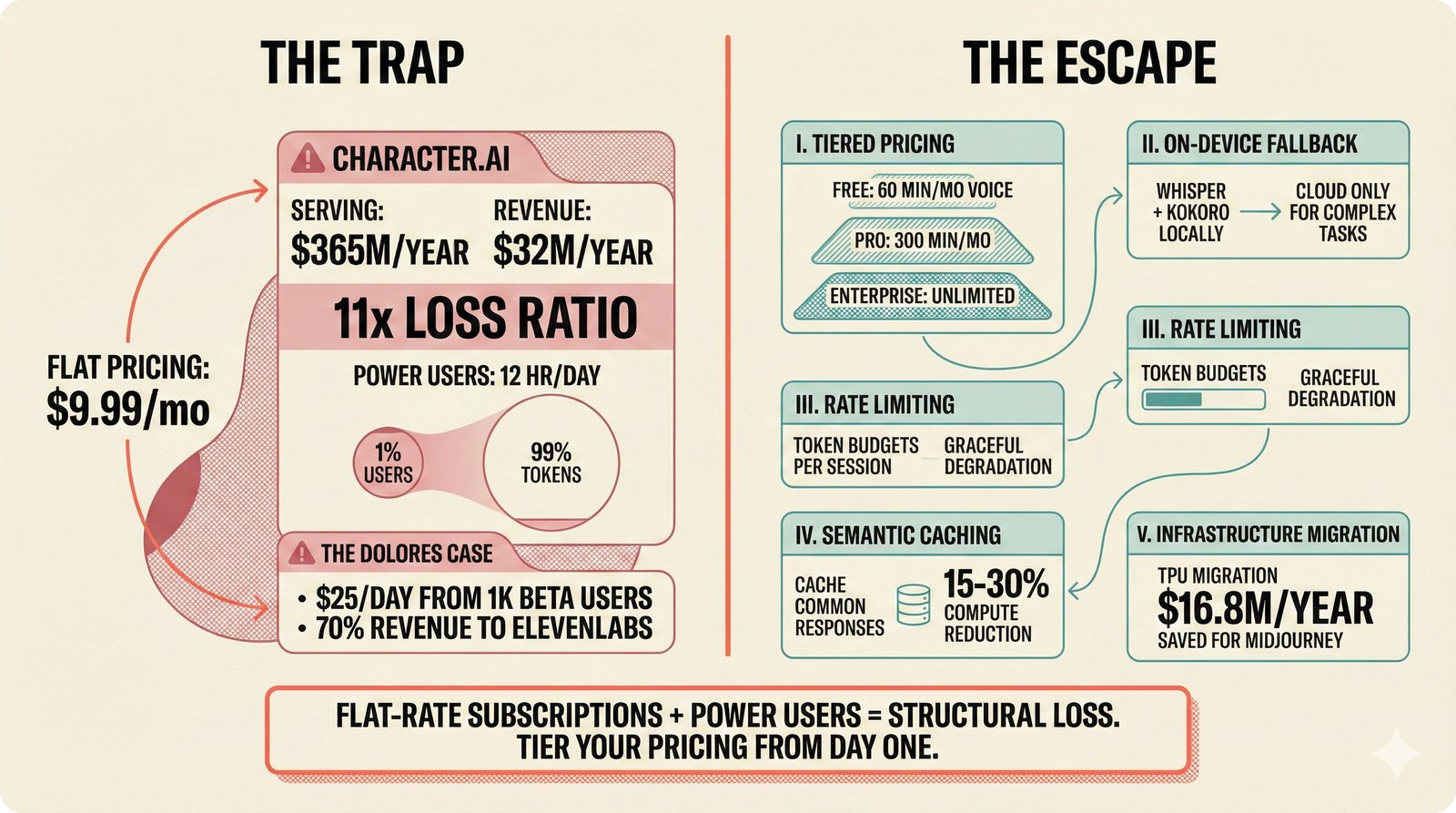 *Split-panel showing the AI companion cost trap and five escape strategies for sustainable voice agent economics.* ---  *Mapping of PRAC3 voice rights framework to music attribution implementations, showing how each dimension translates to technical mechanisms and A0-A3 assurance levels.* --- 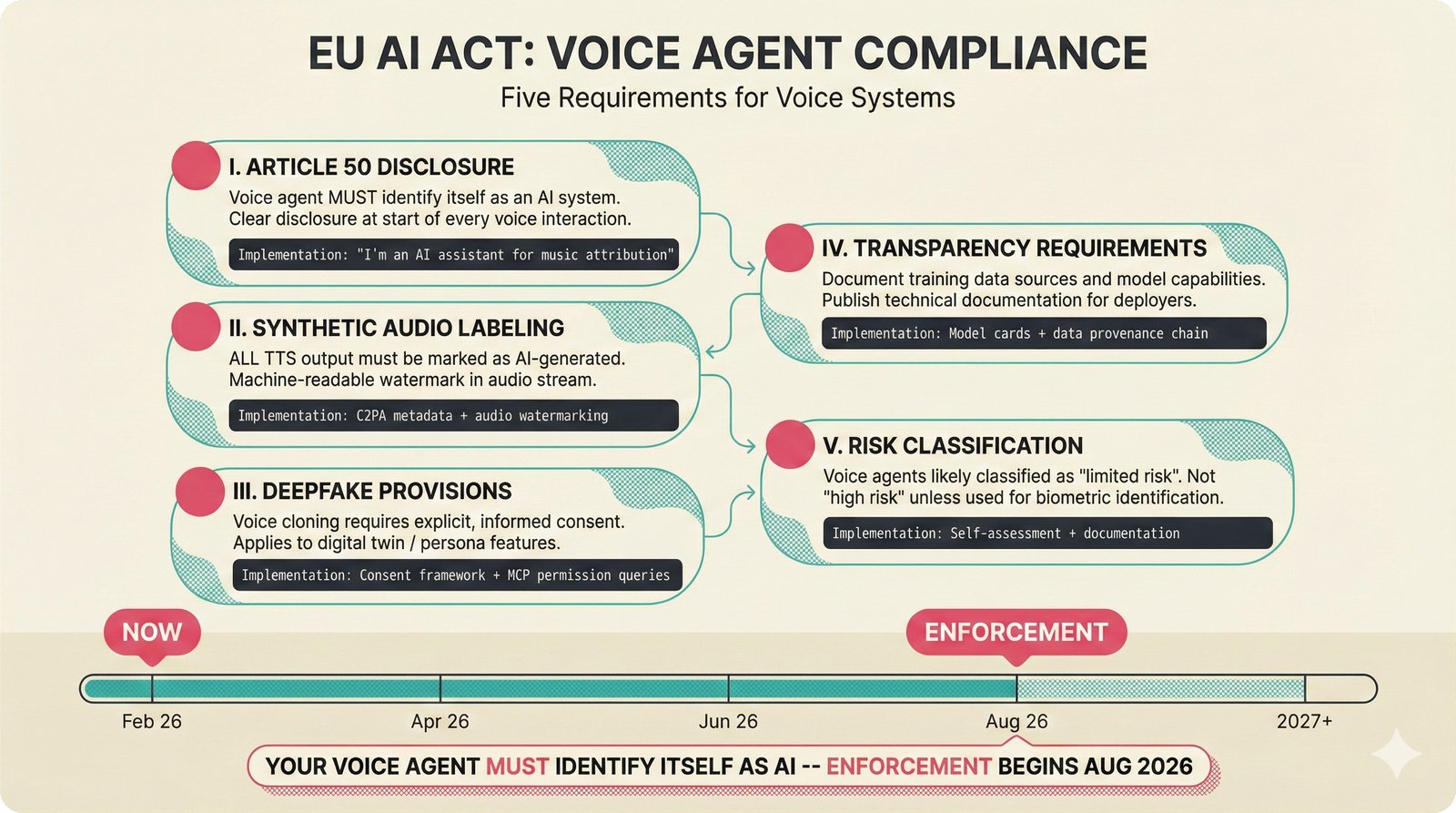 *Five EU AI Act compliance requirements for voice agent systems with enforcement timeline through August 2026.* --- 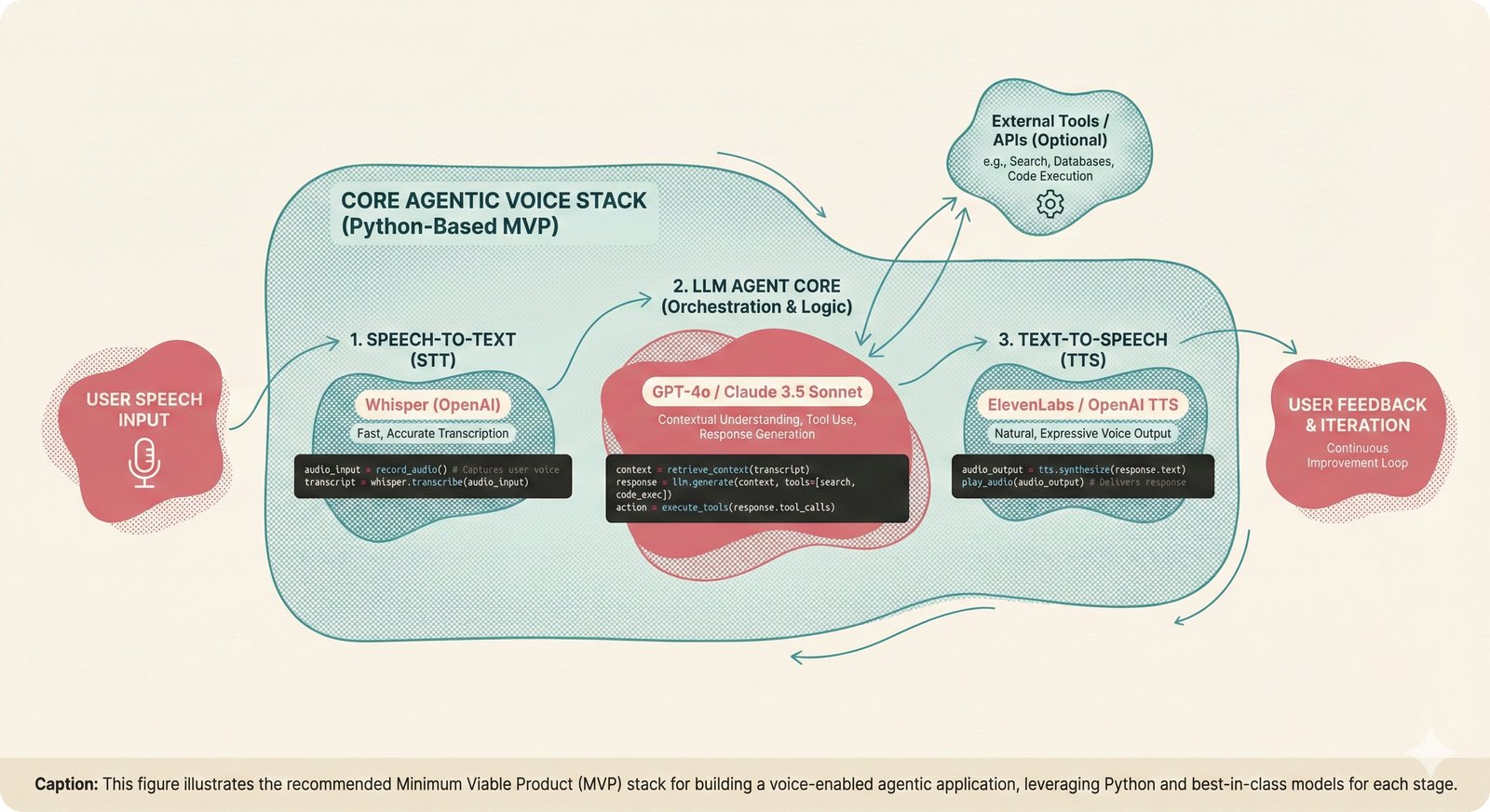 *Recommended six-layer voice agent MVP stack for music attribution at $0.05-0.08/min operating cost.