Architecture Overview¶
Five-Pipeline Design¶
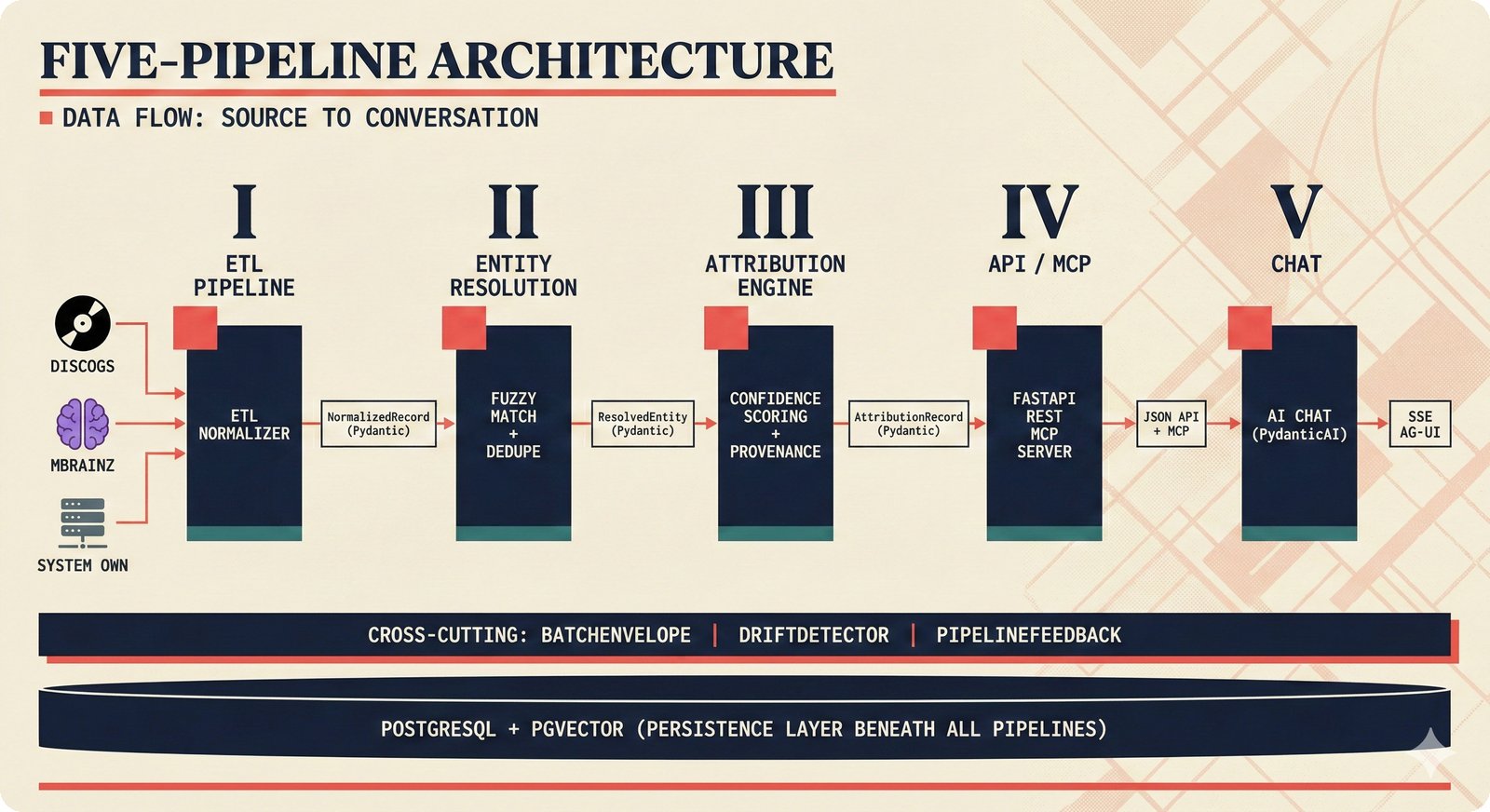
The scaffold is organized as five sequential pipelines, each with clear input/output boundaries defined by Pydantic schemas.
Pipeline 1: ETL (Extract-Transform-Load)¶
Input: Raw data from 5 sources | Output: NormalizedRecord
Extracts music metadata from heterogeneous sources and normalizes into a common schema:
- MusicBrainz — structured metadata (artist credits, ISRCs, release groups)
- Discogs — community-contributed data (personnel, labels, formats)
- AcoustID — acoustic fingerprinting (audio → recording match)
- File Metadata — ID3/Vorbis/MP4 tags via tinytag
- Artist Input — direct artist declarations
Key files: src/music_attribution/etl/
Pipeline 2: Entity Resolution¶
Input: NormalizedRecord[] | Output: ResolvedEntity
Resolves the same entity appearing with different names across sources:
Uses a multi-strategy cascade:
- Identifier Match — exact ISRC/ISWC/ISNI match
- String Similarity — Jaro-Winkler, thefuzz
- Embedding Match — pgvector cosine similarity
- LLM Disambiguation — PydanticAI for ambiguous cases
- Splink Linkage — probabilistic Fellegi-Sunter model
Key files: src/music_attribution/resolution/
Pipeline 3: Attribution Engine¶
Input: ResolvedEntity[] | Output: AttributionRecord
Aggregates evidence from resolved entities into per-field confidence scores:
- Weighted aggregation across sources
- Source agreement scoring — more sources agreeing = higher confidence
- Conformal calibration — distribution-free coverage guarantees
- Priority queue for human review of uncertain attributions
Key files: src/music_attribution/attribution/
Pipeline 4: API / MCP¶
Input: AttributionRecord[] | Output: REST responses, MCP tool results
Serves attribution data through two interfaces:
- REST API (FastAPI) — CRUD for works, search, permissions
- MCP Server — machine-readable permission queries for AI agents
Key files: src/music_attribution/api/, src/music_attribution/mcp/
Pipeline 5: Chat / Agent¶
Input: User queries | Output: Contextual attribution answers
PydanticAI agent with 4 tools, streamed via AG-UI protocol to CopilotKit sidebar:
get_work— retrieve a specific work's attributionsearch_works— keyword search across catalogexplain_confidence— explain why a confidence score is what it ischeck_permission— check AI training permissions
Key files: src/music_attribution/chat/
Cross-Cutting Concerns¶
Three patterns span all pipelines:
| Pattern | Purpose | Schema |
|---|---|---|
| BatchEnvelope | Wrap pipeline stages with metadata (batch_id, timing, counts) | schemas/batch.py |
| DriftDetector | Monitor confidence distributions for unexpected shifts | quality/drift_detector.py |
| PipelineFeedback | User corrections flow back to improve future runs | schemas/pipeline_feedback.py |
Boundary Objects¶
Data flows through three Pydantic schemas that define clean boundaries:
Each schema adds information:
NormalizedRecord— raw field values + source metadataResolvedEntity— resolved identity + match confidenceAttributionRecord— per-field confidence + assurance level + review flag
Database Architecture¶
PostgreSQL with pgvector extension:
- Relational tables — works, contributors, sources, permissions, feedback
- Vector columns — embeddings for semantic similarity search
- Hybrid search — text (tsvector) + semantic (pgvector) with reciprocal rank fusion
Migrations managed by Alembic. ORM via SQLAlchemy 2.0 (async).