* --- 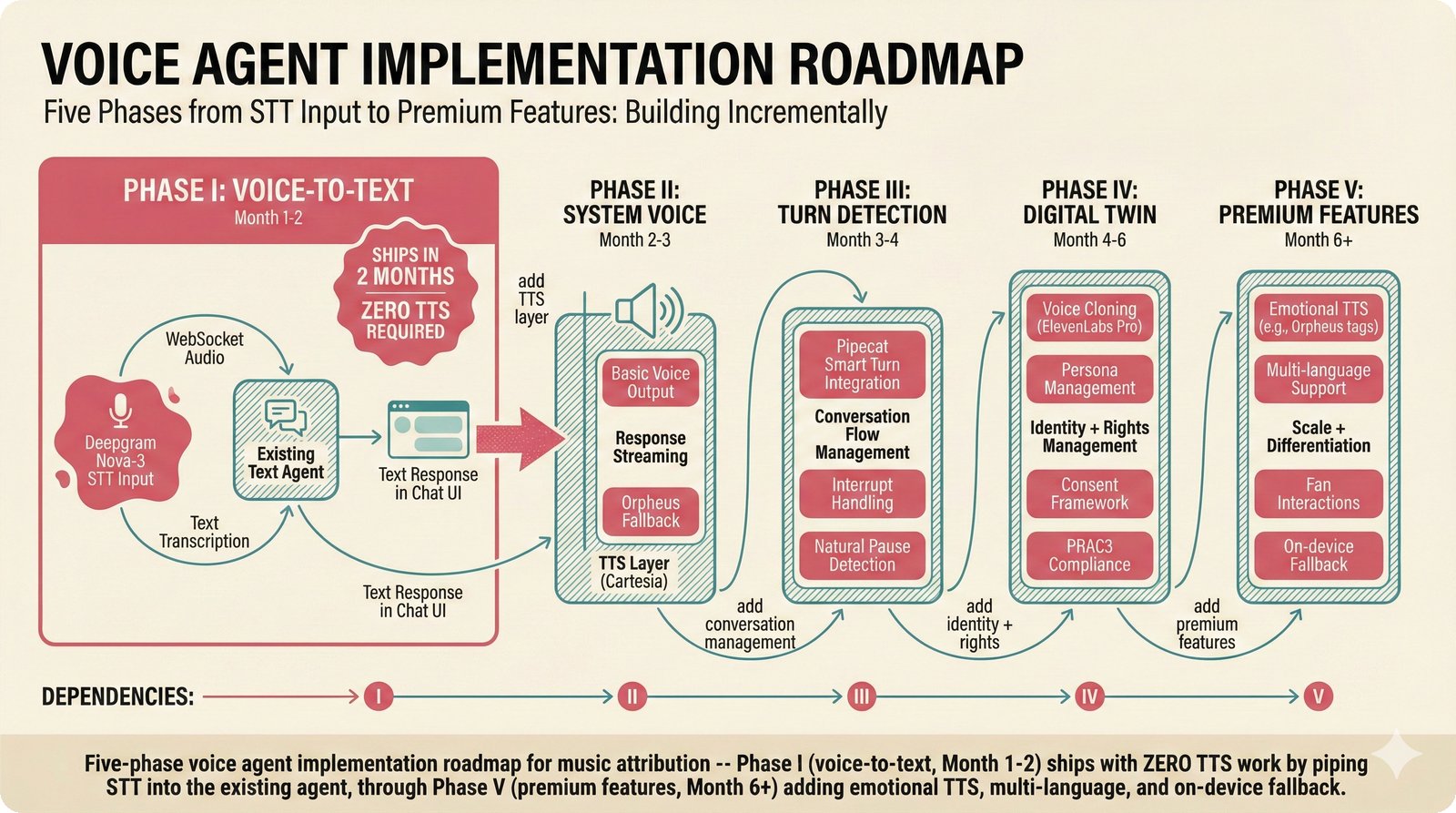 *Five-phase voice agent implementation roadmap from Phase I voice-to-text (Month 1-2) through Phase V premium features (Month 6+).* --- ### Implementation Architecture (fig-voice-33 to 48) 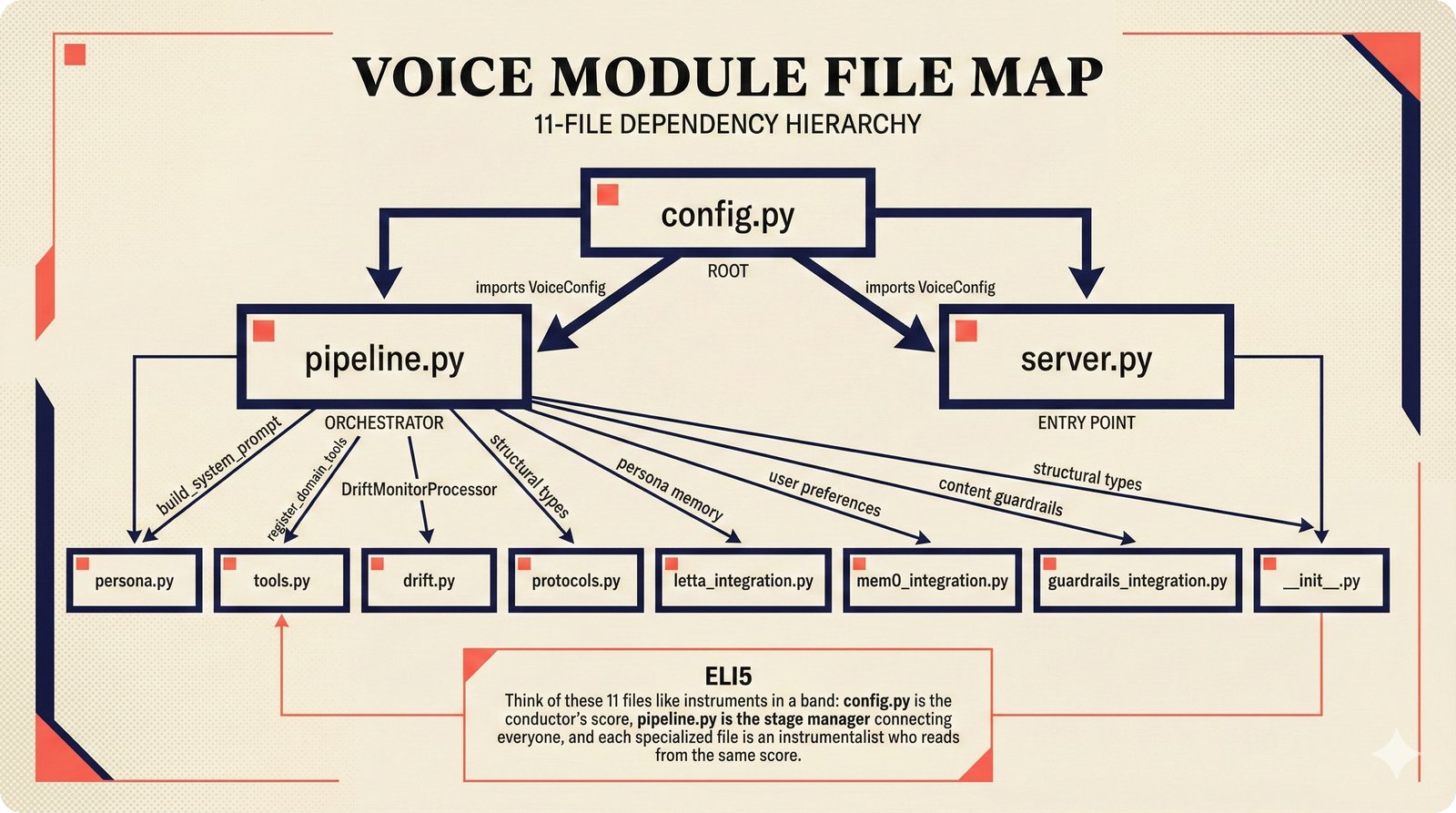 *Dependency graph of the voice module's 11 files with config.py as root, pipeline.py as orchestrator, and specialized leaf files for persona, drift detection, tools, and external integrations.* --- 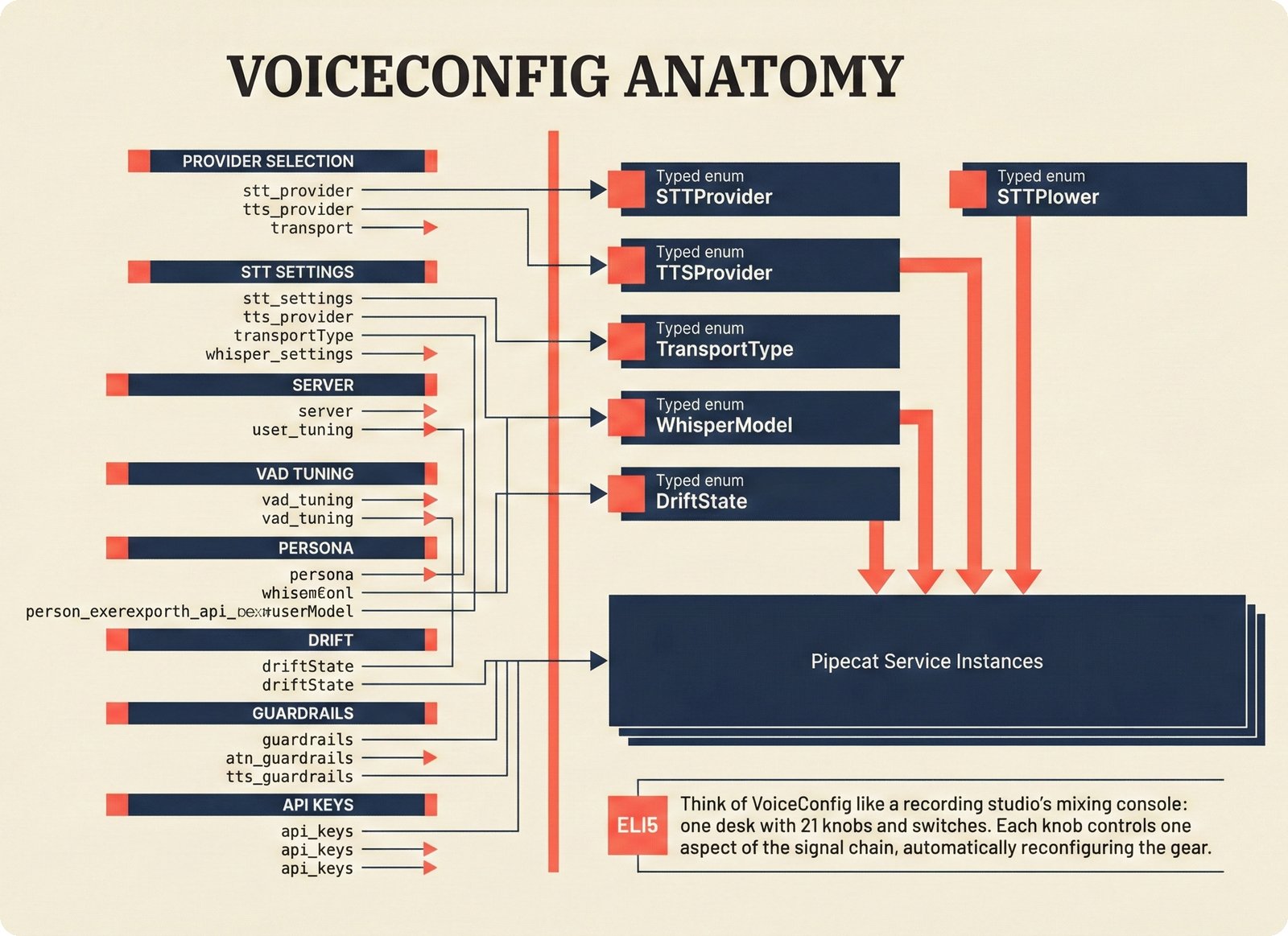 *VoiceConfig anatomy: 21 environment variables cascade through 6 typed enums to concrete Pipecat service instances -- one Pydantic Settings model controls the entire pipeline.* --- 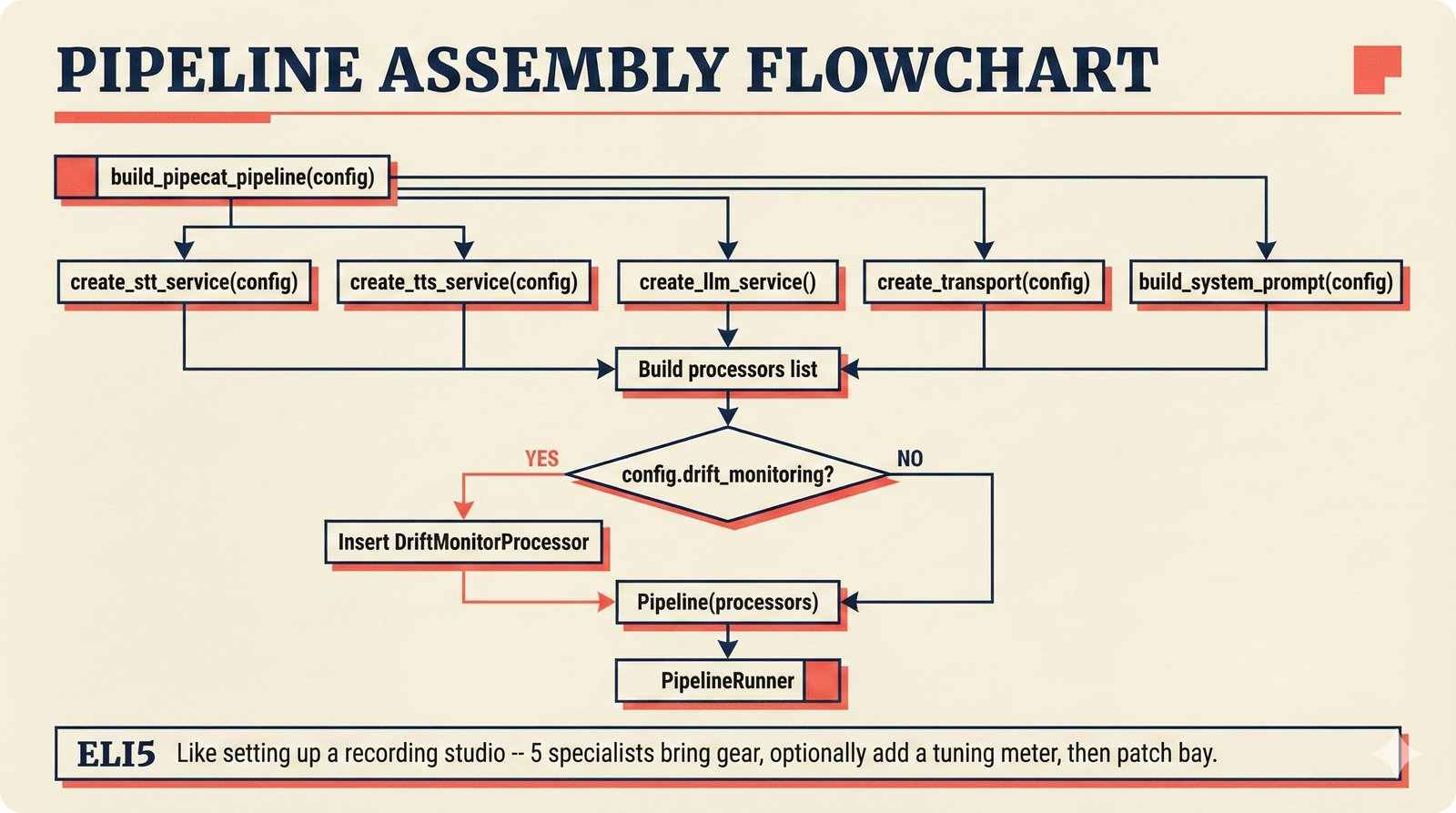 *Pipeline assembly flowchart: build_pipecat_pipeline() calls five factory functions, conditionally inserts a DriftMonitorProcessor, and wires everything into a PipelineRunner.* --- 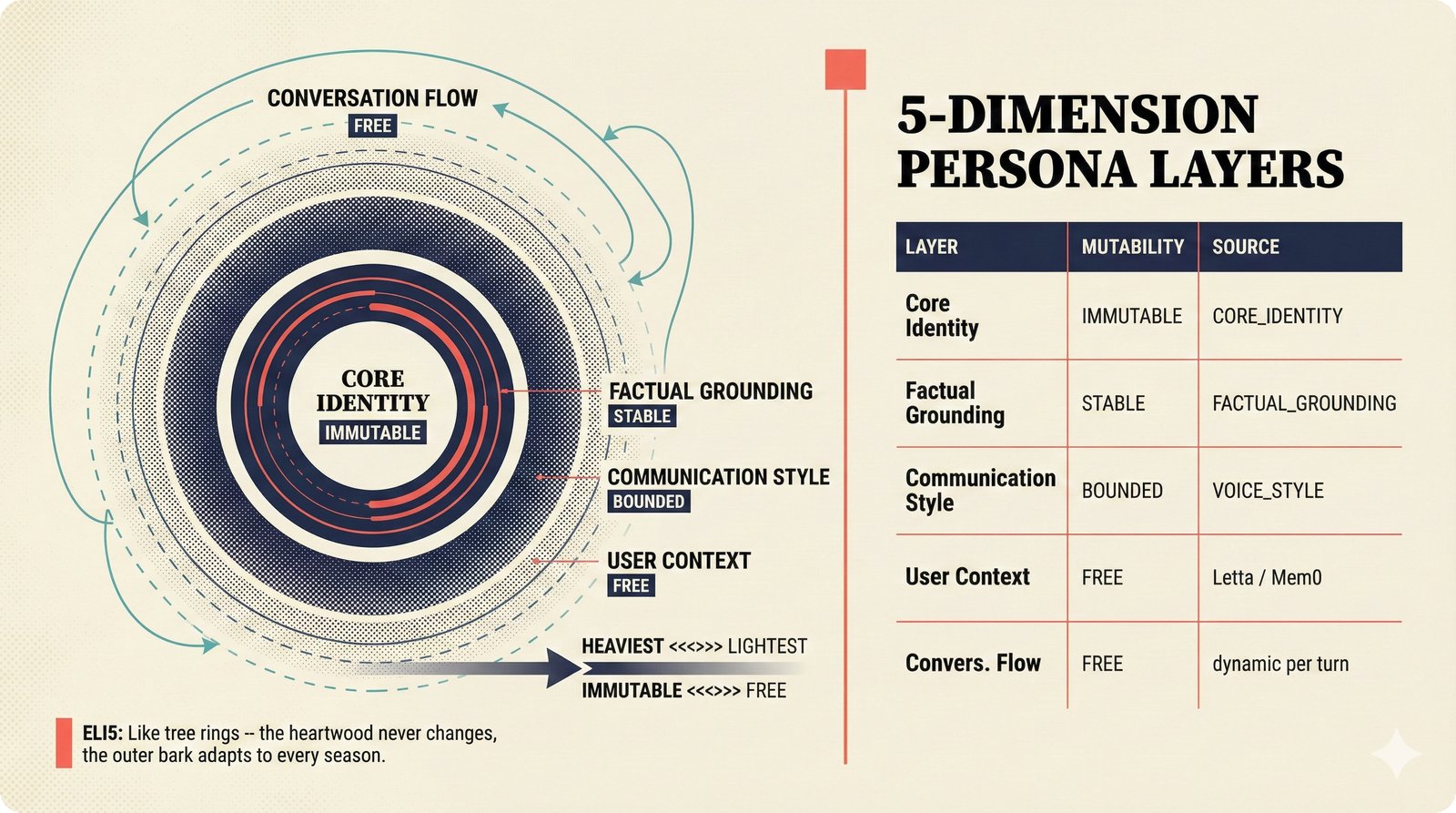 *Five concentric persona dimensions with mutability gradient: Core Identity (IMMUTABLE) at center through Conversation Flow (FREE) at edge -- the most critical layers change the least.