PRD Decision Network¶
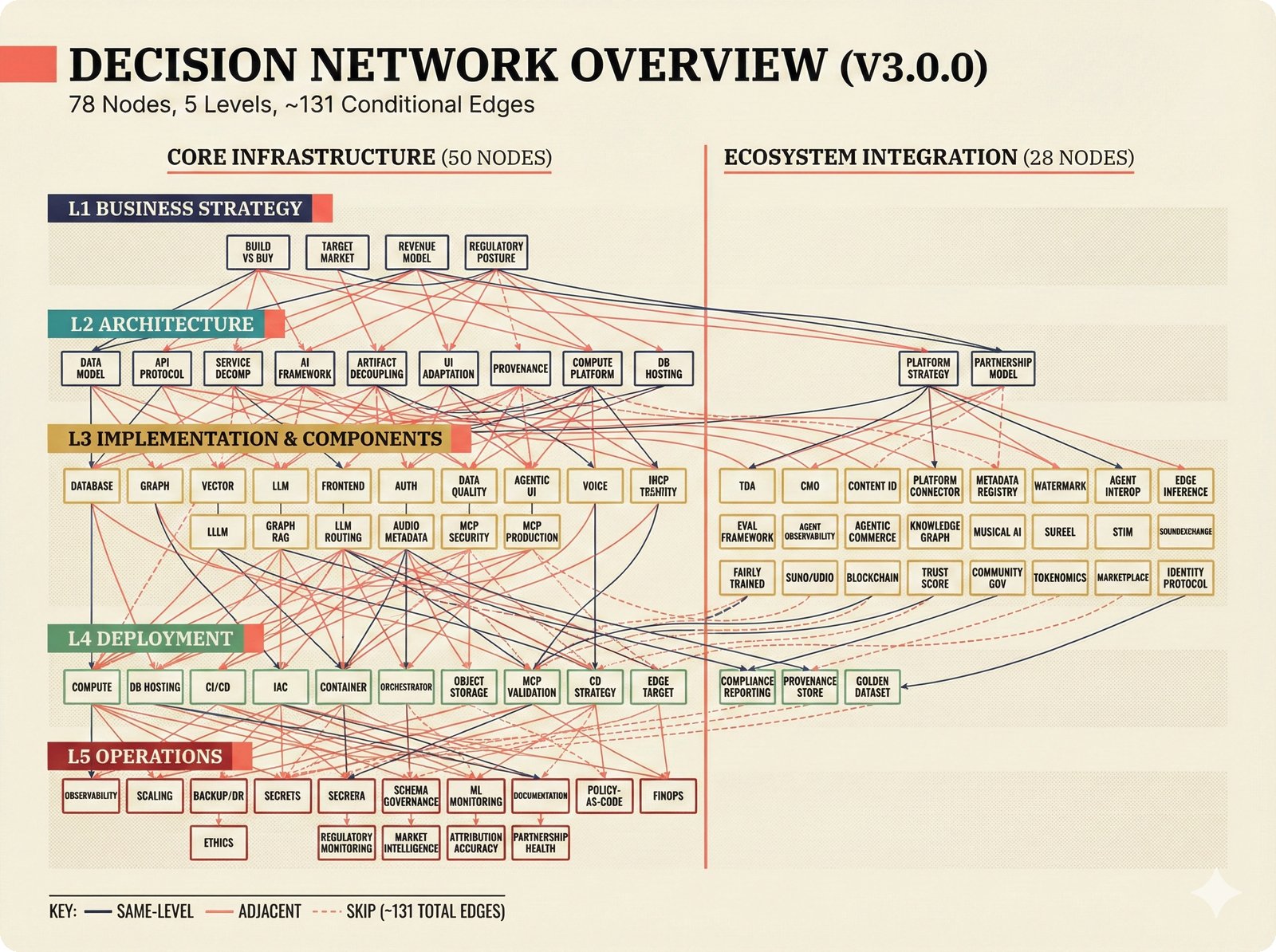
Architecture decisions are captured in a probabilistic PRD with 79 decision nodes across 5 levels. See docs/prd/decisions/REPORT.md for the full network visualization.