* --- 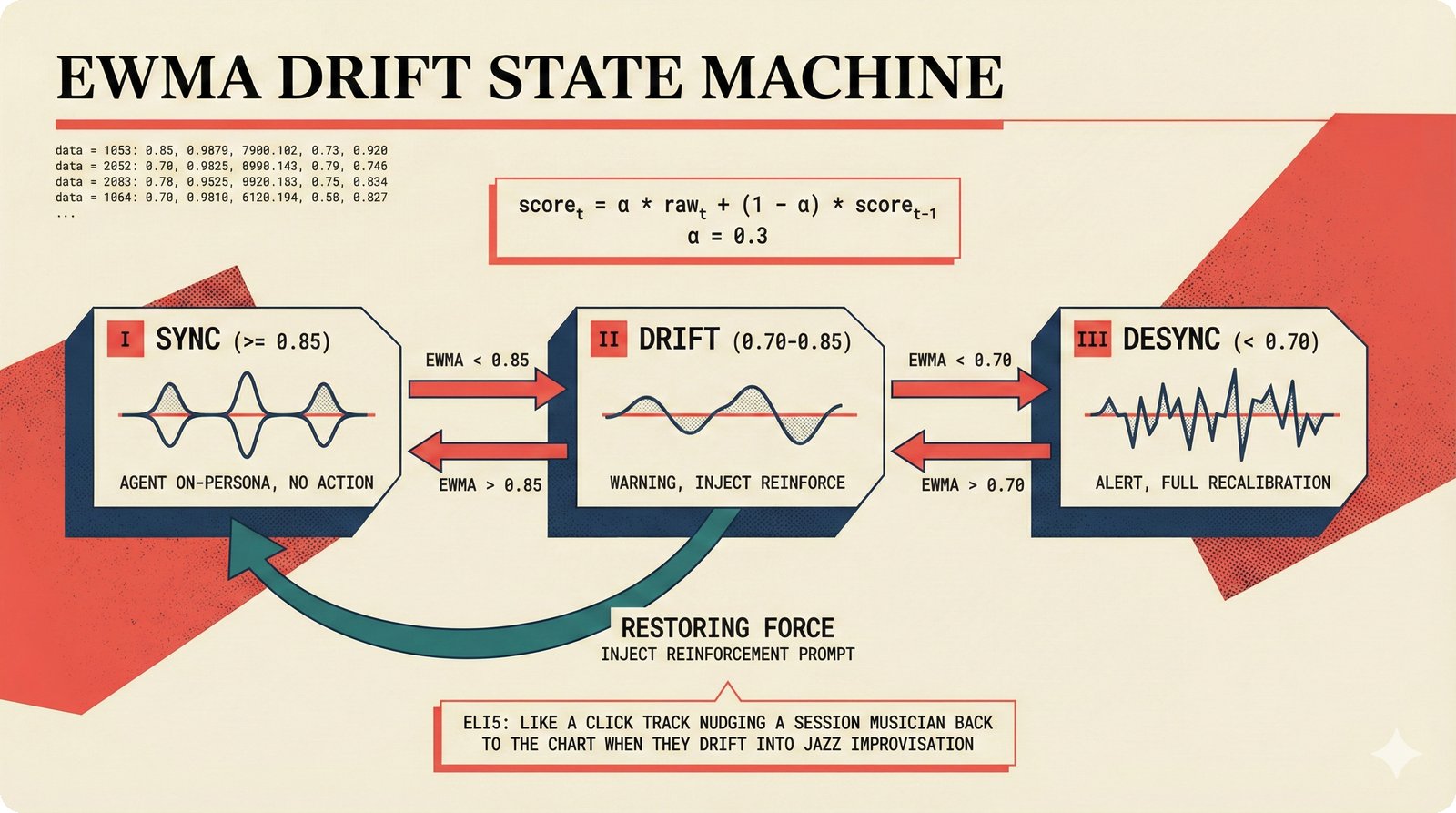 *Drift detection state machine: three states (sync ≥0.85, drift 0.70-0.85, desync <0.70) with EWMA smoothing and periodic reinforcement as the restoring force back to sync.* --- 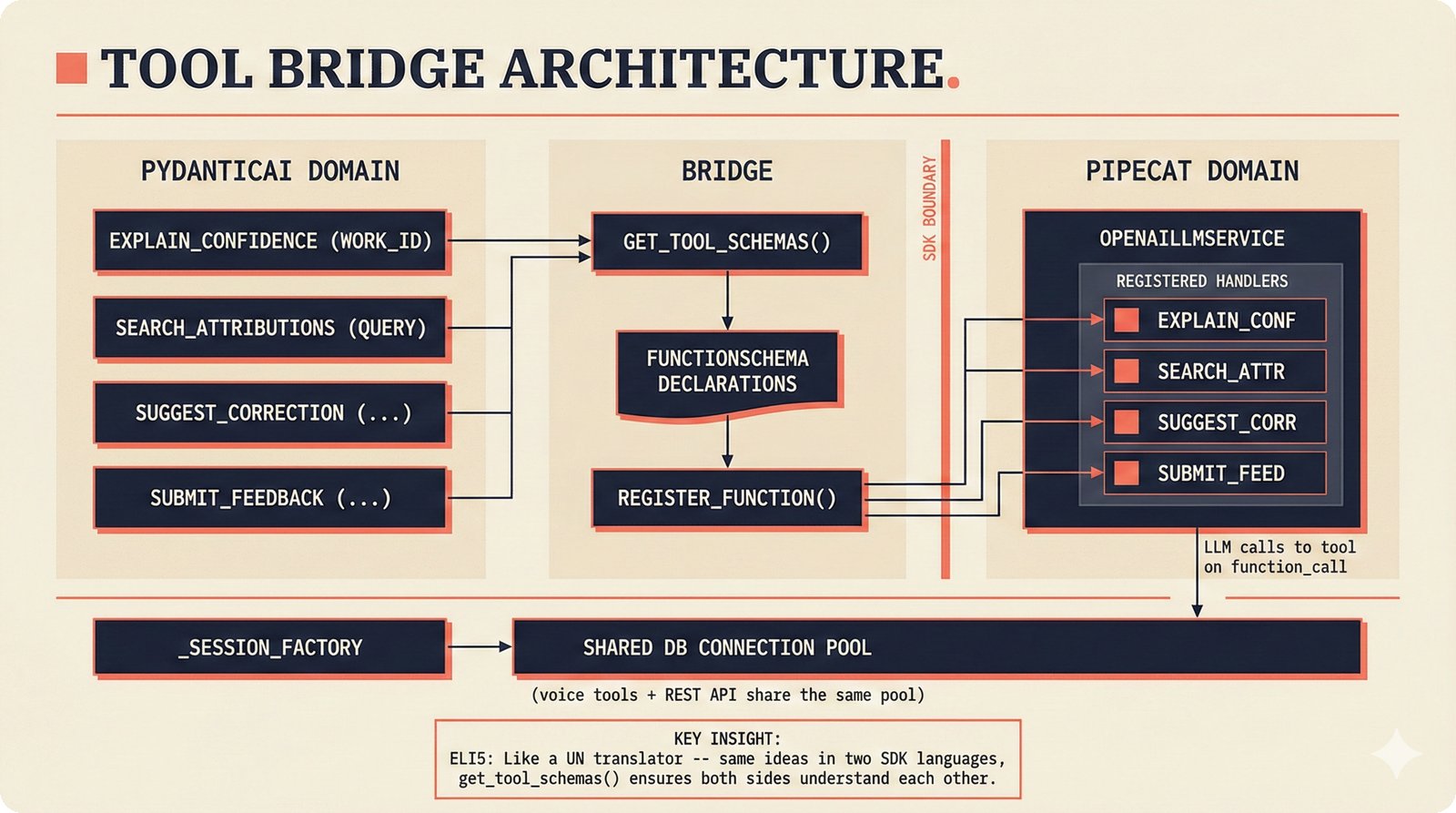 *Tool bridge architecture: PydanticAI's 4 domain tools are translated to Pipecat FunctionSchema declarations via get_tool_schemas(), sharing the same database session factory as the REST API.* --- 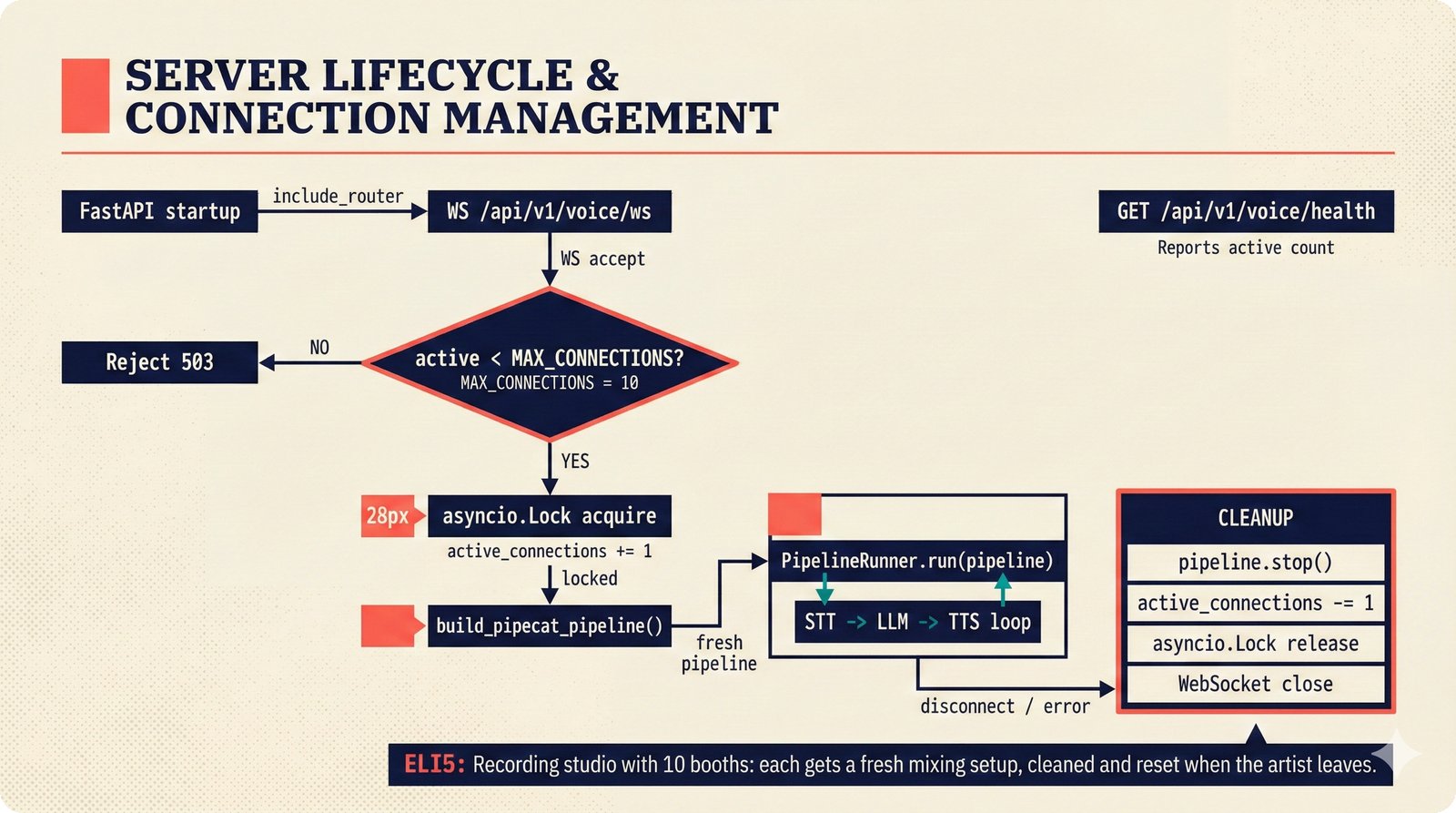 *Server lifecycle: WebSocket accept → connection limit check (MAX=10) → asyncio.Lock → build_pipecat_pipeline() → PipelineRunner → cleanup on disconnect.* --- 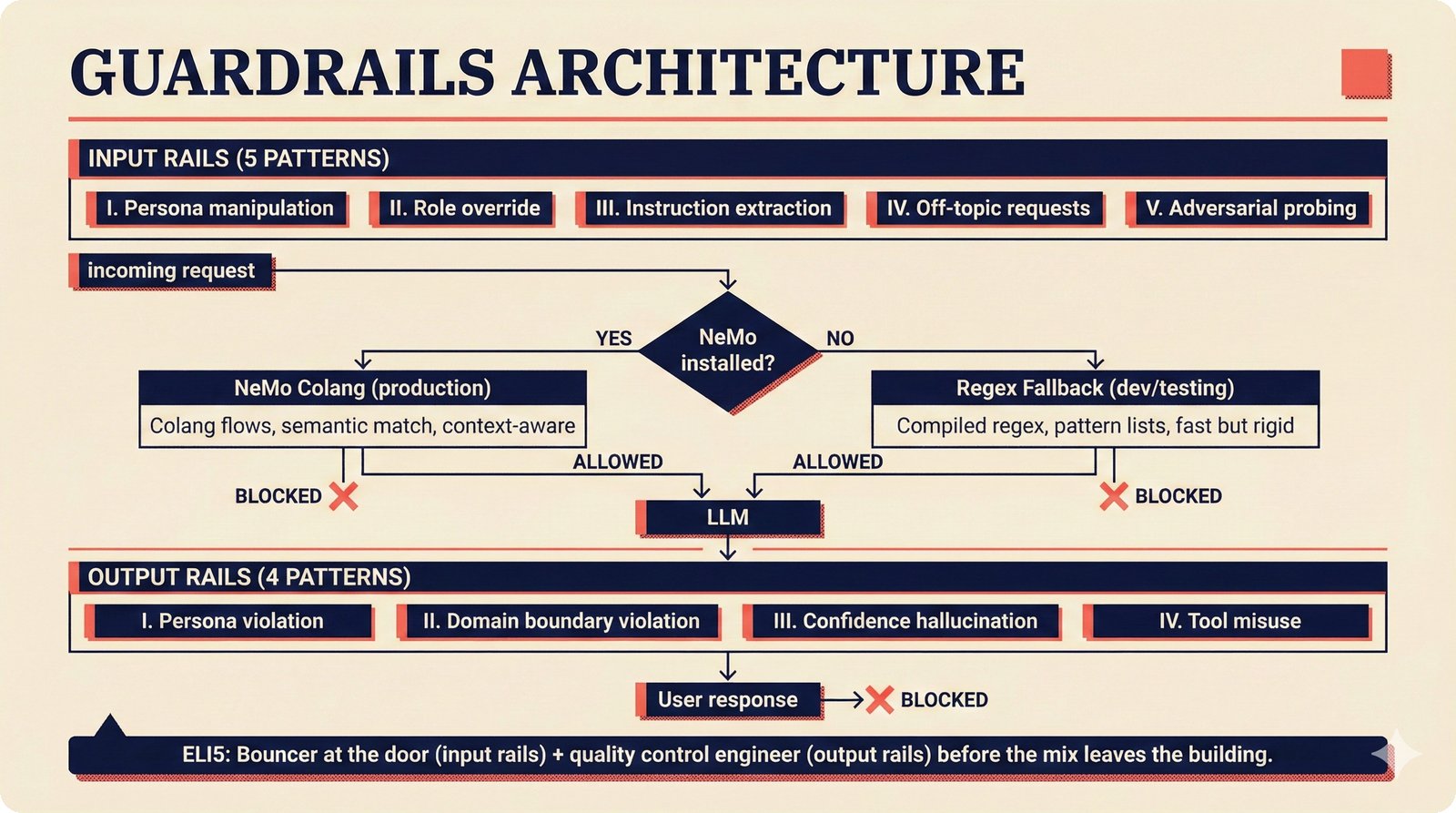 *Guardrails architecture: input rails (5 patterns) and output rails (4 patterns) with a runtime branch between NeMo Colang and regex fallback, ensuring persona boundaries in both paths.* --- 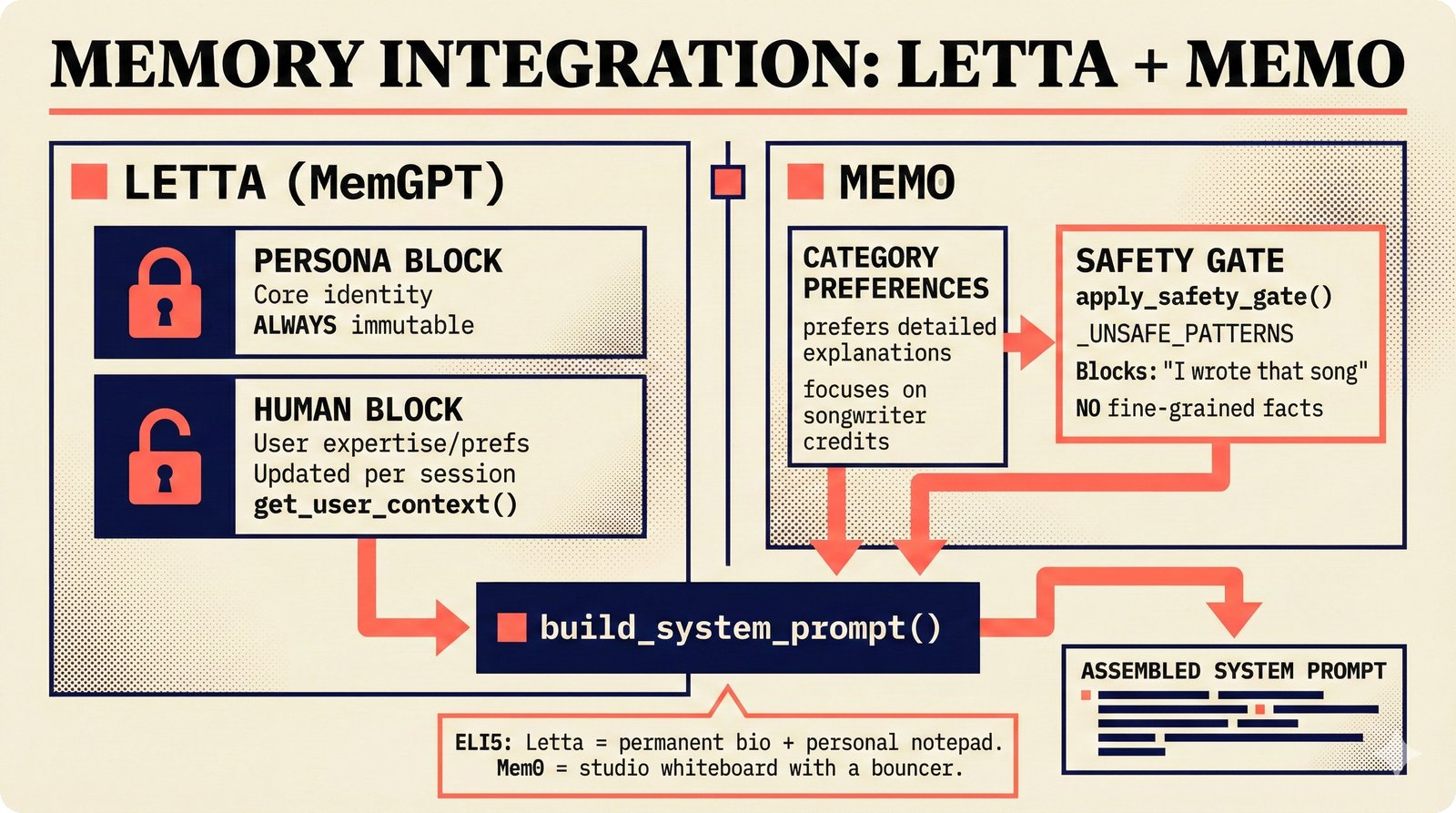 *Memory integration: Letta (immutable persona block + mutable user memory) and Mem0 (category preferences + safety gate) converge into build_system_prompt() to assemble the system prompt.* --- 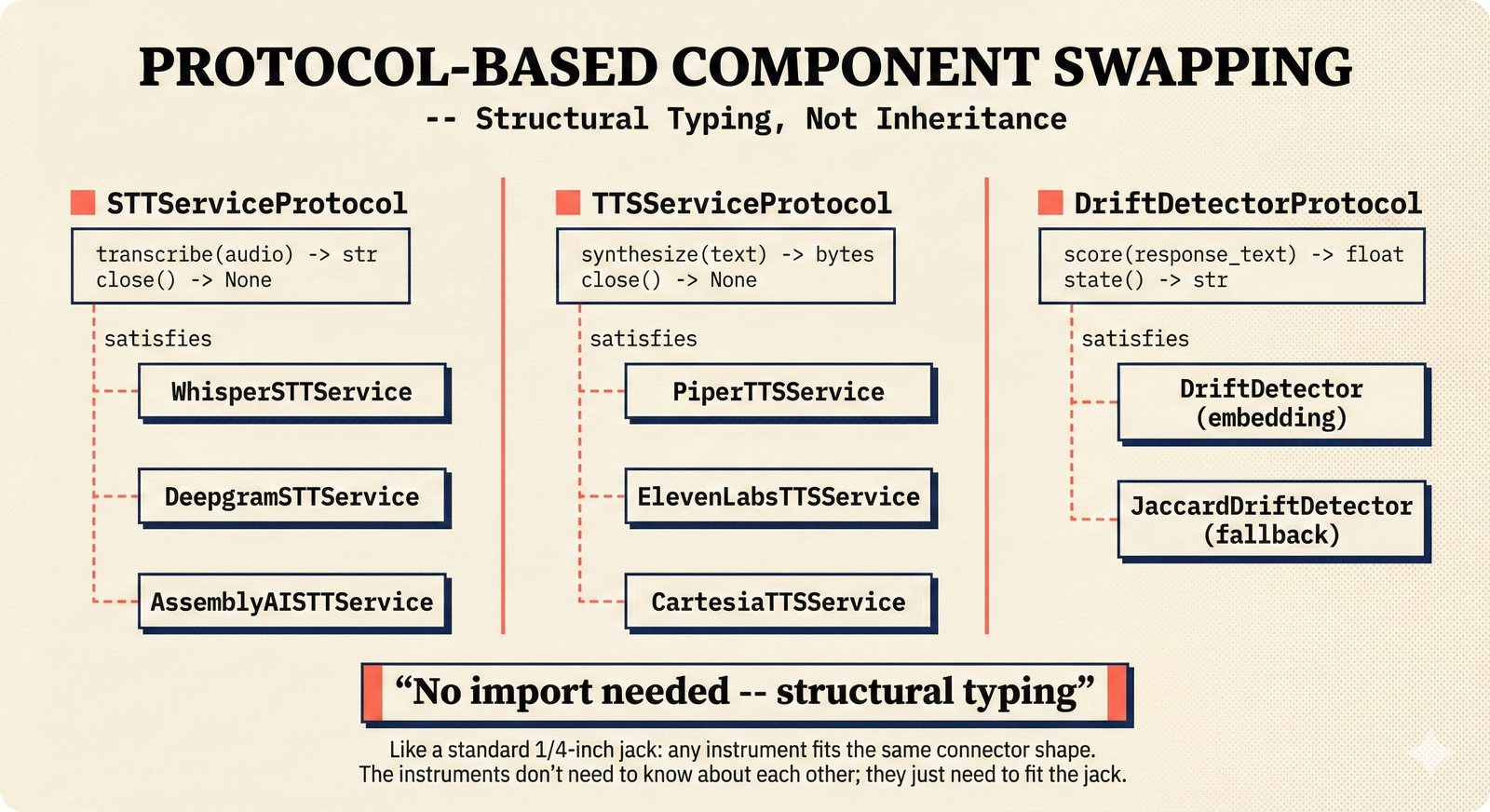 *Protocol-based swapping: three protocols (STT, TTS, Drift) with dashed "satisfies" lines to concrete implementations -- structural typing means no import or inheritance needed.* --- 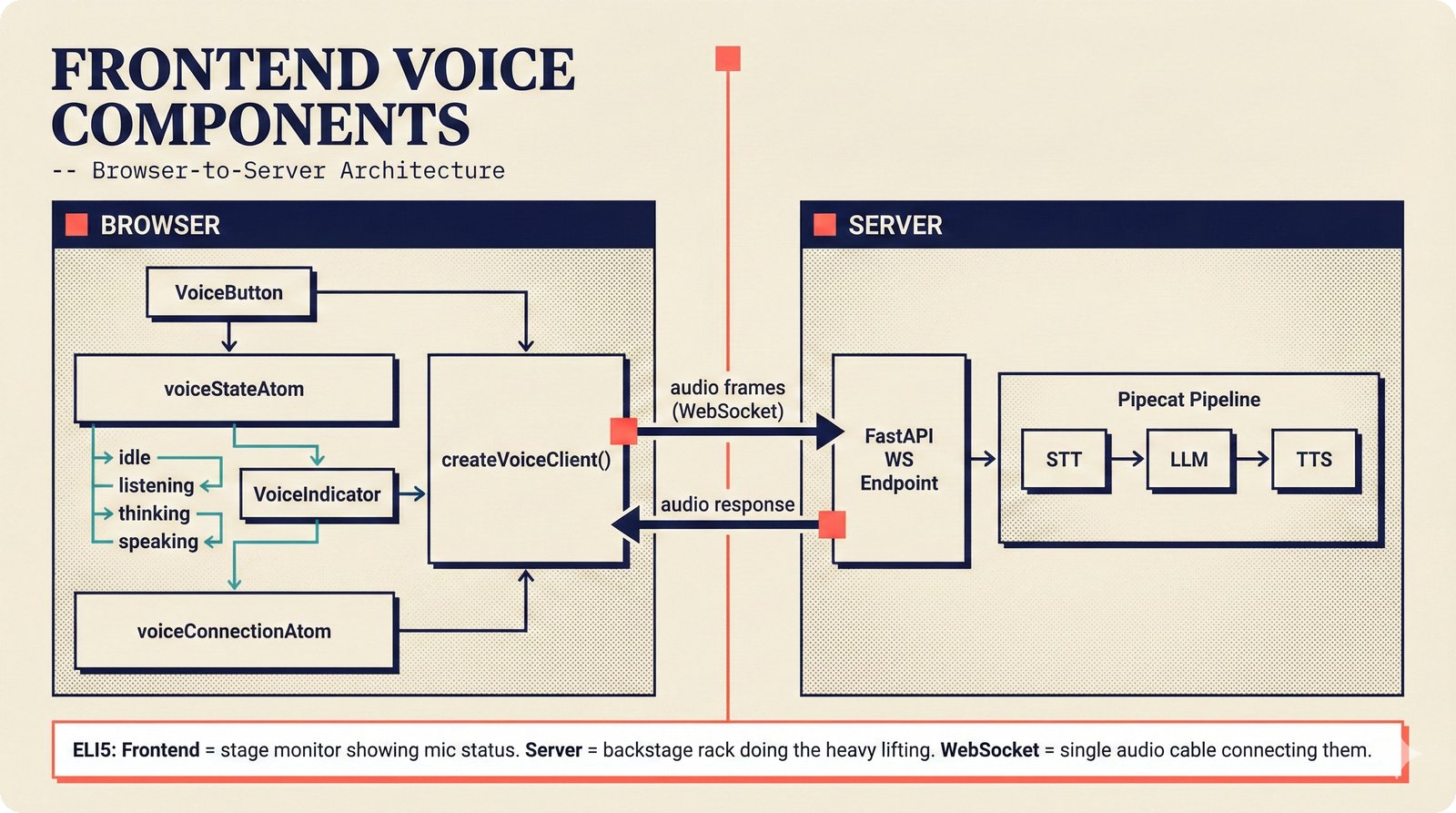 *Frontend voice architecture: Jotai atoms (voiceState, voiceConnection) drive the React UI, with createVoiceClient() managing the WebSocket link to the Pipecat pipeline on the server.* --- 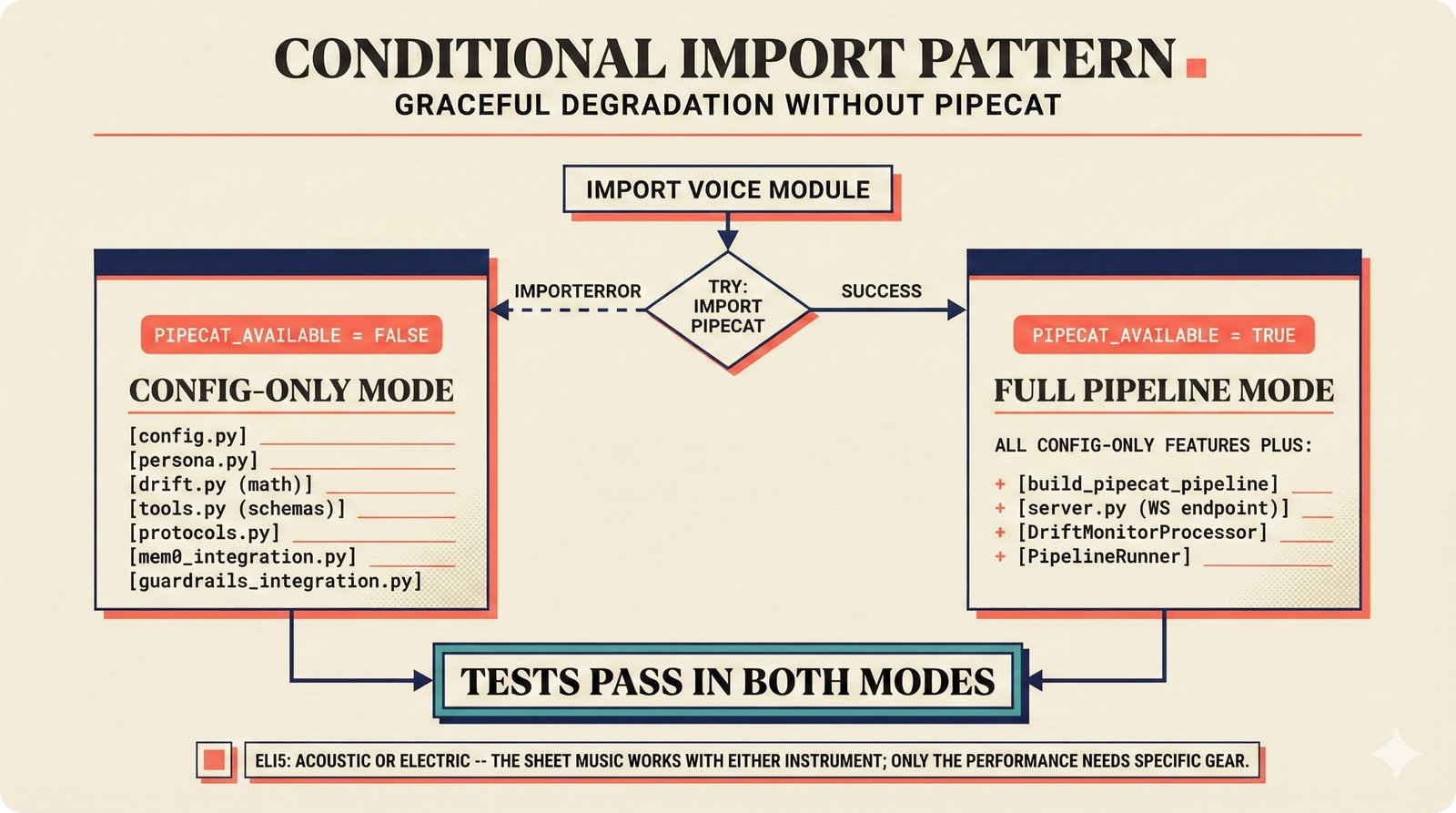 *Conditional import pattern: try/except at module level sets PIPECAT_AVAILABLE, branching to full pipeline mode or config-only mode -- all 54 tests pass in both branches.* ---  *End-to-end voice turn anatomy: 7 processing steps from VAD (4ms) through TTS to transport, with open-source stack at ~799ms and commercial stack at ~389ms against a 500ms target.* --- 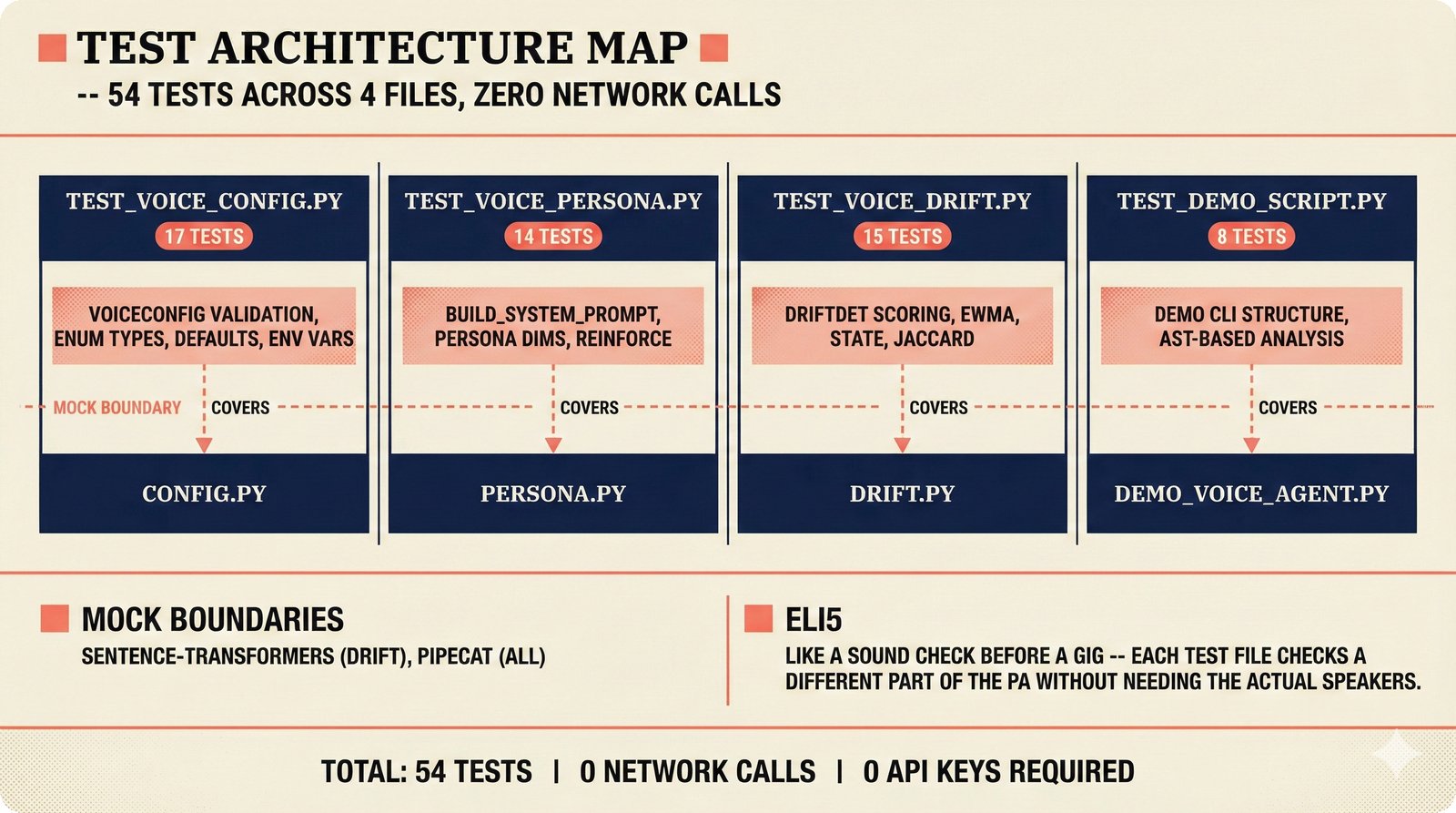 *Test architecture: 54 tests across 4 files covering config validation, persona building, drift detection, and demo script structure, all running without Pipecat via precise mock boundaries.* --- 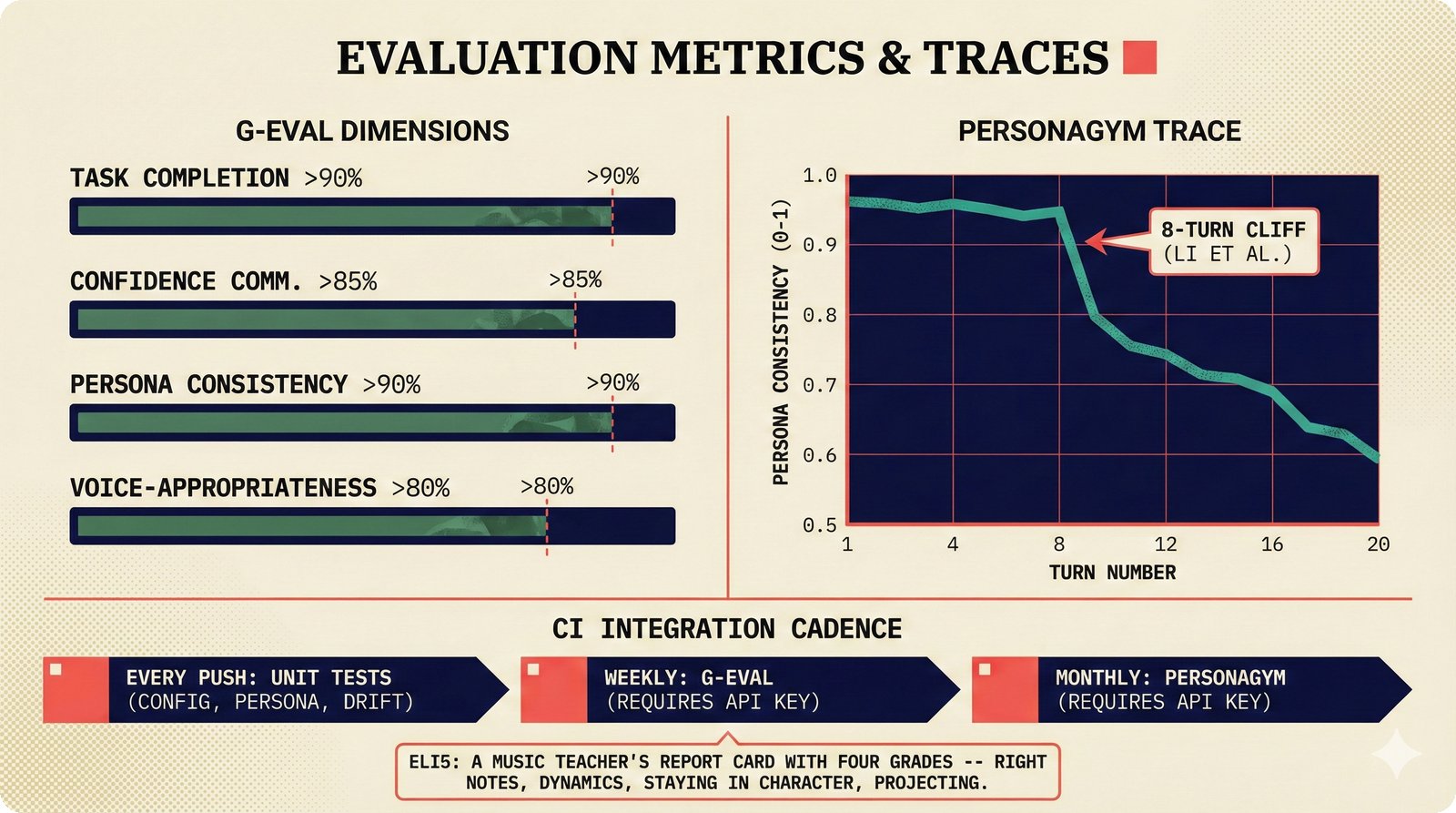 *Evaluation metrics: four G-Eval dimensions with targets (Task >90%, Confidence >85%, Persona >90%, Voice >80%) plus a PersonaGym 20-turn drift trace showing the 8-turn cliff.* --- 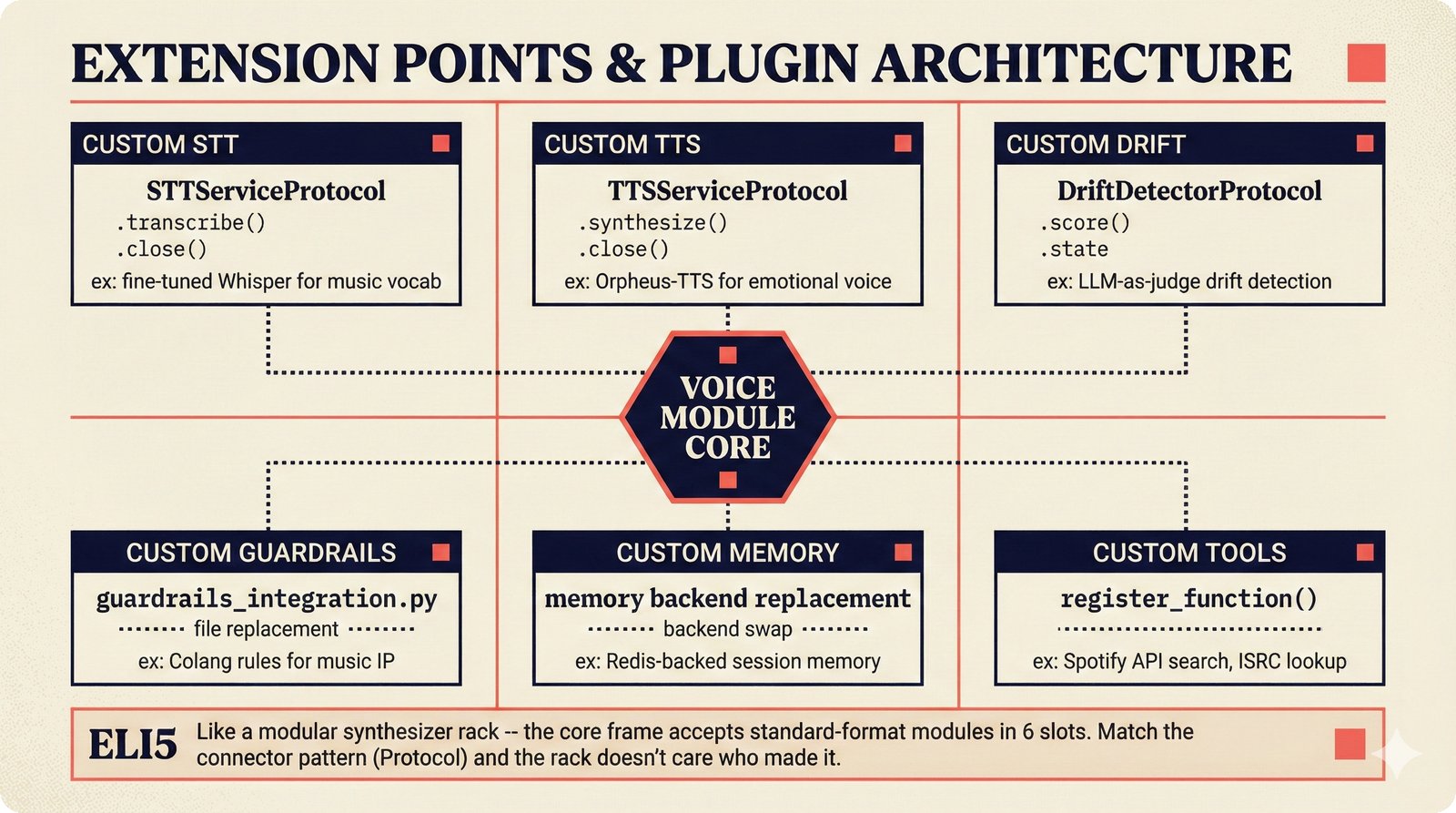 *Six extension points: custom STT, TTS, drift detector, guardrails, memory, and tools -- each defined by a Protocol interface that any implementation can satisfy via structural typing.*Persona Coherence¶
The persona coherence figures cover the engineering of consistent AI agent personalities -- from multi-dimensional persona architecture and mixture-of-experts training through drift detection, memory systems, over-personalization risks, privacy-preserving personalization, evaluation benchmarks, cross-channel synchronization, and the recommended technology stack for maintaining persona consistency across text and voice modalities.